scrapy框架爬取糗妹妹网站妹子图分类的所有图片
爬取所有图片,一个页面的图片建一个文件夹。难点,图片中有不少.gif图片,需要重写下载规则,
创建scrapy项目
scrapy startproject qiumeimei
创建爬虫应用
cd qiumeimei scrapy genspider -t crawl qmm www.xxx.com
items.py文件中定义下载字段
import scrapy class QiumeimeiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
page = scrapy.Field()
image_url = scrapy.Field()
qmm.py文件中写爬虫主程序
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from qiumeimei.items import QiumeimeiItem class QmmSpider(CrawlSpider):
name = 'qmm'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.qiumeimei.com/image'] rules = (
Rule(LinkExtractor(allow=r'http://www.qiumeimei.com/image/page/\d+'), callback='parse_item', follow=True),
) def parse_item(self, response):
page = response.url.split('/')[-1]
if not page.isdigit():
page = ''
image_urls = response.xpath('//div[@class="main"]/p/img/@data-lazy-src').extract()
for image_url in image_urls:
item = QiumeimeiItem()
item['image_url'] = image_url
item['page'] = page
yield item
pipelines.py文件中定义下载规则
import scrapy
import os
from scrapy.utils.misc import md5sum
# 导入scrapy 框架里的 管道文件的里的图像 图像处理的专用管道文件
from scrapy.pipelines.images import ImagesPipeline
# 导入图片路径名称
from qiumeimei.settings import IMAGES_STORE as images_store
# 必须继承 ImagesPipeline
class QiumeimeiPipeline(ImagesPipeline):
# 定义返回文件名
def file_path(self, request, response=None, info=None):
file_name = request.url.split('/')[-1]
return file_name
# 重写父类的 下载文件的 方法
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['image_url'])
# 完成图片存储的方法 名称
def item_completed(self, results, item, info):
# print(results)
page = item['page']
print('正在下载第'+page+'页图片')
image_url = item['image_url']
image_name = image_url.split('/')[-1]
old_name_list = [x['path'] for t, x in results if t]
# 真正的原图片的存储路径
old_name = images_store + old_name_list[0]
image_path = images_store + page + "/"
# 判断图片存放的目录是否存在
if not os.path.exists(image_path):
# 根据当前页码创建对应的目录
os.mkdir(image_path)
# 新名称
new_name = image_path + image_name
# 重命名
os.rename(old_name, new_name)
return item
# 重写下载规则
def image_downloaded(self, response, request, info):
checksum = None
for path, image, buf in self.get_images(response, request, info):
if checksum is None:
buf.seek(0)
checksum = md5sum(buf)
width, height = image.size
if self.check_gif(image):
self.persist_gif(path, response.body, info)
else:
self.store.persist_file(
path, buf, info,
meta={'width': width, 'height': height},
headers={'Content-Type': 'image/jpeg'})
return checksum def check_gif(self, image):
if image.format is None:
return True def persist_gif(self, key, data, info):
root, ext = os.path.splitext(key)
absolute_path = self.store._get_filesystem_path(key)
self.store._mkdir(os.path.dirname(absolute_path), info)
f = open(absolute_path, 'wb') # use 'b' to write binary data.
f.write(data)
settings.py文件中定义请求头和打开下载管道
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
ITEM_PIPELINES = {
'qiumeimei.pipelines.QiumeimeiPipeline': 300,
}
运行爬虫
scrapy crawl qmm --nolog
查看文件夹是否下载成功
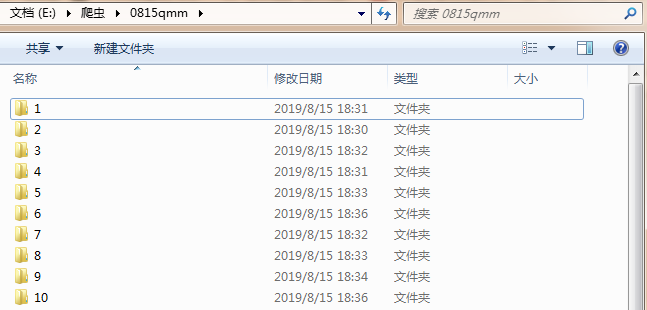
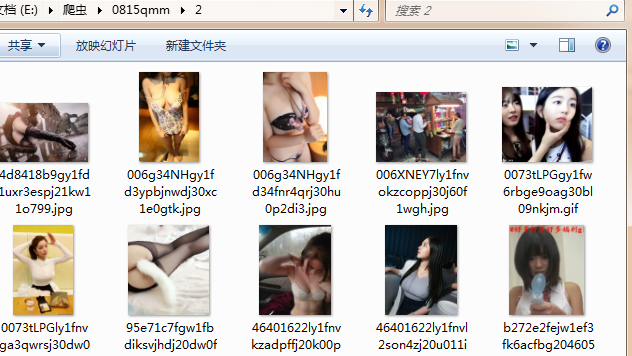

.gif为动态图。
done。

scrapy框架爬取糗妹妹网站妹子图分类的所有图片的更多相关文章
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- (java)selenium webdriver爬虫学习--爬取阿里指数网站的每个分类的top50 相关数据;
主题:java 爬虫--爬取'阿里指数'网站的每个分类的top50 相关数据: 网站网址为:http://index.1688.com/alizs/top.htm?curType=offer& ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
随机推荐
- Android最新版本号与API级别对应关系
Android版本号与API级别对应关系表 名称 版本号 API等级 发布时间 BuildVersion 2012-11-01 BuildVersionCodes.JellyBeanMr1 Jell ...
- [UE4] Adding a custom shading model
转自:https://blog.felixkate.net/2016/05/22/adding-a-custom-shading-model-1/ This was written in Februa ...
- Laradock中文文档
文档地址:https://laradock.linganmin.cn
- mysql8.0 grant 创建账号及权限记录
针对 42000错误 原文:https://stackoverflow.com/questions/50177216/how-to-grant-all-privileges-to-root-user- ...
- PHP Imagick文字加阴影(外发光)
PHP Imagick文字加阴影(外发光)<pre>$canvas = new \Imagick(); $canvas->newImage(500, 200, 'white'); $ ...
- vps建站施工预告
作为一个小白,最近几天自己用vps搭了个站点,用来发发博客,偶尔还可以去外面看看.后面几章就来记一下过程吧! 结构极为简单,建站用的WordPress,目前也就只有最基础的发文章功能.不过由于习惯了m ...
- 第2课,python while循环的使用
引言: 上次课学习了python turtle库的基本使用,向前向后和转向.本次课需要画多个图形,简单的东西多起来就变得不简单了. 0/1是简单的,但却能组成丰富多彩的多媒体世界. 课程内容: 1. ...
- [终极巨坑]golang+vue开发日记【二】,登陆界面制作(一)
写在前面 本期内容是适合第一次使用vue或者golang开发的,内容会以实战的形式来讲解.看懂本段内容需要了解基础内容有html,css,最好可以看一下vue的基础.并且这里的每个知识点不可能详细解说 ...
- 【基本知识】UART接口
1.简介 (1)UART一种通用异步串口数据总线,最低采用两路信号(TX/RX)即可实现全双工通信,十分简单: (2)UART采用LSB模式传输,串口数据传输格式如下图所示: 起始位:长度为1位的时间 ...
- python 递归-汉诺塔
# 汉诺塔 a = "A" b = "B" c = "C" def hano(a, b, c, n): if n == 1: print(& ...