python爬虫——数据爬取和具体解析
关于正则表达式的更多用法,可参考链接:https://blog.csdn.net/weixin_40040404/article/details/81027081
一、正则表达式:
1.常用正则匹配:
URL:^https?://[a-zA-Z0-9\.\?=&]*$ (re.S模式,匹配 https://www.baidu.com 类似URL )
常用Email地址:[0-9a-zA-Z_-]+@[0-9a-zA-Z_-]+\.[0-9a-zA-Z_-]+ 或者 [\w-]+@[\w-]+\.[\w-]+
中文字符匹配:[\u4e00-\u9fa5]+ 或者 [^\x00-\xff]+
QQ号:[1-9][0-9]{4,} ({4,}表示[0-9]的数字个数不低于4个)
ID:^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$
2.特殊组合:
([\s\S]*?) == ([.\n]*?) == re.findall(‘.*?‘, re.S)
万能正则表达式 (加‘?’表示懒惰模式,尽可能最小长度匹配; 不加‘?’表示贪婪模式,尽可能最大长度匹配)
\s\S : 空白字符+非空白字符,即表示所有字符 all, == ’ .\n ‘(.表示除换行符之外的任意字符,\n表示换行符)
re.S: 即DOTAALL 点匹配任意模式,改变.的行为,可以匹配换行符
二、例子
获取博客园的其中一篇文章的内容,保存至文档中。(具体解析在代码注释中可见)
1.源代码
import requests
import re
import json def request_blog(url):
# 异常处理代码块
try:
#同步请求
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None def parse_result(html):
# re正则表达式,re.compile是对匹配符的封装,直接用re.match(匹配符,要匹配的原文本)可以达到相同的效果,
# 当然,这里没有用re.match来执行匹配,而是用了re.findall,这是因为后者可以适用于多行文本的匹配。
# 另外,re.compile后面的第2个参数,re.S是用来应对换行的,.匹配的单个字符不包括\n和\r,当遇到换行时,我们需要用到re.S # 获取网页中的<p>标签中的内容,遇到换行符时,自动跳出循环
# 格式:标签加.*?,.*?表示取标签中的所有数据
pattern = re.compile('<p>.*?</p>',re.S)
items = re.findall(pattern, html)
return items def write_item_to_file(item):
print('写入数据:' + str(item))
# 保存的文件名blog.txt,写入文件的格式a追加,写入文件的中文格式化UTF-8
with open('blog.txt', 'a', encoding='UTF-8') as f:
# 遇到换行符时,自动换行
f.write(json.dumps(item, ensure_ascii=False) + '\n') def main(page):
# 网址
url = 'https://www.cnblogs.com/chenting123456789/p/11840740.html' + str(page)
# 调用获取网页数据的函数
html = request_blog(url)
# 调用解析已获取的网页数据的函数
items = parse_result(html)
# 循环写入文件
for item in items:
write_item_to_file(item) if __name__ == "__main__":
for i in range(1,5):
main(i)
2.运行结果

3.原文文章截图

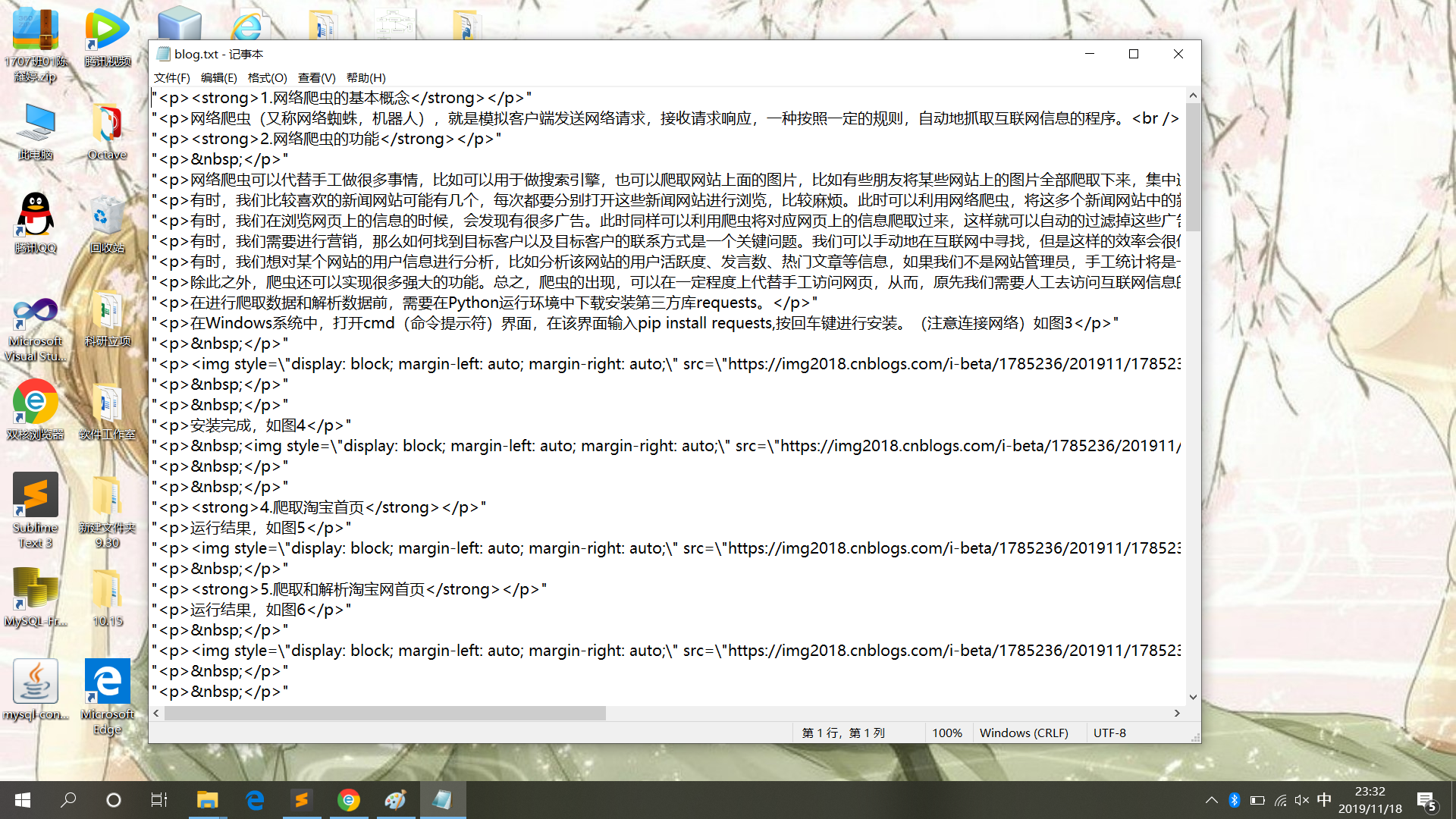
4.写入文件内容
三、小结
强化爬虫爬取网页信息的技术,以及解析数据时的逻辑顺序。
python爬虫——数据爬取和具体解析的更多相关文章
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- python爬虫25 | 爬取下来的数据怎么保存? CSV 了解一下
大家好 我是小帅b 是一个练习时长两年半的练习生 喜欢 唱! 跳! rap! 篮球! 敲代码! 装逼! 不好意思 我又走错片场了 接下来的几篇文章 小帅b将告诉你 如何将你爬取到的数据保存下来 有文本 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
随机推荐
- javassist标识符
符号 含义 $0, $1, $2, ... this and 方法的参数 $args 方法参数数组.它的类型为 Object[] $$ 所有实参.例如, m($$) 等价于 m($1,$2,...) ...
- SQL server 常见错误--登录连接失败和附加数据库失败
问题1:数据库软件登录连接不了,因为SQL server有部分服务没有开启,需要手动开启. 解决:计算机管理-->服务-->开启SQL server服务(具体那个自己慢慢试,就 ...
- Python生成流水线《无限拍卖》文字!
话说,原文也是这样流水线生产的吧··· 代码 import random one_char_word=["烈","焰","冰"," ...
- DevExtreme学习笔记(一)treeView(搜索固定、节点展开和收缩)注意事项
var treeConfig1 = dxConfig.treeView(obj_Question.treeDataSource1); treeConfig1.selectionMode = 'sing ...
- DevExtreme学习笔记(一) DataGrid中数据筛选
config.filterRow = { visible: true, applyFilter: "auto" }; config.headerFilter = { visible ...
- C# 使用代理实现方法过滤
一.为什么要进行方法过滤 一些情况下我们需要再方法调用前记录方法的调用时间和使用的参数,再调用后需要记录方法的结束时间和返回结果,当方法出现异常的时候,需要记录异常的堆栈和原因,这些都是与业务无关的代 ...
- WIN7U X64环境下的SQL SERVER 2008R2的防火墙配置
测试需要,备忘. CMD下运行,可以把sql server 要用的端口都开好. netsh advfirewall firewall add rule name = SQLPort dir = in ...
- Go strconv模块:字符串和基本数据类型之间转换
本文转自Golove博客:http://www.cnblogs.com/golove/p/3262925.html ParseBool 将字符串转换为布尔值 // 它接受真值:1, t, T, TRU ...
- mac添加oh my zsh
Mac 终端 oh-my-zsh 配置 Mac 终端默认 shell 为 bash.zsh 可能是目前最好的 shell ,至于好在哪里可自行百度.本文主要介绍使用 zsh 以及 oh-my-zs ...
- 使用protobuf (proto3, C++和go语言)
在这里,我先讲述C++使用protobuf,之后,会补充使用go语言使用protobuf. 使用protobuf需要有如下步骤: 在.proto文件中定义消息(message)格式. 使用protob ...