python爬取豆瓣小组700+话题加回复啦啦啦python open file with a variable name
需求:爬取豆瓣小组所有话题(话题title,内容,作者,发布时间),及回复(最佳回复,普通回复,回复_回复,翻页回复,0回复)

解决:1. 先爬取小组下,所有的主题链接,通过定位nextpage翻页获取总过700+条话题;
2. 访问700+ 链接,在内页+start=0中,获取话题相关的四部分(话题title,内容,作者,发布时间),及最佳回复、回复;
3. 在2的基础上,判断是否有回复,如果有回复才进一步判断是否有回复翻页,回复翻页通过nextpage 获取start=100、start=200的页;
4. 进入下一个爬取函数,将抓取的回复 续写 到2 中的文件;
解决思路:
Before:一开始建立2个文件,article.txt 用来存储所有话题相关的内容(700+话题、作者信息);
同时,建立以title命名的回复文件;
After: 统一建立以话题title命名的文章,先写入文章相关内容,再续写回复;这样方便读取;
遇到的坑:
1. 要获取某个div下直接的text,div.span下的text,div.h下的text:
——有2个解决方法:
A. 通过xpath //text,意思是获取div 下的所有text文件;

B. 通过css 拼接,逗号隔开即可:
2. 巩固了不同函数之间通过meta传递参数的方法:

3. python open file with a variable name
f = open('%s.txt' % title_end,'a')
a: 续写

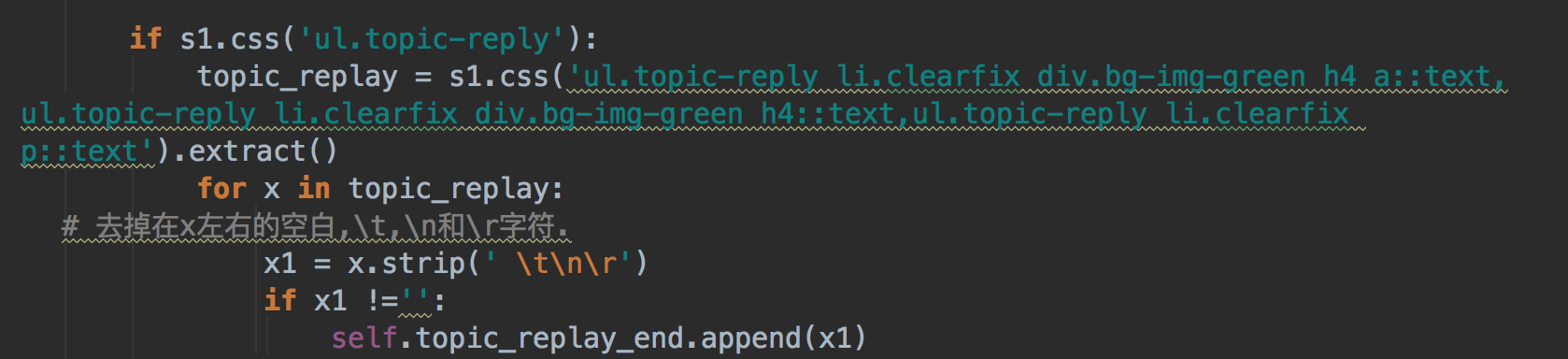
4.去掉 str 中的空格,换行等符号
# 去掉在x左右的空白,\t,\n和\r字符.
x1 = x.strip(' \t\n\r')
5 . strip 去掉数据中的\r,''.join 将列表转回字符串;
# 先将文章中的\r 都去掉,有些单独的'\r' 就变成了空的列表元素:'',再用if 来判断下就好了
artical_end = []
for x in article:
x1 = x.replace('\r','')
if x1 != '':
artical_end.append(x1)
# 将artical_end 列表 转为字符串
ar =''.join(artical_end)
python爬取豆瓣小组700+话题加回复啦啦啦python open file with a variable name的更多相关文章
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python 爬取单个网页所需要加载的地址和CSS、JS文件地址
Python 爬取单个网页所需要加载的URL地址和CSS.JS文件地址 通过学习Python爬虫,知道根据正式表达式匹配查找到所需要的内容(标题.图片.文章等等).而我从测试的角度去使用Python爬 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
随机推荐
- linux CentOS中创建用户 无密码登录
首先点击左上角的 “应用程序” -> “系统工具” -> “终端”,首先在终端中输入 su ,按回车,输入 root 密码以 root 用户登录,接着执行命令创建新用户 hadoop: 接 ...
- java用户角色权限设计
实现业务系统中的用户权限管理 B/S系统中的权限比C/S中的更显的重要,C/S系统因为具有特殊的客户端,所以访问用户的权限检测可以通过客户端实现或通过客户端+服务器检测实现,而B/S中,浏览器是每一台 ...
- UVaLive 6680 Join the Conversation (DP)
题意:给出n条发言,让你求最大的交流长度并输出标记顺序. 析:这个题要知道的是,前面的人是不能at后面的人,只能由后面的人at前面的,那就简单了,我们只要更新每一层的最大值就好,并不会影响到其他层. ...
- 思维题 HDOJ 5288 OO’s Sequence
题目传送门 /* 定义两个数组,l[i]和r[i]表示第i个数左侧右侧接近它且值是a[i]因子的位置, 第i个数被选择后贡献的值是(r[i]-i)*(i-l[i]),每个数都枚举它的因子,更新l[i] ...
- js复制功能
// 复制功能 copyUrl() { var Url = document.getElementById('biao') Url.select() // 选择对象 document.execComm ...
- 转 MySQL数据库基础
http://lib.csdn.net/article/mysql/57883 1 数据库基础 一.数据库与数据库管理系统 1.数据库(DB):存放数据的仓库,从广义来说,数据不仅包括数字,还包括了文 ...
- jmeter生成时间的函数
在一个接口测试中,需要提交的请求中要带时间,在看完jmeter帮忙文档,正好总结一下 1.需求 在一个http请求中请求数据要带有时间,如下: 2.实现 突然想到jmeter自带的函数助手好像是可以实 ...
- uiautomatorviewer详解
一,uiautomatorviewer是什么? Android 4.1发布的,uiautomator是用来做UI测试的.也就是普通的手工测试,点击每个控件元素 看看输出的结果是否符合预期.比如 登陆界 ...
- js解析地址栏参数
/** * 获取地址栏中url后面拼接的参数 * eg: * 浏览器地址栏中的地址:http://1.1.1.1/test.html?owner=2db08226-e2fa-426c-91a1-66e ...
- Java多线程——线程之间的同步
Java多线程——线程之间的同步 摘要:本文主要学习多线程之间是如何同步的,如何使用volatile关键字,如何使用synchronized修饰的同步代码块和同步方法解决线程安全问题. 部分内容来自以 ...