利用python进行数据分析之数据加载存储与文件格式
在开始学习之前,我们需要安装pandas模块。由于我安装的python的版本是2.7,故我们在https://pypi.python.org/pypi/pandas/0.16.2/#downloads 此网站上下载的0.16.2版本,下载后解压缩利用dos命令打开对应的文件下,并运行 python setup.py install安装,可能会出现报错:error: Microsoft Visual C++ 9.0 is required (Unable to find vcvarsall.bat). Get it from http://aka.ms/vcpython27,此刻转到http://www.microsoft.com/en-us/download/confirmation.aspx?id=44266,会自动下载Microsoft Visual C++ Compiler for Python 2.7,下载后安装。然后再运行python setup.py install,就可以正常安装了,安装过程在30s左右即可完成。安装成功后可在idle窗口中
import pandas
查看是否引用成功,成功后就可以开始下一步学习。
输入输出数据通常分为几个大类,读取文本文件和其他更高效的磁盘存储格式,加载数据库中数据,也可以利用web的API操作网络数据资源。
一、读取文本格式数据
pandas提供一些将表格数据读取为dataframe对象的函数。
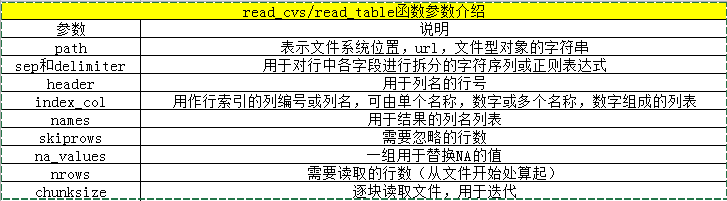
| read_csv | 从文件,url,文件型对象中加载带分隔符的数据,默认分隔符为逗号。 |
| read_table | 从文件,url,文件型对象中加载带分隔符的数据,默认分隔符为制表符('\t')。 |
| read_fwf | 读取定宽格式的数据,无分隔符 |
| read_clipboard | 读取剪贴板中数据 |
read_csv会为数据分配默认的列名,也可以指定数据的列名如:pd.read_csv('ch06/ex2/csv',names=['a','b','c','d','message'])
假设你希望将message列作为dataframe的索引,可以通过index_col参数指定message:
names=['a','b','c','d','message']
pd.read_csv('ch06/ex2/csv',names=names,index_col='message')
将数据写出到文本格式
1、利用data_frame的to_csv方法,可以将数据写到一个以逗号分隔的文件中,也可用sep参数指定分隔符,如 data.to_csv()
2、缺失值写入输出时会被表示为空字符串,可使用na_rep表示为别的标记值。
手工处理分隔符格式
对于任何单字符分隔符文件,可以直接使用python内置的csv模块,将任意打开的文件或文件型的对象传给csv.reader:
import csv
f=open('ch06/ex7.csv')
reader=csv.reader(f)
对这个reader迭代将会为每行产生一个列表,为了使数据合乎需求,需要进行一些手工整理:
lines=list(csv.reader(open('ch06\ex7.csv')))
header,values=lines[0],lines[1:]
data_dict={h:v for h,v in zip(header,zip(*values))}
csv的文件的形式有很多,只需定义csv.dialect的一个子类即可定义出新格式:
class my_dialect(csv.Dialect):
lineterminator='\n'
delimiter=';'
quotechar='"'
reader=csv.reader(f,dialect=my_dialect)
二、JSON数据
JSON数据已经成为通过http请求在wed浏览器和其他应用程序之间发送数据的标准格式之一,它是一种比表格型文本格式更灵活的数据格式。
JSON非常接近于有效的python代码,基本类型都有对象,数组,字符串,数值,布尔型以及null。通过json.loads即可将JSON字符串转换为python形式。
import json
result=json.loads(obj)
json.dump则将python对象转换为JSON格式
三、XML和HML:WEB信息收集
lxml可以高效可靠的解析大文件,lxml有多个编程接口,首先我们用lxml.html处理HTML,然后再用lxml.objectify做一些XML处理。
(待续)
四、二进制数据格式
实现二进制数据格式存储最简单的方法之一是使用python内置的pickle序列化,pandas对象都有一个用于将数据以pickle形式保存到磁盘上的save方法,然后可用pickle函数pandas.load将数据读回python:
frame=pd.read_csv('ch06/ec1.csv')
frame.save('ch06/frame_pickle')
frame.load('ch06/frame_pickle')
使用HDF5格式
HDF5中指的是层次型数据格式,每个HDF5文件都含有一个文件系统式的节点结构,它使你可以储存多个数据集并支持元数据。HDF5支持多种压缩器的即时压缩。
python中有两个接口处理HDF5,pytable和h5py。
读取excel文件
pandas的excelfile类支持读取存储excel中的表格型数据,由于excelfile用到了xlrd和openpyxl包,所以得先安装它们(https://pypi.python.org/pypi/xlrd),通过传入一个xls或xslx文件的路径即可创建一个excelfile实例,存放在某个工作表中的数据可以通过parse读取到dataframe中。
xls_file=pd.ExcelFile('data.xls')
table=xls_file.parse('Sheet1')
五、使用HTML和WEB API
许多网站都有一些通过JSON或其他格式提供数据的公用API,通过python访问这些API简单推荐的方法是requests包,如下:
网页信息读取后可进行更高级一步的处理。
import requests
url='http://www.baidu.com'
resp=requests.get(url)
resp
import json
data=json.loads(resp.text)
六、使用数据库
具体应用中,数据很少取自文本数据,更多来源与数据库(包括关系型数据库与非关系型数据库)
利用python进行数据分析之数据加载存储与文件格式的更多相关文章
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- python数据分析笔记——数据加载与整理]
[ python数据分析笔记——数据加载与整理] https://mp.weixin.qq.com/s?__biz=MjM5MDM3Nzg0NA==&mid=2651588899&id ...
- 利用python进行数据分析之数据规整化
数据分析和建模大部分时间都用在数据准备上,数据的准备过程包括:加载,清理,转换与重塑. 合并数据集 pandas对象中的数据可以通过一些内置方法来进行合并: pandas.merge可根据一个或多个键 ...
- 利用python进行数据分析之数据聚合和分组运算
对数据集进行分组并对各分组应用函数是数据分析中的重要环节. group by技术 pandas对象中的数据会根据你所提供的一个或多个键被拆分为多组,拆分操作是在对象的特定轴上执行的,然后将一个函数应用 ...
- 利用Python进行数据分析_Pandas_数据清理、转换、合并、重塑
1 合并数据集 pandas.merge pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, le ...
- python学习笔记3_数据载入、存储及文件格式
一.丛mysql数据库中读取数据 import pandas as pdimport pymysqlconn = pymysql.connect( host = '***', user = '***' ...
- 《利用Python进行数据分析: Python for Data Analysis 》学习随笔
NoteBook of <Data Analysis with Python> 3.IPython基础 Tab自动补齐 变量名 变量方法 路径 解释 ?解释, ??显示函数源码 ?搜索命名 ...
- 利用python进行数据加载和存储
1.文本文件 (1)pd.read_csv加载分隔符为逗号的数据:pd.read_table从文件.URL.文件型对象中加载带分隔符的数据.默认为制表符.(加载为DataFrame结构) 参数name ...
- python多种格式数据加载、处理与存储
多种格式数据加载.处理与存储 实际的场景中,我们会在不同的地方遇到各种不同的数据格式(比如大家熟悉的csv与txt,比如网页HTML格式,比如XML格式),我们来一起看看python如何和这些格式的数 ...
随机推荐
- ER图与UML图
ER图:实体-联系图(Entity-Relation Diagram)用来建立数据模型,在数据库系统概论中属于概念设计阶段,ER图提供了表示实体(即数据对象).属性和联系的方法,用来描述现实世界的概念 ...
- Android 根据EditText搜索框ListView动态显示数据
根据EditText搜索框ListView动态显示数据是根据需求来的,觉得这之中涉及的东西可能比较的有意思,所以动手来写一写,希望对大家有点帮助. 首先,我们来分析下整个过程: 1.建立一个layou ...
- CentOS 修改默认语言
查看所有的locale语言 [root@centos6 ~]# locale -a ... ... ... ... xh_ZA xh_ZA.iso88591 xh_ZA.utf8 yi_US yi_U ...
- Neo4j简介
Neo4j简介 发表于2013年3月16日 11:52 p.m. 位于分类图数据库与图并行计算 现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS ...
- dubbo+zookeeper+spring+springMVC+mybatis的使用
读前声明:由于本人水平有限,有错误或者描述不恰当的地方请指出来,勿喷!第一次写博客. 源码下载链接:http://files.cnblogs.com/files/la-tiao-jun-blog/du ...
- C++ Primer 读书笔记: 第8章 标准IO库
第8章 标准IO库 8.1 面向对象的标准库 1. IO类型在三个独立的头文件中定义:iostream定义读写控制窗口的类型,fstream定义读写已命名文件的类型,而sstream所定义的类型则用于 ...
- QF——iOS第三方登录和社会化分享
QQ登录的流程: 1.下载SDK,并添加到项目中: 2.添加SDK需要的依赖库,以及配置文件: 3.重写APPDelegate的方法handleOpenURL和openURL: 4.实现Tencent ...
- OC语法10——@protocol协议,
参考资料:博客 @protocol,协议: OC中protocol的含义和Java中接口的含义是一样的,它们的作用都是为了定义一组方法规范. 实现此协议的类里的方法,必须按照此协议里定义的方法规范来. ...
- Android Material Design调色板
转: http://www.stormzhang.com/design/2014/12/26/material-design-palette/ Material Design出来一段时间了,身为And ...
- VI 配置文件(略全)
配置 ~/.vimrc文件. root则放到/etc/vimrc 具体详见代码 "====================================================== ...