利用Python进行数据分析_Pandas_数据清理、转换、合并、重塑
1 合并数据集
pandas.merge
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
import pandas as pd
from pandas import DataFrame
df1 = DataFrame({'key':['b','b','a','c','a','a','b'],'data1':range(7)})
df2 = DataFrame({'key':['a','b','d','b'],'data2':range(4)})
# pd.merge(df1,df2,on='key')#设定列进行连接
# pd.merge(df1,df2,left_on='data1',right_on='data2')
# pd.merge(df1,df2,how='outer')#外连接,求取的是键的并集
# pd.merge(df1,df2,on='key',how='left')#左连接
# pd.merge(df1,df2,on='key',how='right')#右连接
# pd.merge(df1,df2,on='key',how='inner')#内连接,求取的是键的交集
# pd.merge(df1,df2,left_index=True,right_index=True)#索引被用作连接键
merge函数的参数

轴向连接
pandas.concat
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
其中axis=0表示行,axis=1表示列
Series
s1 = Series([0,1],index=['a','b'])
s2 = Series([2,3,4],index=['c','d','e'])
s3 = Series([5,6],index=['f','g'])
s4 = pd.concat([s1*5,s3])#concat默认axis=0,所以得出的是新的Series,取并集;axis=1,所以得出的是新的DataFrame # pd.concat([s1,s4],axis=1,sort=False,join='outer')#axis=1 表示针对列,join='outer'表示取并集
# pd.concat([s1,s4],axis=1,sort=False,join='inner')#axis=1 表示针对列,join='inner'表示取交集
# pd.concat([s1,s4],axis=1,sort=False,join_axes=[['a','c','b','e']])#指定索引 # result = pd.concat([s1,s2,s3],keys=['one','two','three'])
result = pd.concat([s1,s2,s3],axis=1,sort=False,keys=['one','two','three'])
DataFrame
类似,略。
合并重叠数据
combine_first()方法
s1.combine_first(s2)
df1.combine_first(df2)
2 重塑和轴向旋转
reshape
pivot
重塑层次化索引
stack:将数据的“列”旋转为“行”
unstack:将数据的“行”旋转为“列”
3 数据转换
移除重复数据
import pandas as pd
from pandas import DataFrame,Series
s1 = Series(['a','a','a'],index=['i1','i2','i3'])
s2 = Series(['a','a','a'],index=['i1','i2','i3'])
df = pd.concat([s1,s2],axis=1,sort=False)
df
运行结果:

df.duplicated()#返回一个布尔类型的Series
运行结果:

df.drop_duplicates()#移除全部列重复行的数据,默认保留第一个出现的值
df.drop_duplicates(take = True)#移除全部列重复行的数据,默认保留最后一个值
运行结果:

import pandas as pd
from pandas import DataFrame,Series
s1 = Series(['a','a','a'],index=['i1','i2','i3'])
s2 = Series(['a','b','a'],index=['i1','i2','i3'])
df = pd.concat([s1,s2],axis=1,sort=False,keys=['key1','key2'])
df.drop_duplicates('key2')
运行结果:

df.drop_duplicates('key2')#移除指定列重复行的数据
运行结果:
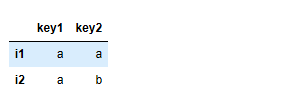
利用函数或映射进行数据转换
import pandas as pd
from pandas import DataFrame,Series
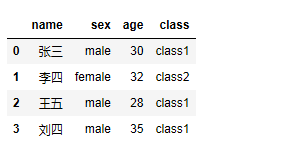
data = DataFrame({'name':['张三','李四','王五','刘四'],'sex':['male','female','male','male'],'age':[30,32,28,35]})
student_to_class = {#比如,男性的班级是class1,女性的班级是class2
'male':'class1',
'female':'class2'
}
data['class'] = data['sex'].map(person_to_class)
data
运行结果:
替换值
fillna()
map(参数),可以接收一个函数或含有映射关系的字典型对象
replace(参数1,参数2),参数1表示被替换的值,可以是一个值,也可以是多个值,参数2表示替换值
轴索引重命名
DataFrame 有map函数,DataFrame的index也有个map函数
df.index.map()
离散化和面元划分
pd.cut()
开区间、闭区间,通过right=False或True,left=False或True 进行控制
统计市盈率区间分布情况:
import pandas as pd
import numpy as np
from numpy import array
file = 'D:\全部A股-行情报价.xls'
df = pd.read_excel(file)
region = [-100,-50,-30,-20,-10,0,10,20,30,50,100]
regions = np.array(region)
ratio = df['市净率'].dropna()
arrs = np.array(ratio)
ratios = pd.cut(ratio,regions)
pd.value_counts(ratios)

提示:(0,10] 3481,表示市盈率在(0,10] 的股票有3481只。
ratios = pd.cut(ratio,regions,labels=['非常非常不好','非常不好','不好','很一般','一般一般','一般好','好','很好','非常好','非常非常好'])

利用Python进行数据分析_Pandas_数据清理、转换、合并、重塑的更多相关文章
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- 利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 读取excel数据 import pandas as pd import ...
- 利用Python进行数据分析_Pandas_数据结构
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 首先,需要导入pandas库的Series和DataFrame In [21] ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
- 利用Python进行数据分析_Pandas_基本功能
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 第一 重新索引 Series的reindex方法 In [15]: obj = ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用python进行数据分析之数据规整化
数据分析和建模大部分时间都用在数据准备上,数据的准备过程包括:加载,清理,转换与重塑. 合并数据集 pandas对象中的数据可以通过一些内置方法来进行合并: pandas.merge可根据一个或多个键 ...
- 利用python进行数据分析之数据聚合和分组运算
对数据集进行分组并对各分组应用函数是数据分析中的重要环节. group by技术 pandas对象中的数据会根据你所提供的一个或多个键被拆分为多组,拆分操作是在对象的特定轴上执行的,然后将一个函数应用 ...
- 利用python进行数据分析之数据加载存储与文件格式
在开始学习之前,我们需要安装pandas模块.由于我安装的python的版本是2.7,故我们在https://pypi.python.org/pypi/pandas/0.16.2/#downloads ...
随机推荐
- 第二次作业社团UML图
第二次作业 UML图 用例图: 时序图: 申请加入社团 学生可以在页面投递社团加入申请,送交给社团管理员审批 社团活动审批 团委通过社团提交胡活动进行审批 评价活动 社团活动举行完,会有相应的团委和学 ...
- zabbix(4)数据库表分区优化
一.zabbix 数据库存储 zabbix-server将采集到的数据存储在数据库(mysql.oracle等),而数据存储的大小与每秒处理的数量量有关,因此数据存储取决于以下两个因数: (1)Req ...
- Linux下如何回到根目录
cd .. , 意思是到上一级目录: cd - ,意思是返回到上次的目录,类似windows返回 : cd /,意思是回到根目录.
- 使用Adivisor配置增强处理,来实现数据库读写分离
一.先写一个demo来概述Adivisor的简单使用步骤 实现步骤: 1.通过MethodBeforeAdivice接口实现前置增强处理 public class ServiceBeforeAdvis ...
- create table:使用SELECT语句创建表
oracle下直接(创建表) create table newtablename as select * from oldtablename sqlserver的语法是(自动创建表) : select ...
- My algorithmic road
序言 初窥门径 1 第一题 素数的烦恼 离开了家乡,你到达了数字之地,在这里数字2总感觉自己是自然数中最独特的一个,他只有一和它本身两个因数,为此它十分苦恼.为了不再寂寞,他建立了素数王国,他请求许多 ...
- vim 操作命令大全(转)
1. 关于Vim vim是我最喜欢的编辑器,也是Linux下第二强大的编辑器. 虽然emacs是公认的世界第一,我认为使用emacs并没有使用vi进行编辑来得高效. 如果是初学vi,运行一下vimtu ...
- 【Python】把文件名命名成canlendar.py竟然导致无法使用canlendar模块 附赠2020年月历
这个bug困扰了我一阵,直到在 http://www.codingke.com/question/15489 找到了解决问题的钥匙,真是没想到居然是这个原因导致的. 下面是出错信息,可以看到只要目录下 ...
- maven项目如何从私服nexus中下载依赖包
maven项目如何从私服nexus中下载依赖包 解决方法: 1.打开maven的config目录中settings.xml文件 2.在<profile></profiles> ...
- Jmeter响应断言--正则表达式判断纯数字
如图所示,这样是匹配14位数字,如果响应是纯数字可以直接用上