Hdu Binary Tree Traversals
In a preorder traversal of the vertices of T, we visit the root r followed by visiting the vertices of T1 in preorder, then the vertices of T2 in preorder.
In an inorder traversal of the vertices of T, we visit the vertices of T1 in inorder, then the root r, followed by the vertices of T2 in inorder.
In a postorder traversal of the vertices of T, we visit the vertices of T1 in postorder, then the vertices of T2 in postorder and finally we visit r.
Now you are given the preorder sequence and inorder sequence of a certain binary tree. Try to find out its postorder sequence.
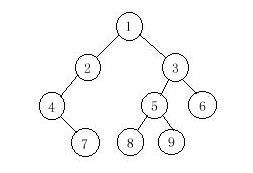
1 2 4 7 3 5 8 9 6
4 7 2 1 8 5 9 3 6
注: 已知二叉树的前序和中序遍历, 可以唯一确定二叉树的后序遍历, 但如果知道前序和后序,求中序遍历是不可能实现的.
算法:
由前序遍历的第一个元素可确定左、右子树的根节点,参照中序遍历又可进一步确定子树的左、
右子树元素。如此递归地参照两个遍历序列,最终构造出二叉树。
由前序和中序结果求后序遍历结果
树的遍历:给你一棵树的先序遍历结果和中序遍历的结果,让你求以后序遍历输出用递归。
每次把两个数组分成三个部分,父节点,左子树,右子树,把父节点放到数组里边,重复此步骤直到重建一棵新树
, 这时,数组里元素刚好是后序遍历的顺序
关键点:
中序遍历的特点是先遍历左子树,接着根节点,然后遍历右子树。这样根节点就把左右子树隔开了。而前序遍历的特点是先访问根节点,从而实现前序遍历结果提供根节点信息,中序遍历提供左右子树信息,从而实现二叉树的重建
【注明】
先序的排列里第一个元素是根,再比较中序的排列里根所在的位置,则能确定左子树,右子树元素个数numleft,numright且在先序排列里,先是一个根,再是numleft个左子树的元素排列,最后是numright个右子树的元素排列。
该过程就是从inorder数组中找到一个根,然后从preorder数组的位置来确定改点到底是左儿子还是右儿子。如此一直循环下去知道一棵完整的数建立完成。
#include <stdio.h>
#include <stdlib.h> const int MAX = 1000 + 10;
int n,in[MAX],pre[MAX];
typedef struct BITree
{
int data,index;
BITree *Left,*Right;
}BiTree,*Tree; void DFS(Tree &root,int index)
{
if(root == NULL){
root = (Tree)malloc(sizeof(BiTree));
root->data = in[index];
root->index = index;
root->Left = NULL;
root->Right = NULL;
}else
{
if(index < root->index)
DFS(root->Left,index);
else
DFS(root->Right,index);
}
} void CreateTree(Tree &root)
{
int i,j,index;
root = (Tree)malloc(sizeof(BiTree));
for(i = 1;i <= n;i++)
if(in[i] == pre[1])
{
root->data = pre[1];
root->index = i;
root->Left = NULL;
root->Right = NULL;
break;
}
index = i;
for(i = 2;i <= n;i++)
for(j = 1;j <= n;j++)
if(in[j] == pre[i])
{
if(j < index)
DFS(root->Left,j);
else
DFS(root->Right,j);
break;
}
} void PostOrder(Tree root,int x)
{
if(root == NULL) return ;
PostOrder(root->Left,x+1);
PostOrder(root->Right,x+1);
if(x == 0)
printf("%d",root->data);
else
printf("%d ",root->data);
} int main()
{
int i;
while(scanf("%d",&n)!=EOF)
{
Tree root;
for(i = 1;i <= n;i++)
scanf("%d",&pre[i]);
for(i = 1;i <= n;i++)
scanf("%d",&in[i]);
CreateTree(root);
PostOrder(root,0);
printf("\n");
}
return 0;
}
#include <iostream>
#include <cstdio>
using namespace std; const int MAX = 1000 + 10;
typedef struct BITree
{
int data;
BITree *Left,*Right;
BITree()
{
Left = NULL;
Right = NULL;
}
}*BiTree;
int pre[MAX],in[MAX]; void BuildTree(BiTree &root,int len,int pst,int ped,int inst,int ined)
{
int i,left_len = 0;
if(len<=0)return; //递归终止的条件
root = new BITree;
root->data = pre[pst];
for(i = inst;i <= ined;i++)
if(in[i] == pre[pst])
{
left_len = i - inst;
break;
}
BuildTree(root->Left,left_len,pst+1,pst+left_len,inst,i-1);
BuildTree(root->Right,len-left_len-1,pst+left_len+1,ped,i+1,ined);
} void PostTravel(BITree *root)
{
if(root)
{
PostTravel(root->Left);
PostTravel(root->Right);
printf("%d ",root->data);
}
} int main()
{
int i,n;
BiTree root;
while(scanf("%d",&n)!=EOF)
{
for(i = 1;i <= n;i++)
scanf("%d",&pre[i]);
for(i = 1;i <= n;i++)
scanf("%d",&in[i]);
BuildTree(root,n,1,n,1,n);
PostTravel(root->Left);
PostTravel(root->Right);
printf("%d\n",root->data);
}
return 0;
}
Hdu Binary Tree Traversals的更多相关文章
- HDU 1710 二叉树的遍历 Binary Tree Traversals
Binary Tree Traversals Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- HDU 1710 Binary Tree Traversals (二叉树遍历)
Binary Tree Traversals Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- HDU 1710 Binary Tree Traversals(树的建立,前序中序后序)
Binary Tree Traversals Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- hdu 1710 Binary Tree Traversals 前序遍历和中序推后序
题链;http://acm.hdu.edu.cn/showproblem.php?pid=1710 Binary Tree Traversals Time Limit: 1000/1000 MS (J ...
- hdu 1701 (Binary Tree Traversals)(二叉树前序中序推后序)
Binary Tree Traversals T ...
- hdu1710(Binary Tree Traversals)(二叉树遍历)
Binary Tree Traversals Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- HDU-1701 Binary Tree Traversals
http://acm.hdu.edu.cn/showproblem.php?pid=1710 已知先序和中序遍历,求后序遍历二叉树. 思路:先递归建树的过程,后后序遍历. Binary Tree Tr ...
- HDU 1710-Binary Tree Traversals(二进制重建)
Binary Tree Traversals Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
- Binary Tree Traversals(HDU1710)二叉树的简单应用
Binary Tree Traversals Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/O ...
随机推荐
- 论山寨手机与Android联姻 【10】SmartPhone的通信机制
上一章我们说到,智能手机 == 电脑 + 移动网卡,这个提法比较粗略,更精准的提法应当是,智能手机的硬件结构分为应用程序处理器AP,和基带处理器BP两个部分.虽然AP部分的功能与电脑主板基本类似,但是 ...
- N个数依次入栈,出栈顺序有多少种
题目:N个数依次入栈,出栈顺序有多少种? 首先介绍一下卡特兰数:卡特兰数前几项为 : 1, 1, 2, 5, 14, 42, 132, 429, 1430, 4862, 16796, 58786, 2 ...
- Java调用.dll文件
因为项目的需求,要在JAVA项目中调用Windows的Dll(动态链接库)文件,之前用Jni调用过C写的Dll文件,比较麻烦,这里不多说,网上也有很多这方面的文档.在网上找到一个开源的组件JNativ ...
- 编程内功修炼之数据结构—BTree(二)实现BTree插入、查询、删除操作
1 package edu.algorithms.btree; import java.util.ArrayList; import java.util.List; /** * BTree类 * * ...
- #include <locale.h> #include <locale>
C C++ C 1 setlocale setlocale,本函数用来配置地域的信息,设置当前程序使用的本地化信息. #include <stdio.h> #include <std ...
- Android-Tab单选控件
今天看到项目中有一个控件写得很美丽,据说是github上开源的控件,地址没找到,例如以下图所看到的,很常见的效果,几个tab页面来回切换: 转载请标明出处:http://blog.csdn.net/g ...
- vs快捷键
Ctrl+E,D ----格式化全部代码 Ctrl+A+K+FCtrl+E,F ----格式化选中的代码 Ctrl+K+FCTRL + SHIFT + B生成解决方案 Alt+B+B 或 F6 生成当 ...
- SQL SERVER中变量的定义、赋值与使用
本文面向对SQL SERVER中变量操作不熟悉的用户,希望能使他们在看完本文后能对变量操作有具体和全面的认识. 在学习SQL SERVER的过程中,很多时候需要对某些单独的值进行调试,这时就需 ...
- CentOS安装maven3.2.2(Linux系列适用)
首先,下载最新的maven3.2.2,地址:http://mirrors.cnnic.cn/apache/maven/maven-3/3.2.2/binaries/apache-maven-3.2.2 ...
- Programming C#.Classes and Objects.只读字段
只读字段 当字段声明中含有 readonly 修饰符时,该声明所引入的字段为只读字段.给只读字段的直接赋值只能作为声明的组成部分出现,或在同一类中的实例构造函数或静态构造函数中出现.(在这些上下文中, ...