hadoop完全分布式部署
1.我们先看看一台节点的hdfs的信息:(已经安装了hadoop的虚拟机:安装hadoophttps://www.cnblogs.com/lyx666/p/12335360.html)
start-dfs 打开hdfs需要启动的服务

然后再浏览器输入http://虚拟机ip地址:50070

问下滑: 可以看到以下相关信息
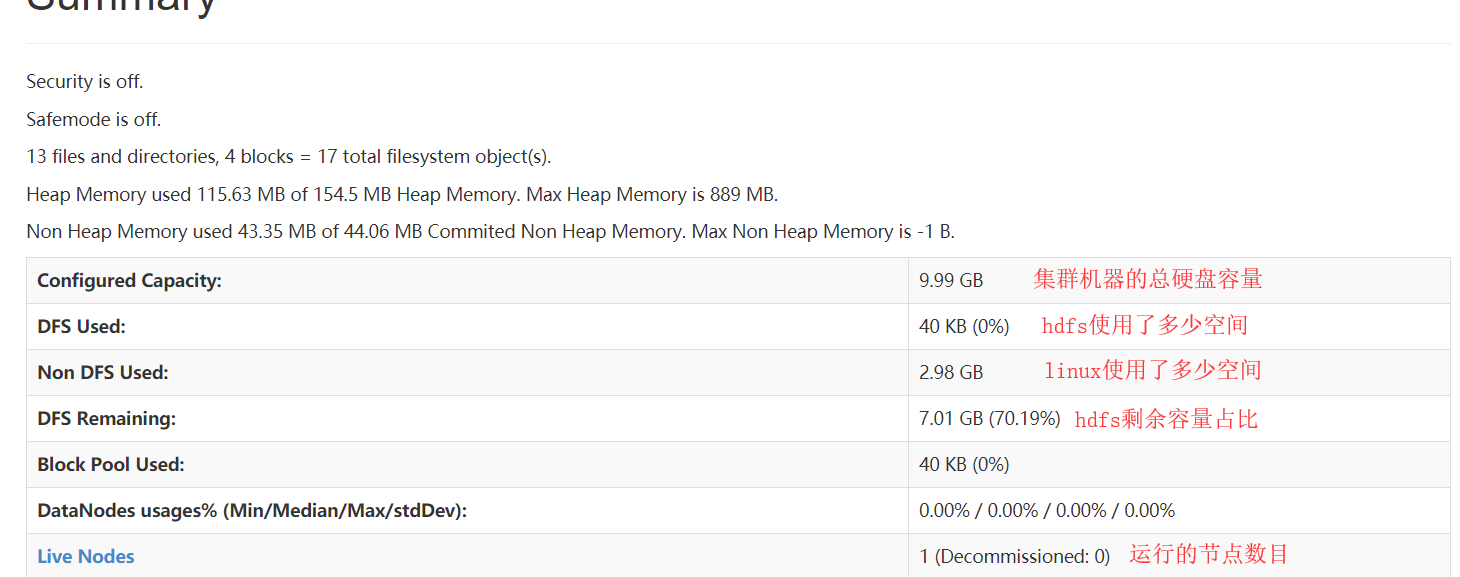
可以看到集群总容量大概为10G,而该集群只有一台机器,所以集群容量=该机器容量,可以看看这台虚拟机的硬盘是不是10G.
df -h / #确实是10G

2.接下来就要扩容该集群的容量,将这台虚拟机克隆(克隆步骤省略)
3.克隆机需要先配置以下
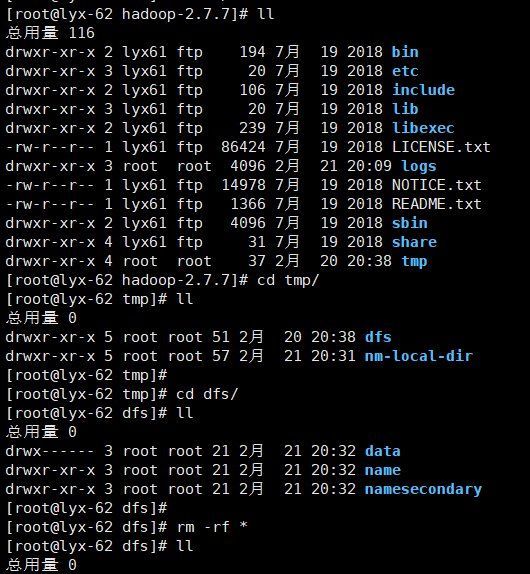
把克隆的dfs文件夹清空
将该文件夹下的数据清空:rm -rf *
网络ip:

BOOTPROTO=static 原本为DHCP
ONBOOT=yes 原本为no
IPADDR=192.168.43.62 ip地址 在网段里就行
NETMASK=255.255.255.0 子网掩码
GATEWAY=192.168.43.1 网关 需要查看主机的ipv4地址配置
DNS1=8.8.8.8 谷歌的dns解析

改完后重启网络:systemctl restart network
修改主机名
我这里是已经修改好了的,你们原本应该是localhost的主机名,我修改成lyx-62

修改后记得重启这台虚拟机:reboot
配置ip和主机名映射 还需要加上被克隆的虚拟机的ip和主机映射 【注意:这里两台都要添加修改】


修改后记得重启这两台虚拟机:reboot
配置ssh免密通信
(lyx-62)ssh-keygen #创建密钥对#
(lyx-62)ssh-copy-id lyx-62 #将公钥复制到lyx-62 也就是本机
注意这里另一台也需要(lyx-61):ssh-copy-id lyx-62 这样两台就能免密通信
修改hdfs-site.xfs配置文件 副本数修改为3【注意两台机器都需要修改】
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
将克隆机主机名添加到slaves配置文件中 也就是加入到集群中 这里修改的是【被克隆的】slaves.xml文件

3.只启动被克隆的hdfs需要的服务
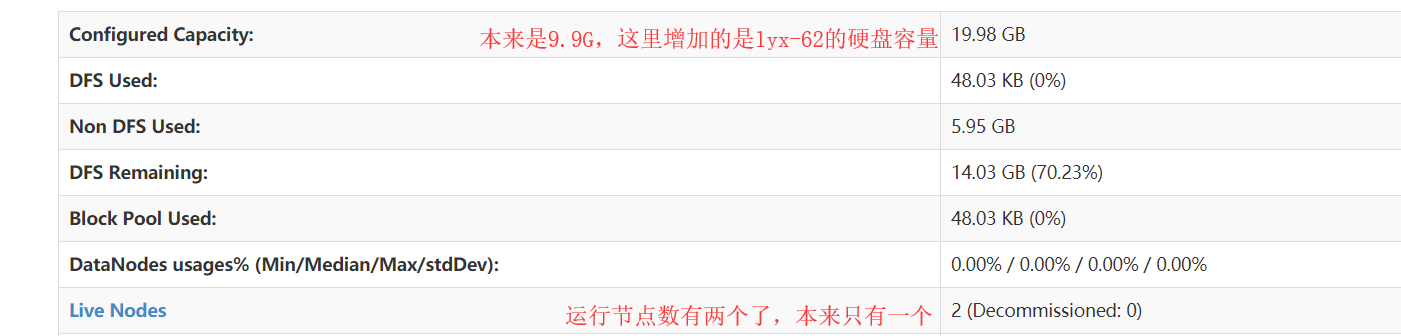
start-dfs.sh #可以看到lyx-62启动了datanode服务,说明它已经加入到这个集群了 所以它的硬盘也被加入到集群了

接下来我们在回过头来看看集群信息 可以发现硬盘容量增加了,说明lyx-62这台也被加入到集群了。
hadoop完全分布式部署的更多相关文章
- ubuntu下hadoop完全分布式部署
三台机器分别命名为: hadoop-master ip:192.168.0.25 hadoop-slave1 ip:192.168.0.26 hadoop-slave2 ip:192.168.0.27 ...
- Hadoop 完全分布式部署
完全分布式部署Hadoop 分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4)安装hadoop 5)配置环境变量 6)安装ssh 7)集群时间同步 7 ...
- Hadoop 完全分布式部署(三节点)
用来测试,我在VMware下用Centos7搭起一个三节点的Hadoop完全分布式集群.其中NameNode和DataNode在同一台机器上,如果有条件建议大家把NameNode单独放在一台机器上,因 ...
- Hadoop伪分布式部署
一.Hadoop组件依赖关系: 步骤 1)关闭防火墙和禁用SELinux 切换到root用户 关闭防火墙:service iptables stop Linux下开启/关闭防火墙的两种方法 1.永久性 ...
- ubuntu hadoop伪分布式部署
环境 ubuntu hadoop2.8.1 java1.8 1.配置java1.8 2.配置ssh免密登录 3.hadoop配置 环境变量 配置hadoop环境文件hadoop-env.sh core ...
- Hadoop+HBase分布式部署
test 版本选择
- Hadoop伪分布式模式部署
Hadoop的安装有三种执行模式: 单机模式(Local (Standalone) Mode):Hadoop的默认模式,0配置.Hadoop执行在一个Java进程中.使用本地文件系统.不使用HDFS, ...
- Hadoop 2.6.0分布式部署參考手冊
Hadoop 2.6.0分布式部署參考手冊 关于本參考手冊的word文档.能够到例如以下地址下载:http://download.csdn.net/detail/u012875880/8291493 ...
- Apache Hadoop 2.9.2 完全分布式部署
Apache Hadoop 2.9.2 完全分布式部署(HDFS) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.操作平台 [root@node101.y ...
随机推荐
- OpenCV2.4.13+VS2013配置方法
先说一下vc几代表的对应版本: vc8 = Visual Studio 2005 vc9 = Visual Studio 2008 vc10 = Visual Studio 2010 vc11 = V ...
- DFS或BFS(深度优先搜索或广度优先搜索遍历无向图)-04-无向图-岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量.一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的.你可以假设网格的四个边均被水包围. 示例 1: 输入: ...
- Http请求特殊符号变空格
Http请求特殊符号变空格 今天在调试客户端向服务器传递参数时,url中的参数值出现+,空格,/,?,%,#,&等特殊符号的时候就自动变成空格,在服务器端无法获得正确的参数值.解决方法如下: ...
- IO博客专栏
1. IO概览 2. 字符流与字节流的区别
- 深浅拷贝 集合(定义,方法) 函数(定义,参数,return,作用域) 初识
深浅拷贝 在python中浅拷贝 a=[1,2,3,4,]b=a.copy()b[0]='3333'print(a) #[1, 2, 3, 4] 浅拷贝一层并不会对a造成变化print(b) #[33 ...
- 八、django学习之分组查询、F查询和Q查询
分组查询.F查询和Q查询 分组查询 统计每个出版社出版的书籍的平均价格 第一种方式 obj = models.Book.objects.values('publishs_id').annotate(a ...
- 使用PyCharm创建并运行一个Python项目
(1)首先,在欢迎界面点击“Create New Project”: (2)在“New Project“左侧面板点击”Pure Python“,右侧Location选择自己要创建项目的路径(一般情况, ...
- CCF_201312-1_出现次数最多的数
水. #include<stdio.h> int main() { ,a[]={},num[]={}; scanf("%d",&T); ;i < T;i+ ...
- go接口详解
go面向接口编程知识点 接口定义与格式 隐式实现及实现条件 接口赋值 空接口 接口嵌套 类型断言 多态 接口定义与格式 接口(interface)是一种类型,用来定义行为(方法).这句话有两个重点,类 ...
- sublime 快捷键 【转】
Sublime Text 3 快捷键精华版 备用,方便查询 Ctrl+Shift+P:打开命令面板Ctrl+P:搜索项目中的文件Ctrl+G:跳转到第几行Ctrl+W:关闭当前打开文件Ctrl+S ...