Apache Kafka(三)- Kakfa CLI 使用
1. Topics CLI
1.1 首先启动 zookeeper 与 kafka
> zookeeper-server-start.sh config/zookeeper.properties
…
INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
INFO Expiring session 0x100ab41939d0000, timeout of 6000ms exceeded (org.apache.zookeeper.server.ZooKeeperServer)
INFO Processed session termination for sessionid: 0x100ab41939d0000 (org.apache.zookeeper.server.PrepRequestProcessor)
INFO Creating new log file: log.1d (org.apache.zookeeper.server.persistence.FileTxnLog)
> kafka-server-start.sh config/server.properties
…
Socket connection established to localhost/127.0.0.1:2181, initiating session (org.apache.zookeeper.ClientCnxn)
INFO Cluster ID = D69veaGlS5Ce3aHTsxCHkQ (kafka.server.KafkaServer)
…
INFO Awaiting socket connections on 0.0.0.0:9092. (kafka.network.Acceptor)
…
INFO Creating /brokers/ids/0 (is it secure? false) (kafka.zk.KafkaZkClient)
INFO Registered broker 0 at path /brokers/ids/0 with addresses: ArrayBuffer(EndPoint(ip-10-0-2-70.cn-north-1.compute.internal,9092,ListenerName(PLAINTEXT),PLAINTEXT)), czxid (broker epoch): 44 (kafka.zk.KafkaZkClient)
这里我们可以简单的了解到,启动了一个Kafka broker,id为 0,监听的端口为9092。
1.2. 创建一个 topic
这里需要注意的是 --replication-factor参数,例如:
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --topic first_topic --create --partitions 3 --replication-factor 2
此命令会返回一个报错:
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.
(kafka.admin.TopicCommand$)
此错误表示的是:指定的replication-factor的数量超过了broker的数量。
所以我们使用以下命令创建一个kafka topic:
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --topic first_topic --create --partitions 3 --replication-factor 1
然后列出已创建的kafka topics:
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --list
first_topic
如果我们需要更多有关一个topic的信息,如partitions,replication-factors 等,使用--descriebe:
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --topic first_topic --describe
Topic:first_topic PartitionCount:3 ReplicationFactor:1 Configs:
Topic: first_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: first_topic Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: first_topic Partition: 2 Leader: 0 Replicas: 0 Isr: 0
可以看到此topic有3个partition,id分别为0,1,2。每个partition的leader都是broker 0,replicas也是broker 0,Isr也是broker 0(因为replication-replica 为1)
现在我们创建第二个topic:
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --topic second_topic --create --partitions 6 --replication-factor 1
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --list
first_topic
second_topic
1.3. 删除一个topic:
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --topic second_topic --delete
Topic second_topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
可以看到,second_topic 被标注为deletion。如果delete.topic.enable没有被设置为true,则此topic不会被删除。
> kafka-topics.sh --zookeeper 10.0.2.70:2181 --list
first_topic
根据list的结果,我们可以看到second_topic 被删除,说明delete.topic.enable 默认是true。
2. Produer CLI
根据kafka-console-produer.sh 的使用描述,在使用此脚本时,必须提供的参数是--broker-list与 –topic,现在我们指定这两个参数后执行:
> kafka-console-producer.sh --broker-list 10.0.2.70:9092 --topic first_topic
然后输入messages:
>
>hello world
>are you ok?
>learning kafka
>another message :)
Ctrl + C 退出
在启动一个producer时,也可以指定它的属性,例如:
> kafka-console-producer.sh --broker-list 10.0.2.70:9092 --topic first_topic --producer-property acks=all
>yep is acked
>hello ack
>are you ok? acked!
>^C
若是我们指定一个不存在的topic的话会怎么样?
> kafka-console-producer.sh --broker-list 10.0.2.70:9092 --topic new_topic
>new topic messages
[2019-08-08 03:37:47,160] WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 3 : {new_topic=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
>what about now
>it is ok
>^C
可以看到,在指定一个不存在的topic后,在输入消息时,第一次返回了一个WARN,这是由于此topic 没有一个leader。正如之前提到过的,producer有自动recover的机制,所以会尝试找到一个leader去发送消息。我们使用list看一下结果:
> kafka-topics.sh --zookeeper 10.0.2.70 --list
first_topic
new_topic
> kafka-topics.sh --zookeeper 10.0.2.70 --topic new_topic --describe
Topic:new_topic PartitionCount:1 ReplicationFactor:1 Configs:
Topic: new_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
可以看到自动新创建的new_topic,以及创建后的默认配置:partition数目为1,replication-factor数目也为1。此默认设置在 server.properties 里配置,例如:
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
建议永远都要先创建topic,不要使用默认创建topic
3. Consumer CLI
通过查看kafka-console-consumer.sh脚本,可以看到必须的参数为:--bootstrap-server 与 --topic。按照规则启动一个consumer:
> kafka-console-consumer.sh --bootstrap-server 10.0.2.70:9092 --topic first_topic
但是可以看到的是,此consumer并未读取任何之前producer发送的数据。原因在于:consumer仅会读取在它启动之后的数据。
所以若是我们此时使用producer向first_topic 发送数据,则会在consumer控制台输出接收到的数据。
那如何获取producer之前发送的所有数据?使用 --from-beginning
> kafka-console-consumer.sh --bootstrap-server 10.0.2.70:9092 --topic first_topic --from-beginning
learning kafka
are you ok? acked!
hello world
another message :)
yep is acked
hi
are you ok?
hello ack
可以看到,以上消息输出的顺序并不为我们输入的顺序。这是因为仅在同一个partition中的消息是有序的,而first_topic 中有3个partitions。若是一个topic中仅有一个partition,则此topic中的全部消息都是有序的。
3. Consumers in Group
3.1. 使用consumer group:
> kafka-console-consumer.sh --bootstrap-server 10.0.2.70:9092 --topic first_topic --group my-first-app
使用此方法,可以读取到producer写入的每条消息。
但是如果我们再次启动一个 consumer,使用同样的 --group my-first-app:
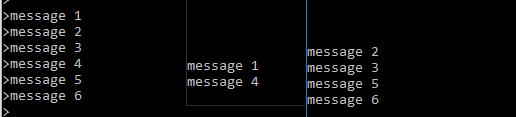
最左边的为producer,可以看到的是,第一个consumer先获取一条message,然后第二个consumer获取两条message,然后依次类推。
这是由于:consumer group里当前有两个consumer,而topic有3个partition,所以此时consumer group中的一个consumer会负责2个partition的读,而另一个consumer会负责剩余1个partition的读。
若此时再为同一个consumer group启动一个consumer,则每个partition对应于一个consumer,此时发送3条message,会由3个consumer依次读取。
3.2. 使用--from-beginning
对第二个 consumer group使用 --from-beginning:
> kafka-console-consumer.sh --bootstrap-server 10.0.2.70:9092 --topic first_topic --group my-second-app --from-beginning
learning kafka
are you ok? acked!
…
可以看到此consumer 列出了所有之前的消息。若是我们再次执行此命令,则会发现不会打印任何消息。
这是因为每个group的offsets都会由Kafka记录下来。所以再次使用此group读数据时,会使用记录的offsets继续读取数据。
4. Consumer Group CLI
查看 kafka-consumer-groups的用途:
This tool helps to list all consumer groups, describe a consumer group, delete consumer group info, or reset consumer group offsets.
必须的参数是 --bootstrap-server
首先列出所有groups:
> kafka-consumer-groups.sh --bootstrap-server 10.0.2.70:9092 --list
my-first-app
my-first-application
my-second-app
查看一个group的详细信息:
> kafka-consumer-groups.sh --bootstrap-server 10.0.2.70:9092 --describe --group my-first-app

这里首先打出的是:consumer group ‘my-first-app’ has no active members。这是因为我们已经停止了这个consumer group 下的所有 consumers,所以此consumer group 下面没有一个active members。
接下打出的信息显示了每个partition,当前的offset;log里最终的 offset;以及 LAG,它表示的是最终还未被消费的message数量(也就是cur-offset与log-end-offset的差)。
我们再往 my-first-app 写入几条数据,然后对consumer group 做describe:

可以看到 LAG 增加。
然后使用consumer-group 读此topic:
> kafka-console-consumer.sh --bootstrap-server 10.0.2.70:9092 --topic first_topic --group my-first-app
help
yep
再 describe:

可以看到LAG为0,且列出了当前consumers 的 id
5. Reset Offset
我们看到 consumer groups 的offset 可以被kafka记录,那如何重置一个consumer group 的offset?使用:
> kafka-consumer-groups.sh --bootstrap-server 10.0.2.70:9092 --reset-offsets --group my-first-app --topic first_topic --to-earliest --execute
GROUP TOPIC PARTITION NEW-OFFSET
my-first-app first_topic 0 0
my-first-app first_topic 2 0
my-first-app first_topic 1 0
使用consumer 检查:
> kafka-console-consumer.sh --bootstrap-server 10.0.2.70:9092 --topic first_topic --group my-first-app
learning kafka
are you ok? acked!
…
也可以使用--shift-by将offsets做移动,而不是重置:

这里我们用正数做--shift-by 的参数,可以发现 offset是向后移动。所以若是需要向前移动,则需要使用负数,例如:
> kafka-consumer-groups.sh --bootstrap-server 10.0.2.70:9092 --reset-offsets
--group my-first-app --topic first_topic --shift-by -2 --execute
GROUP TOPIC PARTITION NEW-OFFSET
my-first-app first_topic 0 12
my-first-app first_topic 2 13
my-first-app
first_topic 1 13
然后使用 consumer 验证:
> kafka-console-consumer.sh --bootstrap-server
10.0.2.70:9092 --topic first_topic --group my-first-app
help
yep
6. Kafka UI
以上命令均基于命令行,也可以使用图形化界面配置并访问kafka,如Kafka Tool:

此工具官网地址如下:
Apache Kafka(三)- Kakfa CLI 使用的更多相关文章
- Apache Kafka(一)- Kakfa 简介与术语
Apache Kafka 1. Kafka简介.优势.以及使用场景 Kafka的优势: 开源 分布式,弹性架构,fault tolerant 水平扩展: 可以扩展到100个brokers 可以扩展到每 ...
- Apache Kafka(二)- Kakfa 安装与启动
安装并启动Kafka 1.下载最新版Kafka(当前为kafka_2.12-2.3.0)并解压: > wget http://mirror.bit.edu.cn/apache/kafka/2.3 ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
- 【转载】Understanding When to use RabbitMQ or Apache Kafka
https://content.pivotal.io/rabbitmq/understanding-when-to-use-rabbitmq-or-apache-kafka RabbitMQ: Erl ...
- Apache Kafka框架学习
背景介绍 消息队列的比较 kafka框架介绍 术语解释 文件存储 可靠性保证 高吞吐量实现 负载均衡 应用场景 背景介绍: kafka是由Apache软件基金会维护的一个开源流处理平台,由scala和 ...
- 【转载】Apache Kafka监控之Kafka Web Console
http://www.iteblog.com/archives/1084 Kafka Web Console是一款开源的系统,源码的地址在https://github.com/claudemamo/k ...
- 【转载】Apache Kafka:下一代分布式消息系统
http://www.infoq.com/cn/articles/kafka-analysis-part-1 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩 ...
- 用Apache Kafka构建流数据平台
近来,有许多关于“流处理”和“事件数据”的讨论,它们往往都与像Kafka.Storm或Samza这样的技术相关.但并不是每个人都知道如何将这种技术引入他们自己的技术栈.于是,Confluent联合创始 ...
- How To Install Apache Kafka on Ubuntu 14.04
打算学习kafka ,接触一些新的知识.加油!!! 参考:https://www.digitalocean.com/community/tutorials/how-to-install-apache- ...
随机推荐
- vue动画&过渡整理
- 图片选择并使用base64展示
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 【巨杉数据库SequoiaDB】巨杉数据库无人值守智能自动化测试实践
刚刚过去的春节,新型冠状病毒疫情突如其来地横扫大江南北.为了响应国家号召,许多软件公司和互联网公司也将在较长一段时间内建议员工采取远程办公的方式,同时也存在骨干工程师无法及时返岗的问题,使得生产力大受 ...
- Disharmony Trees HDU - 3015 树状数组+离散化
#include<cstdio> #include<cstring> #include<algorithm> #define ll long long using ...
- 关于Comparable和Comparator那些事
在实际项目开发过程中,我们经常需要对某个对象或者某个集合中的元素进行排序,常用的两种方式是实现某个接口.常见的可以实现比较功能的接口有Comparable接口和 Comparator接口,那么这两个又 ...
- List<SelectListItem> 转为 SelectList
List<SelectListItem> 转为/转换 SelectList SelectList slPayCh = new SelectList(GetPayChannels(),&qu ...
- Microsoft.EntityFrameworkCore.Internal.ServiceProviderCache的类型初始值设定项引发异常。 ---> System.IO.FileLoadException: 未能加载文件或程序集
场景: 安装程序到全新的环境的电脑时中(此时已经安装了能正常安装程序电脑的环境) 完整错误: Application_ThreadException:System.TypeInitialization ...
- 刷题22. Generate Parentheses
一.题目说明 这个题目是22. Generate Parentheses,简单来说,输入一个数字n,输出n对匹配的小括号. 简单考虑了一下,n=0,输出"";n=1,输出" ...
- 13:IO流
IO简介 继承结构 整体架构 常用内容 分类 根据处理的数据单位不同,分为字节流和字符流:in/out相对于程序而言的输入(读取)和输出(写出)的过程,即根据数据的流向不同称为输入流和输出流 字符流的 ...
- .NetCore学习笔记:三、基于AspectCore的AOP事务管理
AOP(面向切面编程),通过预编译方式和运行期间动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是函数式编程的一种衍生范型.利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑 ...