【中文分词】最大熵马尔可夫模型MEMM
Xue & Shen '2003 [2]用两种序列标注模型——MEMM (Maximum Entropy Markov Model)与CRF (Conditional Random Field)——用于中文分词;看原论文感觉作者更像用的是maxent (Maximum Entropy) 模型而非MEMM。MEMM是由McCallum et al. '2000 [1]提出MEMM,针对于HMM的两个痛点:一是其为生成模型(generative model),二是不能使用更加复杂的feature。
1. 前言
首先,将简要地介绍HMM与maxent模型。
HMM
概率图模型(probabilistic graphical model, PGM)指用图表示变量相关(依赖)关系的概率模型,主要分为两类:
- 有向图模型或贝叶斯网(Bayesian network),使用有向图表示变量间的依赖关系;
- 无向图模型或马尔可夫网(Markov network),使用无向图表示变量间相关关系。
监督学习的任务就是学习一个模型,对于给定的输入\(X\),能预测出类别\(Y\)。所学习到的模型一般可表示为决策函数:
\begin{equation}
Y = f(X)
\label{eq:deci}
\end{equation}
或者为条件概率
\begin{equation}
\arg \mathop{max}\limits_{Y} P(Y|X)
\label{eq:cond}
\end{equation}
监督学习的模型分为生成模型(generative model)与判别模型(discriminative model)。生成模型学习联合概率分布\(P(X, Y)\),然后通过贝叶斯定理求解条件概率\eqref{eq:cond},而判别模型则是直接学习决策函数\eqref{eq:deci}或条件概率\eqref{eq:cond}。HMM属于生成模型的有向图PGM,通过联合概率建模:
\[
P(S,O) = \prod_{t=1}^{n}P(s_t|s_{t-1})P(o_t|s_t)
\]
其中,\(S\)、\(O\)分别表示状态序列与观测序列。HMM的解码问题为\(\arg \mathop{max}\limits_{S} P(S|O)\);定义在时刻\(t\)状态为\(s\)的所有单个路径\(s_1^t\)中的概率最大值为
\[
\delta_t(s) = \max P(s_1^{t-1}, o_1^{t}, s_t=s)
\]
则有
\[
\begin{aligned}
\delta_{t+1}(s) & = \max P(s_1^{t}, o_1^{t+1}, s_{t+1}=s) \\
& = \max_{s'} P(s_1^{t-1}, o_1^{t}, s_t=s') P(s_{t+1}|s_t) P(o_{t+1}|s_{t+1}) \\
& = \max_{s'} [\delta_t(s') P(s|s')] P(o_{t+1}|s)
\end{aligned}
\]
上述式子即为(用于解决HMM的解码问题的)Viterbi算法的递推式;可以看出HMM是通过联合概率来求解标注问题的。
最大熵模型
最大熵(Maximum Entropy)模型属于log-linear model,在给定训练数据的条件下对模型进行极大似然估计或正则化极大似然估计:
\begin{equation}
P_w(y|x) = \frac{exp \left( \sum_i w_i f_i(x,y) \right)}{Z_w(x)}
\label{eq:me-model}
\end{equation}
其中,\(Z_w(x) = \sum_{y} exp \left( \sum_i w_i f_i(x,y) \right)\)为归一化因子,\(w\)为最大熵模型的参数,\(f_i(x,y)\)为特征函数(feature function)——描述\((x,y)\)的某一事实。
最大熵模型并没有假定feature相互独立,允许用户根据domain knowledge设计feature。
2. MEMM
MEMM并没有像HMM通过联合概率建模,而是直接学习条件概率
\begin{equation}
P(s_t|s_{t-1},o_t)
\label{eq:memm-cond}
\end{equation}
因此,有别于HMM,MEMM的当前状态依赖于前一状态与当前观测;HMM与MEMM的图模型如下(图来自于[3]):
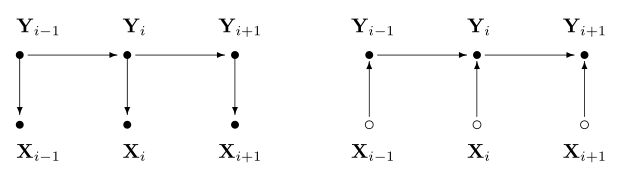
一般化条件概率\eqref{eq:memm-cond}为\(P(s|s',o)\)。MEMM用最大熵模型来学习条件概率\eqref{eq:memm-cond},套用模型\eqref{eq:me-model}则有:
\begin{equation}
P(s|s',o) = \frac{ exp \left( \sum_a \lambda_a f_a(o,s) \right)}{ Z(o,s')}
\label{eq:memm-model}
\end{equation}
其中,\(\lambda_a\)为学习参数;\(a=<b,s>\)且\(b\)为feature,\(s\)为destination state;特征函数\(f_a(o,s)\)的示例如下(图出自于[6]):

类似于HMM,MEMM的解码问题的递推式:
\[
\delta_{t+1}(s) = \max_{s'} \delta_t(s') P(s|s', o_{t+1})
\]
但是,MEMM存在着标注偏置问题(label bias problem)。比如,有如下的概率分布(图来自于[7]):

根据上述递推式,则概率最大路径如下:

但是,从全局的角度分析:
- 无论观测值,State 1 总是更倾向于转移到State 2;
- 无论观测值,State 2 总是更倾向于转移到State 2.
从式子\eqref{eq:memm-model}可以看出MEMM所做的是本地归一化,导致有更少转移的状态拥有的转移概率普遍偏高,概率最大路径更容易出现转移少的状态。因MEMM存在着标注偏置问题,故全局归一化的CRF被提了出来[3]。欲知CRF如何,请看下一篇分解。
3. 参考资料
[1] McCallum, Andrew, Dayne Freitag, and Fernando CN Pereira. "Maximum Entropy Markov Models for Information Extraction and Segmentation." Icml. Vol. 17. 2000.
[2] Xue, Nianwen, and Libin Shen. "Chinese word segmentation as LMR tagging." Proceedings of the second SIGHAN workshop on Chinese language processing-Volume 17. Association for Computational Linguistics, 2003.
[3] Lafferty, John, Andrew McCallum, and Fernando Pereira. "Conditional random fields: Probabilistic models for segmenting and labeling sequence data." Proceedings of the eighteenth international conference on machine learning, ICML. Vol. 1. 2001.
[4] 李航,《统计学习方法》.
[5] 周志华,《机器学习》.
[6] Nikos Karampatziakis, Maximum Entropy Markov Models.
[7] Ramesh Nallapati, Conditional Random Fields.
【中文分词】最大熵马尔可夫模型MEMM的更多相关文章
- 标记偏置 隐马尔科夫 最大熵马尔科夫 HMM MEMM
隐马尔科夫模型(HMM): 图1. 隐马尔科夫模型 隐马尔科夫模型的缺点: 1.HMM仅仅依赖于每个状态和它相应的观察对象: 序列标注问题不仅和单个词相关,并且和观察序列的长度,单词的上下文,等等相关 ...
- 最大熵马尔科夫模型(MEMM)及其标签偏置问题
定义: MEMM是这样的一个概率模型,即在给定的观察状态和前一状态的条件下,出现当前状态的概率. Ø S表示状态的有限集合 Ø O表示观察序列集合 Ø Pr(s|s’,o):观察和状态转移概 ...
- 转:从头开始编写基于隐含马尔可夫模型HMM的中文分词器
http://blog.csdn.net/guixunlong/article/details/8925990 从头开始编写基于隐含马尔可夫模型HMM的中文分词器之一 - 资源篇 首先感谢52nlp的 ...
- HMM(隐马尔科夫模型)与分词、词性标注、命名实体识别
转载自 http://www.cnblogs.com/skyme/p/4651331.html HMM(隐马尔可夫模型)是用来描述隐含未知参数的统计模型,举一个经典的例子:一个东京的朋友每天根据天气{ ...
- 一文搞懂HMM(隐马尔可夫模型)
什么是熵(Entropy) 简单来说,熵是表示物质系统状态的一种度量,用它老表征系统的无序程度.熵越大,系统越无序,意味着系统结构和运动的不确定和无规则:反之,,熵越小,系统越有序,意味着具有确定和有 ...
- 一文搞懂HMM(隐马尔可夫模型)-转载
写在文前:原博文地址:https://www.cnblogs.com/skyme/p/4651331.html 什么是熵(Entropy) 简单来说,熵是表示物质系统状态的一种度量,用它老表征系统的无 ...
- 隐马尔科夫模型python实现简单拼音输入法
在网上看到一篇关于隐马尔科夫模型的介绍,觉得简直不能再神奇,又在网上找到大神的一篇关于如何用隐马尔可夫模型实现中文拼音输入的博客,无奈大神没给可以运行的代码,只能纯手动网上找到了结巴分词的词库,根据此 ...
- [综]隐马尔可夫模型Hidden Markov Model (HMM)
http://www.zhihu.com/question/20962240 Yang Eninala杜克大学 生物化学博士 线性代数 收录于 编辑推荐 •2216 人赞同 ×××××11月22日已更 ...
- 【整理】图解隐马尔可夫模型(HMM)
写在前面 最近在写论文过程中,研究了一些关于概率统计的算法,也从网上收集了不少资料,在此整理一下与各位朋友分享. 隐马尔可夫模型,简称HMM(Hidden Markov Model), 是一种基于概率 ...
随机推荐
- 用scikit-learn学习DBSCAN聚类
在DBSCAN密度聚类算法中,我们对DBSCAN聚类算法的原理做了总结,本文就对如何用scikit-learn来学习DBSCAN聚类做一个总结,重点讲述参数的意义和需要调参的参数. 1. scikit ...
- 在vim中使用查找命令查找指定字符串
要自当前光标位置向上搜索,请使用以下命令: /pattern Enter 其中,pattern 表示要搜索的特定字符序列. 要自当前光标位置 ...
- 集合(set)-Python3
set 的 remove() 和 discard() 方法介绍. 函数/方法名 等价操作符 说明 所有集合类型 len(s) 集合基数:集合s中元素个数 set([obj]) 可变集合工 ...
- ObserverPattern(观察者模式)
import java.util.ArrayList; import java.util.List; /** * 观察者模式 * @author TMAC-J * 牵一发而动全身来形容观察者模式在合适 ...
- 微信开发笔记(accesstoken)
access_token分两种 一种是公众号权限获取用,调用cgi-bin接口 ,此种token一个公众号同时只有一个,用这一个就够了. 服务器最好缓存. 用这个token前提是用户关注了此公众号. ...
- Android开发案例 – 在AbsListView中使用倒计时
在App中, 有多种多样的倒计时需求, 比如: 在单View上, 使用倒计时, 如(如图-1) 在ListView(或者GridView)的ItemView上, 使用倒计时(如图-2) 图-1 图-2 ...
- 真正的汉化-PowerDesigner 16.5 汉化
一.背景 经常使用PowerDesigner,之前使用15版本,后来16出来后,就一直在使用16,不过一直是英文.一些同事对使用英文版总显示有些吃力. 遍寻百度.必应,都没有找到真正的针对版本16的汉 ...
- 好用的Markdown编辑器一览 readme.md 编辑查看
https://github.com/pandao/editor.md https://pandao.github.io/editor.md/examples/index.html Editor.md ...
- 2DToolkit官方文档中文版打地鼠教程(三):Sprite Collections 精灵集合
这是2DToolkit官方文档中 Whack a Mole 打地鼠教程的译文,为了减少文中过多重复操作的翻译,以及一些无必要的句子,这里我假设你有Unity的基础知识(例如了解如何新建Sprite等) ...
- 避免调试代码导致IE出错
记录一下 if(!window.console){ var names = ["log", "debug", "info", "w ...