mysql分库分区分表
分表:
分表分为水平分表和垂直分表。
水平分表原理:
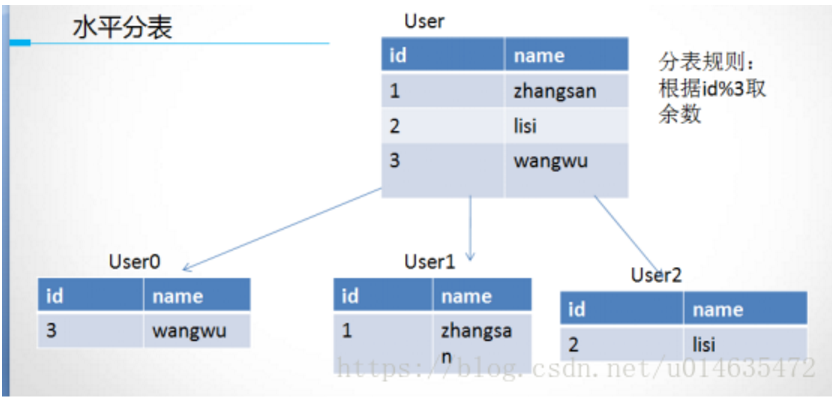
分表策略通常是用户ID取模,如果不是整数,可以首先将其进行hash获取到整。
水平分表遇到的问题:
1. 跨表直接连接查询无法进行
2. 我们需要统计数据的时候
3. 如果数据持续增长,达到现有分表的瓶颈,需要增加分表,此时会出现数据重新排列的情况
解决方案建议:
1. 第1,2点可以通过增加汇总的冗余表,虽然数据量很大,但是可以用于后台统计或者查询时效性比较底的情况,而且我们可以提前算好某个时间点或者时间段的数据
2. 第3点解决建议:
1. 可以开始的时候,就分析大概的数据增长率,来大概确定未来某段时间内的数据总量,从而提前计算出未来某段时间内需要用到的分表的个数
2. 考虑表分区,在逻辑上面还是一个表名,实际物理存储在不同的物理地址上
3. 分库
垂直拆分原则:
1. 把大字段独立存储到一张表中
2. 把不常用的字段单独拿出来存储到一张表
3. 把经常在一起使用的字段可以拿出来单独存储到一张表
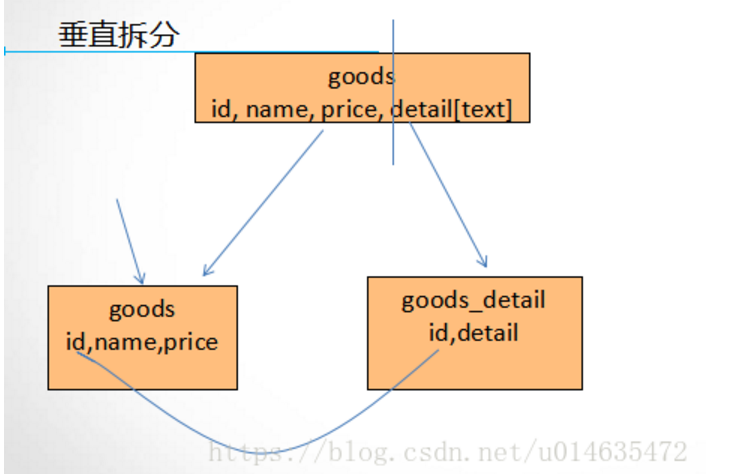
垂直拆分标准:
1.表的体积大于2G并且行数大于1千万
2.表中包含有text,blob,varchar(1000)以上
3.数据有时效性的,可以单独拿出来归档处理
/*表的体积计算*/
CREATE TABLE `test1` (
id bigint(20) not null auto_increment,
detail varchar(2000),
createtime datetime,
validity int default '0',
primary key (id)
);
1000万 bigint 8字节 varchar 2000 字节 datetime 8字节 validity 4字节
(8+2000+8+4) * 10000000 = 20200000000 字节 == 18G
分表后体积:
CREATE TABLE `test1` (
id int not null auto_increment,
createtime timestamp,
validity tinyint default 0,
primary key (id)
);
(4+4+1) * 10000000 = 0.08G
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。
分库也可以按照业务分库,比如订单表和库存表在两个库,要注意处理好跨库事务。
分表和分库 同时实现。
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
1、中间变量 = user_id%(库数量*每个库的表数量);
2、库序号 = 取整(中间变量/每个库的表数量);
3、表序号 = 中间变量%每个库的表数量;
例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
1、中间变量 = 262145%(256*1024)= 1;
2、库序号 = 取整(1/1024)= 0;
3、表序号 = 1%1024 = 1;
这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。
表分区:
就是将一个数据量比较大的表,用某种方法把数据从物理上分成若干个小表来存储(类似水平分表),从逻辑来看还是一个大表。分表最大分1024,一般分100左右比较适合。
使用场景:
对于这种数据库比较多,但是并发不是很多的情况下,可以采用表分区。
对于数据量比较大的,但是并发也比较高的情况下,可以采用分表和分区相结合。
/*range分区*/
create table test_range(
id int not null default 0
)engine=myisam default charset=utf8
partition by range(id)(
partition p1 values less than (3),
partition p2 values less than (5),
partition p3 values less than maxvalue
);
/*hash分区*/
create table test_hash(
id int not null default 0
)engine=innodb default charset=utf8
partition by hash(id) partitions 10;
/*线性hash分区*/
create table test_linear(
id int not null default 0
)engine=innodb default charset=utf8
partition by linear hash(id) partitions 10;
/* list分区*/
create table test_list(
id int not null
) engine=innodb default charset=utf8
partition by list(id)(
partition p0 values in (3,5),
partition p1 values in (2,6,7,9)
);
/* key 分区 */
CREATE TABLE test_key (
col1 INT NOT NULL
)
PARTITION BY linear KEY (col1)
PARTITIONS 10;
普通的hash分区 增加风区后,需要重新计算
线性hash分区(了解) 增加分区后,还是在原来的分区
线性hash 相对于 hash分区 没有那么均匀
Key分区用的比较少,也是hash分区
mysql分库分区分表的更多相关文章
- 一文搞懂│mysql 中的备份恢复、分区分表、主从复制、读写分离
目录 mysql 的备份和恢复 mysql 的分区分表 mysql 的主从复制读写分离 mysql 的备份和恢复 创建备份管理员 创建备份管理员,并授予管理员相应的权限 备份所需权限:select,r ...
- 【分库、分表】MySQL分库分表方案
一.Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. ...
- Java互联网架构-Mysql分库分表订单生成系统实战分析
概述 分库分表的必要性 首先我们来了解一下为什么要做分库分表.在我们的业务(web应用)中,关系型数据库本身比较容易成为系统性能瓶颈,单机存储容量.连接数.处理能力等都很有限,数据库本身的“有状态性” ...
- mysql分库分表(一)
mysql分库分表 参考: https://blog.csdn.net/xlgen157387/article/details/53976153 https://blog.csdn.net/cleve ...
- 思考--mysql 分库分表的思考
查询不在分库键上怎么办,扫描所有库?由于分库了,每个库扫描很快?所以比单个表的扫描肯定快,可以这样理解吗. 多表jion怎么弄,把内层表发给每个分库吗? citus,tidb 都有这些问题,citus ...
- mysql 数据库 分表后 怎么进行分页查询?Mysql分库分表方案?
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- Mysql分库分表方案
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- MYSQL分库分表和不停机更改表结构
在MYSQL分库分表中我们一般是基于数据量比较大的时间对mysql数据库一种优化的做法,下面我简单的介绍一下mysql分表与分库的简单做法. .分库分表 很明显,一个主表(也就是很重要的表,例如用户表 ...
- MySQL分库分表备份脚本
MySQL分库备份脚本 #脚本详细内容 [root@db02 scripts]# cat /server/scripts/Store_backup.sh #!/bin/sh MYUSER=root M ...
随机推荐
- [UE4]射击起点、终点的计算方法
一.射击起点,这个简单,一般是以角色的相机位置为作为射击起点,而不是枪口的位置作为起点 二.射击终点,角色朝向 * 射击距离 + 射击起点 角色朝向:单位向量 角色朝向 * 射击距离:向量长度 向量长 ...
- tips:Java的Random类和Random函数
tips:Java的Random类和Random函数! 随机数是一个很有趣的东西,在java中可以通过下面这2种方法得到: (1)Random类: Random类是java.util.Random这个 ...
- courator - create
0. retry policy RetryPolicy retryPolicy = new ExponentialBackoffRetry(3000,3); 1. client 1) recipes ...
- 「一本通 6.4 例 4」曹冲养猪(CRT)
复习一下 扩展中国剩余定理 首先考虑两个同余方程 \[ x \equiv a_1\; mod\; m_1\\ x \equiv a_2\; mod\; m_2 \] 化成另一个形式 \[ x = n_ ...
- retry之python重试机制
安装 pip install retry Retry装饰器 retry(exceptions=Exception, tries=-1, delay=0, max_delay=None, backoff ...
- leetCode 557. Reverse Words in a String I
Input: "Let's take LeetCode contest" Output: "s'teL ekat edoCteeL tsetnoc" 解:输入一 ...
- LeetCode 7 Reverse Integer & int
Reverse Integer 想用余10直接算,没想到 -123%10 是 7, 原因 -123-(-123//10*10) r=a-n*[a/n] 以上,r是余数,a是被除数,n是除数. 唯一不同 ...
- 推荐算法 pd
from django.db import connection select_sql = 'select * from model' datas = pd.read_sql(select_sql, ...
- [Unity插件]Lua行为树(十一):组合节点Parallel
Parallel节点类似Sequence节点,不同在于Parallel会每帧执行所有的节点.当所有节点返回成功时返回成功,当其中一个节点返回失败时,返回失败并且结束所有的子节点运行. 例如说,给Seq ...
- 12.利用kakatips对网站数据信息监控
网站信息监控 kakatips软件 百度云链接:https://pan.baidu.com/s/1lNH8OGODbIvYeFTjz6kVEQ 密码:5qtz 这是我编辑好的具体详情如下: 有效标记需 ...