【Hadoop】搭建完全分布式的hadoop【转】
转自:http://www.cnblogs.com/laov/p/3421479.html
下面博文已更新,请移步 ↑
用于测试,我用4台虚拟机搭建成了hadoop结构
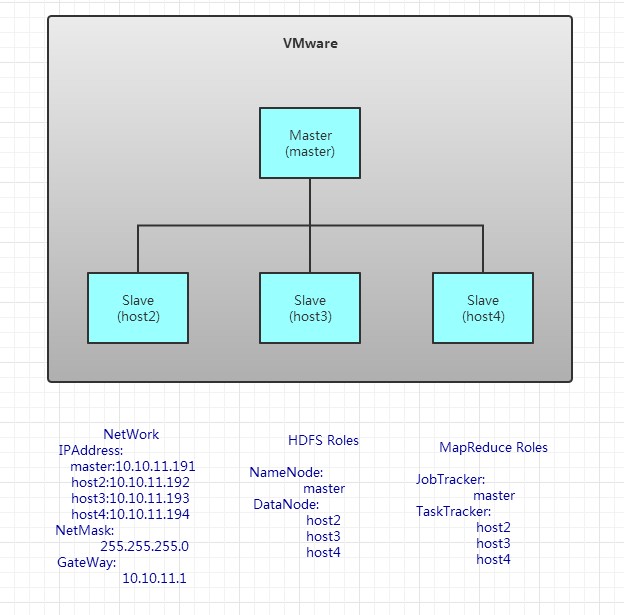
我用了两个台式机。一个xp系统,一个win7系统。每台电脑装两个虚拟机,要不然内存就满了。
1、安装虚拟机环境
Vmware,收费产品,占内存较大。
或
Oracle的VirtualBox,开源产品,占内存较小,但安装ubuntu过程中,重启会出错。
我选Vmware。
2、安装操作系统
Centos,红帽开源版,接近于生产环境。
Ubuntu,操作简单,方便,界面友好。
我选Ubuntu12.10.X 32位
3、安装一些常用的软件
在每台linux虚拟机上,安装:vim,ssh
sudo apt-get install vim
sudo apt-get install ssh
在客户端,也就是win7上,安装SecureCRT,Winscp或putty,这几个程序,都是依靠ssh服务来操作的,所以前提必须安装ssh服务。
service ssh status 查看ssh状态。如果关闭使用service ssh start开启服务。
SecureCRT,可以通过ssh远程访问linux虚拟机。
winSCP或putty,可以从win7向linux上传文件。
4、修改主机名和网络配置
主机名分别为:master,host2,host3,host4。
sudo vim /etc/hostname
网络配置,包括ip地址,子网掩码,DNS服务器。如上图所示。
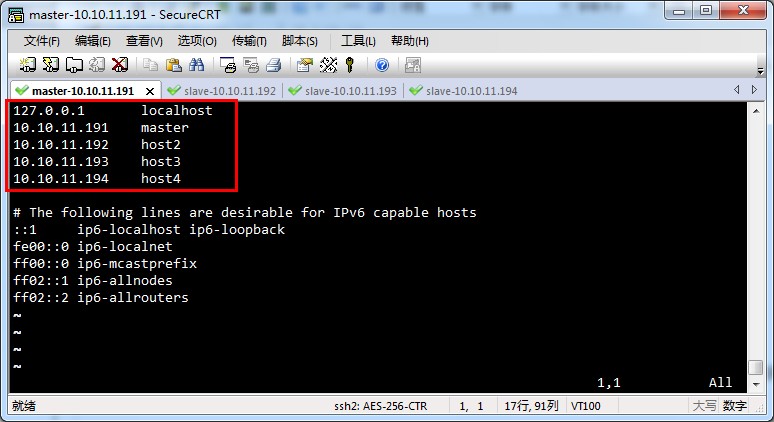
5、修改/etc/hosts文件。
修改每台电脑的hosts文件。
hosts文件和windows上的功能是一样的。存储主机名和ip地址的映射。
在每台linux上,sudo vim /etc/hosts 编写hosts文件。将主机名和ip地址的映射填写进去。编辑完后,结果如下:
6、配置ssh,实现无密码登陆
无密码登陆,效果也就是在master上,通过 ssh host2 或 ssh host3 或 ssh host4 就可以登陆到对方计算机上。而且不用输入密码。
四台虚拟机上,使用 ssh-keygen -t rsa 一路按回车就行了。
刚才都作甚了呢?主要是设置ssh的密钥和密钥的存放路径。 路径为~/.ssh下。
打开~/.ssh 下面有三个文件
authorized_keys,已认证的keys
id_rsa,私钥
id_rsa.pub,公钥 三个文件。
下面就是关键的地方了,(我们要做ssh认证。进行下面操作前,可以先搜关于认证和加密区别以及各自的过程。)
①在master上将公钥放到authorized_keys里。命令:sudo cat id_rsa.pub >> authorized_keys
②将master上的authorized_keys放到其他linux的~/.ssh目录下。
命令:sudo scp authorized_keys hadoop@10.10.11.192:~/.ssh
sudo scp authorized_keys 远程主机用户名@远程主机名或ip:存放路径。
③修改authorized_keys权限,命令:chmod 644 authorized_keys
④测试是否成功
ssh host2 输入用户名密码,然后退出,再次ssh host2不用密码,直接进入系统。这就表示成功了。
7、上传jdk,并配置环境变量。
通过winSCP将文件上传到linux中。将文件放到/usr/lib/java中,四个linux都要操作。
解压缩:tar -zxvf jdk1.7.0_21.tar
设置环境变量 sudo vim ~/.bashrc
在最下面添加:
export JAVA_HOME = /usr/lib/java/jdk1.7.0_21
export PATH = $JAVA_HOME/bin:$PATH
修改完后,用source ~/.bashrc让配置文件生效。
8、上传hadoop,配置hadoop
通过winSCP,上传hadoop,到/usr/local/下,解压缩tar -zxvf hadoop1.2.1.tar
再重命名一下,sudo mv hadoop1.2.1 hadoop
这样目录就变成/usr/local/hadoop
①修改环境变量,将hadoop加进去(最后四个linux都操作一次)
sudo vim ~/.bashrc
export HADOOP_HOME = /usr/local/hadoop
export PATH = $JAVA_HOme/bin:$HADOOP_HOME/bin:$PATH
修改完后,用source ~/.bashrc让配置文件生效。
②修改/usr/local/hadoop/conf下配置文件
hadoop-env.sh,
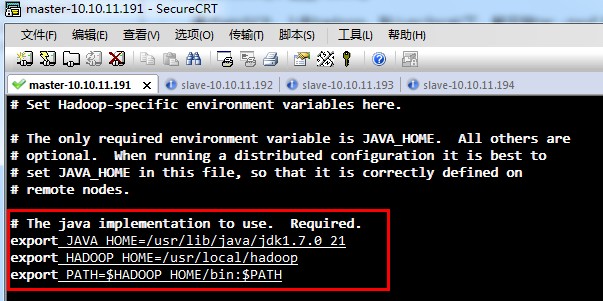
(上面这张图片,有一些问题,只export JAVA_HOME进去就可以了,不用export HADOOP_HOME和PATH了 )
core-site.xml,
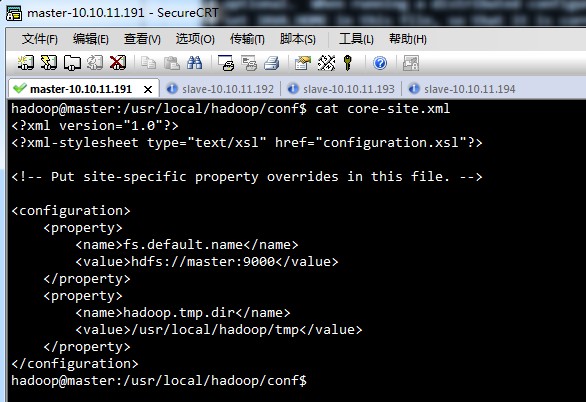
hdfs-site.xml,
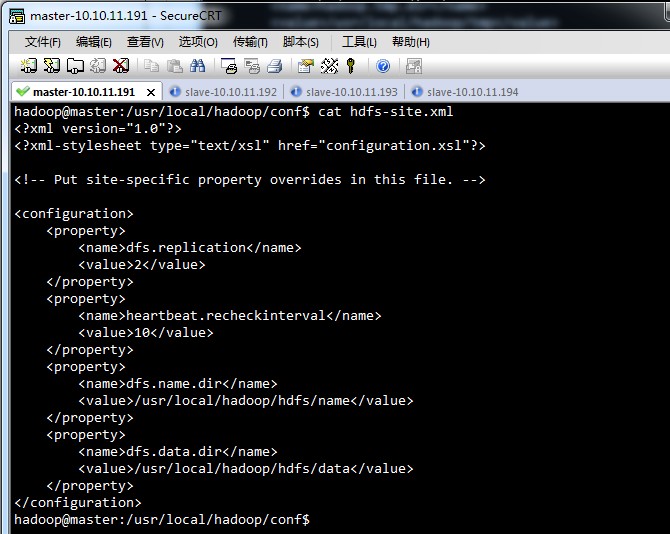
mapred-site.xml,

master,
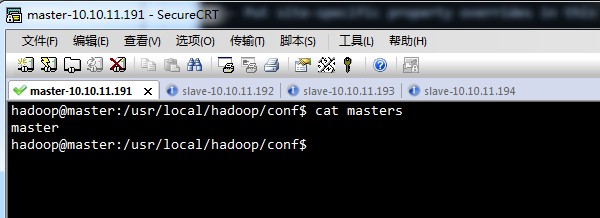
slave,

上面的hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,master,slave几个文件,在四台linux中都是一样的。
配置完一台电脑后,可以将hadoop包,直接拷贝到其他电脑上。
③最后要记得,将hadoop的用户加进去,命令为
sudo chown -R hadoop:hadoop hadoop
sudo chown -R 用户名@用户组 目录名
④让hadoop配置生效
source hadoop-env.sh
⑤格式化namenode,只格式一次
hadoop namenode -format
⑥启动hadoop
切到/usr/local/hadoop/bin目录下,执行 start-all.sh启动所有程序
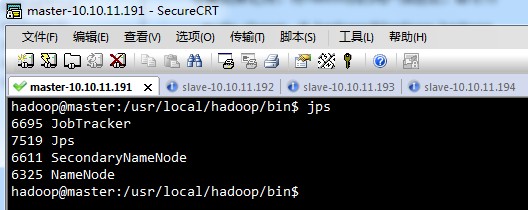
⑦查看进程,是否启动
jps
master,
host2,
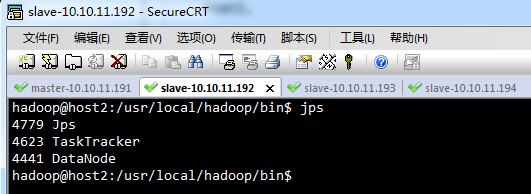
host3,host4,的显示结果,与host2相同。
【Hadoop】搭建完全分布式的hadoop【转】的更多相关文章
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- 【Hadoop】搭建完全分布式的hadoop
博客已转移,请借一步说话! http://www.weixuehao.com/archives/577 下面博文已更新,请移步 ↑ 用于测试,我用4台虚拟机搭建成了hadoop结构 我用了两个台式机. ...
- 搭建完全分布式的hadoop[转]
hadoop 创建用户及hdfs权限,hdfs操作等常用shell命令 sudo addgroup hadoop#添加一个hadoop组sudo usermod -a -G hadoop larry# ...
- Hadoop搭建完全分布式
ubuntu系统下: https://blog.csdn.net/u014636511/article/details/80171002 centos系统下: https://blog.csdn.ne ...
- Hadoop之伪分布式安装
一.Hadoop的安装模式有3种 ①单机模式:不能使用HDFS,只能使用MapReduce,所以单击模式主要用于测试MR程序. ②伪分布式模式:用多个线程模拟真实多台服务器,即模拟真实的完全分布式环境 ...
- Mac OS X上搭建伪分布式CDH版本Hadoop开发环境
最近在研究数据挖掘相关的东西,在本地 Mac 环境搭建了一套伪分布式的 hadoop 开发环境,采用CDH发行版本,省时省心. 参考来源 How-to: Install CDH on Mac OSX ...
- Hadoop的伪分布式搭建
我们在搭建伪分布式Hadoop环境,需要将一系列的配置文件配置好. 一.配置文件 1. 配置文件hadoop-env.sh export JAVA_HOME=/opt/modules/jdk1.7.0 ...
- hadoop备战:一台x86计算机搭建hadoop的全分布式集群
主要的软硬件配置: x86台式机,window7 64位系统 vb虚拟机(x86的台式机至少是4G内存,才干开3台虚机) centos6.4操作系统 hadoop-1.1.2.tar.gz jdk- ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
随机推荐
- 冲刺Two之站立会议1
今天我们开始了第二个冲刺期的工作,大家重新讨论了下个阶段的工作内容,由于上次演示我们主要只是实现了摄像头开启.通信和语音通话的功能,而且各部分还有待完善.所以我们决定了之后的主要工作的内容:之前服务器 ...
- order by null 的作用
在SQL中order by null有什么用吗?这是我在一次面试时面试官问我的问题,当时我是懵的.他让我猜一下,我说不排序?没想到被我猜对了 不排序你就别用order by啊!为什么要用order b ...
- DHCP分配固定IP
https://www.cnblogs.com/liu1026/p/9829337.html 按照上面的操作实验好后在DHCP服务端的配置文件中加入
- 使用 TListView 控件(4)
本例效果图: 代码文件: unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, ...
- 神奇的Redis延迟
最近在做某业务Redis的缩容工作,涉及到数据迁移,而Redis的数据迁移看起来蛮简单的,一对一的数据迁移只需要在slave行配置masterauth 和slaveof 两个参数即可,当然迁移过程中涉 ...
- Tyvj1038 忠诚 (线段树)
[Tyvj1038]忠诚 线段树 题目描述 老管家是一个聪明能干的人.他为财主工作了整整10年,财主为了让自已账目更加清楚.要求管家每天记k次账,由于管家聪明能干,因而管家总是让财主十分满意.但是 ...
- 洛谷P4382 [八省联考2018]劈配(网络流,二分答案)
洛谷题目传送门 说不定比官方sol里的某理论最优算法还优秀一点? 所以\(n,m\)说不定可以出到\(1000\)? 无所谓啦,反正是个得分题.Orz良心出题人,暴力有70分2333 思路分析 正解的 ...
- 【转】keil5 missing close quote 错误解决
在使用utf8保存文件的情况下,代码中出现中文字符串会提示missing close quote解决:Options for Target --> C/C++ --> Misc Contr ...
- 【JLOI 2012】时间流逝(期望,树上高斯消元)
题目链接 这是一道传统的期望题,可是有一些套路值得我去掌握. 我们用$s$来表示一种状态,就是当前拥有的能量圈,是一个正整数拆分的形式. 用$f_{s}$表示如果遇到果冻鱼后丢掉了最小的能量圈后的状态 ...
- [Coderforces600E] Lomsat gelral
大意是每个点有一个颜色,询问以每个点为根的子树中出现次数最多的颜色是谁,如果有多个输出编号和. 这个东西用数据结构是不太好做的,考虑优化暴力. 首先最裸的的暴力就是在dfs序上跑莫队,但因为是树的结构 ...