hive笔记:转义字符的使用
hive中的转义符
Hadoop和Hive都是用UTF-8编码的,所以, 所有中文必须是UTF-8编码, 才能正常使用
备注:中文数据load到表里面, 如果字符集不同,很有可能全是乱码需要做转码的, 但是hive本身没有函数来做这个
一、转义字符的特殊情况:
自身的转义,比如java有时候需要两个转义字符"\\",或者四个转义字符“\\\\”。
1)java的俩种情况:
a.正则表达式匹配和string的split函数,这两种情况中字符串包含转义字符“\”时,需要先对转义字符自身转义,就是说需要两个转义字符“\\”。比如\n,\t等(java解析后,再有正则和split自身特定进行解析)
b.而当匹配字符正斜线“\”,则需要四个转义字符“\\\\”,因为,首先java(编译器?)自身先解析,转义成两个“\\”,再由正则或split的解析功能转义成一个“\”,才是最终要处理的字符。
这是因为解析过程需要两次,才能在字符串中出现正斜线“\”,出现后才能转义后面的字符。
2)hive中的split和正则表达式
hive用java写的,所以同Java一样,两种情况也需要两个“\\”,
split处理代码为例:
a.split(dealid,'\\\\')[0] as dealids,1: 代码中,如果以“\”作为分隔符的话,那么就需要4个转义字符“\\\\”,即
b.split(all,'~') :这里切分符号是正则表达式,按一个字符分隔没问题
c. split(all,'[|~]+'): 在[]内部拼接成字符串
3)hive语句在shell脚本中执行
shell语言也有转义字符,自身直接处理。
而hive语句在shell脚本中执行时,就需要先由shell转义后,再由hive处理。这个过程又造成二次转义。
如上面的hive语句写入shell脚本中,执行是错误的,shell先解析,转义成”|“后传给hive,hive解析这个转义字符后,split就无法正确的解析了。
所以,注意hive语句在shell脚本执行时,转义字符需要翻倍。hive处理的是shell转义后的语句,必须转以后正确,才能执行。
注意:是否使用转义字符是看这个字符在这个语言中有没有特殊意义,有的话,就需要加上\来进行转义、
|
转义字符的使用: |
||||
|
转义字符 |
无转义符 |
转义符\ |
转义符\\ |
转义符\\\ |
|
" |
" |
\" |
\\” |
|
|
\ |
不可识别 |
不可识别 |
不可识别 |
\\\\ |
|
/ |
/ |
\/ |
\\/ |
\\\/ |
|
' |
不可识别 |
\' |
不可识别 |
\\\' |
|
~ |
~ |
\~ |
\\~ |
|
|
| |
| |
\| |
\\| |
\\\| |
|
; |
; |
\; |
\\; |
|
|
: |
: |
\: |
\\: |
|
|
, |
, |
\, |
\\, |
|
|
. |
. |
\. |
\\. |
|
|
! |
! |
\! |
\\! |
|
|
( |
( |
\( |
\\( |
|
|
) |
) |
\) |
\\) |
|
|
[ |
不可识别 |
不可识别 |
\\[ |
|
|
] |
] |
\] |
\\] |
|
|
{ |
{ |
\{' |
\\{ |
|
|
} |
} |
\} |
\\} |
|
|
? |
? |
\? |
\\? |
|
|
_ |
_ |
\_ |
\\_ |
|
|
- |
- |
\- |
\\- |
|
|
# |
# |
\# |
\\# |
|
|
## |
## |
\## |
\\## |
\\\## |
|
& |
& |
\& |
\\& |
|
|
^ |
^ |
\^ |
\\^ |
|
二、案例:原数据表
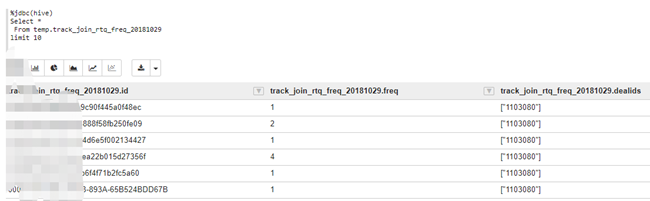
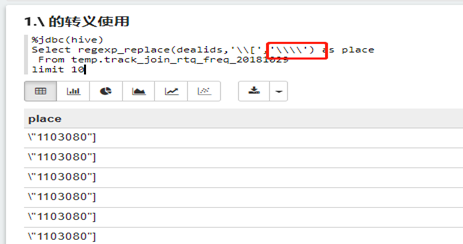
1.\符号
(1)regexp_replace(dealids,'\\[','\\\\')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','\\\\')
as place
From
temp.track_join_rtq_freq_20181029
limit 10
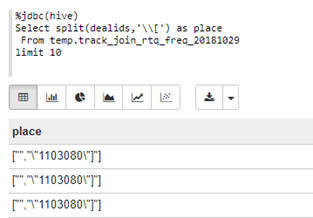
注意:


2.[与]符号
(1)\\[:split(dealids,'\\[')
%jdbc(hive)
Select split(dealids,'\\[') as place
From
temp.track_join_rtq_freq_20181029
limit 10
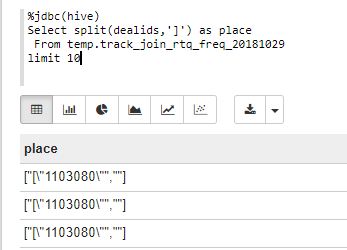
(2)]:split(dealids,']')
%jdbc(hive)
Select split(dealids,']') as place
From
temp.track_join_rtq_freq_20181029
limit 10
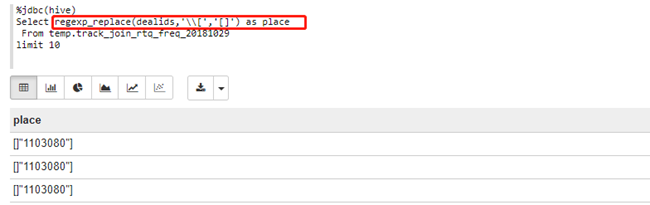
(3)\\[和[]:regexp_replace(dealids,'\\[','[]')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','[]') as place
From temp.track_join_rtq_freq_20181029
limit 10
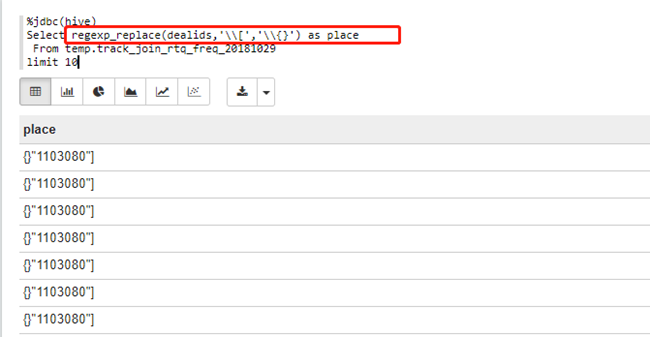
(4)\\[和\\{}:regexp_replace(dealids,'\\[','\\{}')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','\\{}')
as place
From
temp.track_join_rtq_freq_20181029
limit 10
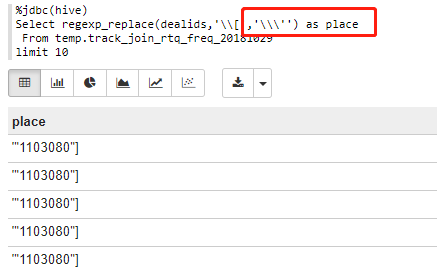
3.’符号
(1)\\\':regexp_replace(dealids,'\\[','\\\'')
%jdbc(hive)
Select regexp_replace(dealids,'\\[','\\\'') as place
From temp.track_join_rtq_freq_20181029
limit 10
hive笔记:转义字符的使用的更多相关文章
- Hive笔记--sql语法详解及JavaAPI
Hive SQL 语法详解:http://blog.csdn.net/hguisu/article/details/7256833Hive SQL 学习笔记(常用):http://blog.sina. ...
- Hive 笔记
DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees DESCRIBE EXTENDED mydb.employees ...
- hive笔记(自学整理的)
第一部分:用户管理 创建用户:CREATE DATABASE XXX 查看用户:SHOW DATABASES; 关键查看用户:show databases like 'de.*' 讲解:创建一个用 ...
- Hive笔记--配置以及遇到的问题
ubuntu安装mysql http://www.2cto.com/database/201401/273423.html Hive安装: http://www.aboutyun.com/forum ...
- Hive笔记——技术点汇总
目录 · 概况 · 手工安装 · 引言 · 创建HDFS目录 · 创建元数据库 · 配置文件 · 测试 · 原理 · 架构 · 与关系型数据库对比 · API · WordCount · 命令 · 数 ...
- hive笔记:复杂数据类型-map结构
map 结构 1. 语法:map(k1,v1,k2,v2,…) 操作类型:map ,map类型的数据可以通过'列名['key']的方式访问 案例: select deductions['Feder ...
- hive笔记
cast cast(number as string), 可以将整数转成字符串 lpad rpad lpad(target, 10, '0') 表示在target字符串前面补0,构成一个长度为 ...
- hive笔记:时间格式的统一
一.string类型,年月日部分包含的时间统一格式: 原数据格式(时间字段为string类型) 取数时间和格式的语法 2018-11-01 00:12:49.0 substr(regexp_repl ...
- hive笔记:复杂数据类型-array结构
array 结构 (1)语法:array(val1,val2,val3,…) 操作类型:array array类型的数据可以通过'数组名[index]'的方式访问,index从0开始: (2)建表: ...
随机推荐
- Redis 超时排查
突然收到告警,提示redis挂了,同时大群也在说某某redis连接超时了,过了一会儿就恢复了.这时登上服务器,查看监控.首先看看qps: 可以看到qps并不高,但是中间有段时间没取到数据是怎么回事?那 ...
- 关于Flutter初始化流程,我必须告诉你的是...
1. 引言 最近在做性能优化的时候发现,在混合栈开发中,第一次启动Flutter页面的耗时总会是第二次启动Flutter页面耗时的两倍左右,这样给人感觉很不好.分析发现第一次启动Flutter页面会做 ...
- Http协议中get和post的区别
get(默认值)是通过URL传递表单值,数据追加在action属性后面. post传递的表单值是隐藏到http报文体中,url中看不到. get是通过url传递表单值,post通过url看不到表单域的 ...
- 第7章 Linux上配置RAID
7.1 RAID概念 RAID独立磁盘冗余阵列(Redundant Array of Independent Disks),RAID技术是将许多块硬盘设备组合成一个容量更大.更安全的硬盘组,可以将数据 ...
- 走过路过不要错过 包你一文看懂支撑向量机SVM
假设我们要判断一个人是否得癌症,比如下图:红色得癌症,蓝色不得. 看一下上图,要把红色的点和蓝色的点分开,可以画出无数条直线.上图里黄色的分割更好还是绿色的分割更好呢?直觉上一看,就是绿色的线更好.对 ...
- Spring Boot入门(1)Hello World
Spring Boot介绍 对于熟悉Spring的读者读者来说,想必也听说过Spring Boot的大名,Spring Boot旨在简化Spring的开发,它涉及了Spring的方方面面,是一个令 ...
- 阿里分布式服务框架Dubbo的架构总结
Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解耦合(或者最大限度地松耦合).从服务模型的角度来看,Dubbo采用的是一种非常简单的模 ...
- java动态获取WebService的两种方式(复杂参数类型)
java动态获取WebService的两种方式(复杂参数类型) 第一种: @Override public OrderSearchListRes searchOrderList(Order_Fligh ...
- 现在有两个变量,分别是a = 3, b = 4,那么我们不用第三个变量来调换a和b的值。
现在有两个变量,分别是a = 3, b = 4,那么我们不用第三个变量来调换a和b的值. <!DOCTYPE html><html><head> <me ...
- 关于RecyclerView你知道的不知道的都在这了(下)
目录 目录 正文 6. Recycler 7. ItemAnimator 8. ItemDecoration 9. OnFlingListener 目录 由于本篇篇幅特长,特意做了个目录,让大伙对本篇 ...