pandas的一些
在具体谈及骚操作之前先捋一遍基本的统计特征函数
| 方法名 | 函数功能 | 所属库 |
| sum() | 计算数据样本的综合(按照列计算) | pandas |
| mean() | 计算数据样本的算术平均数 | pandas |
| var() | 计算样本的方差 | pandas |
| std() | 计算样本的标准差 | pandas |
| sample() | 计算样本的Spearman(Person)相关系数矩阵 | pandas |
| cov() | 计算样本的协方差矩阵 | pandas |
| skew | 样本值的偏度;偏度系数 | pandas |
| describe() | 给出样本的基本描述(比如均值、标准差等) | pandas |
| kurt() | 样本值的峰度;峰度系数 | pandas |
| median() | 样本值的中位数 | pandas |
| quantile() | 样本4分位数 |
import pandas as pd
df = pd.read_csv(r"C:\Users\lenovo\Desktop\HR.csv")
>>> satisfaction_level last_evaluation ... department salary
0 0.38 0.53 ... sales low
1 0.80 0.86 ... sales medium
2 0.11 0.88 ... sales medium
3 0.72 0.87 ... sales low
4 0.37 0.52 ... sales low
5 0.41 0.50 ... sales low
6 0.10 0.77 ... sales low
7 0.92 0.85 ... sales low
8 0.89 1.00 ... sales low
9 0.42 0.53 ... sales low
10 0.45 0.54 ... sales low
11 0.11 0.81 ... sales low
12 0.84 0.92 ... sales low
13 0.41 0.55 ... sales low
14 0.36 0.56 ... sales low
首先是df.mean()
satisfaction_level 0.612839
last_evaluation 67.373732
number_project 3.802693
average_monthly_hours 201.041728
time_spend_company 3.498067
Work_accident 0.144581
left 0.238235
promotion_last_5years 0.021264
dtype: float64
df["satisfaction_level"].mean()
0.6128393333333333
df.quantile(q=0.25)
satisfaction_level 0.44
last_evaluation 0.56
number_project 3.00
average_monthly_hours 156.00
time_spend_company 3.00
Work_accident 0.00
left 0.00
promotion_last_5years 0.00
Name: 0.25, dtype: float64
df["satisfaction_level"].skew() # 偏态系数
Out[9]: -0.47643761717258093
df["satisfaction_level"].kurt() # 峰态系数
Out[10]: -0.6706959323886252
df.sample(n=10) # 给df进行抽样10个
Out[11]:
satisfaction_level last_evaluation ... department salary
12624 0.38 0.50 ... sales low
12343 0.41 0.56 ... technical medium
12214 0.40 0.53 ... IT low
3607 0.64 0.66 ... sales medium
11808 0.69 0.90 ... product_mng low
6604 0.19 0.85 ... technical low
6471 0.60 0.82 ... IT low
6447 0.52 0.51 ... technical high
535 0.37 0.56 ... sales medium
10989 0.17 0.55 ... RandD low
df.sample(frac=0.01) # 给df进行抽样率为0.01
Out[12]:
satisfaction_level last_evaluation ... department salary
223 0.87 0.90 ... IT low
9683 0.56 0.83 ... IT medium
5586 0.81 0.99 ... sales medium
12269 0.38 0.86 ... technical medium
208 0.44 0.50 ... support low
1412 0.46 0.46 ... technical low
11713 0.63 0.98 ... management high
10660 0.83 0.74 ... support medium
1757 0.36 0.51 ... sales low
14994 0.40 0.57 ... support low
1238 0.66 1.00 ... sales medium
基本方法就先演示这几个
骚操作一:
shift方法:
首先通过df.shift?方法来了解一下
Examples
--------
df = pd.DataFrame({'Col1': [10, 20, 15, 30, 45],
'Col2': [13, 23, 18, 33, 48],
'Col3': [17, 27, 22, 37, 52]})
df.shift(periods=3)
Col1 Col2 Col3
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 10.0 13.0 17.0
4 20.0 23.0 27.0
df.shift(periods=1, axis='columns')
Col1 Col2 Col3
0 NaN 10.0 13.0
1 NaN 20.0 23.0
2 NaN 15.0 18.0
3 NaN 30.0 33.0
4 NaN 45.0 48.0
df.shift(periods=3, fill_value=0)
Col1 Col2 Col3
0 0 0 0
1 0 0 0
2 0 0 0
3 10 13 17
4 20 23 27
File: c:\users\lenovo\appdata\roaming\python\python36\site-packages\pandas\core\frame.py
Type: method
可以知道periods参数是用来控制移动的距离;axis是用来控制列移动还是行移动,fill_value是用来控制因为移动数据产生的NAN用什么来进行填充

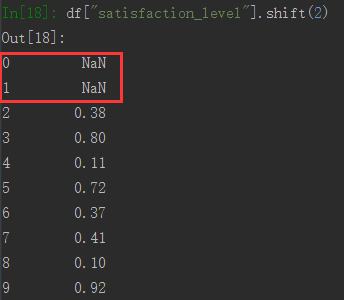 可以看到数据是集体向下移动的
可以看到数据是集体向下移动的
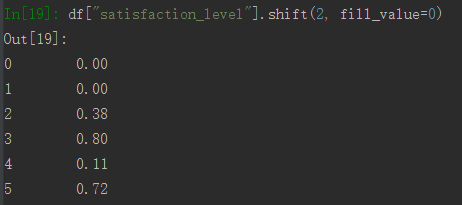 加上fill_value参数就会变成0了
加上fill_value参数就会变成0了
如果需要用到隔行相减的情况就派上用场了
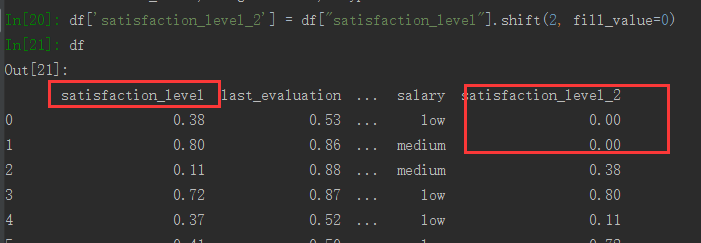
除了shift还有累计计算(cum)和滚动计算(pd.rolling)
| 方法名 | 函数功能 | 所属库 |
| cumsum() | 依次给出前1,2,3……n个数的和 | pandas |
| cumprod() | 依次给出前1,2,3……n个数的积 | pandas |
| cummax() | 依次给出前1,2,3……n个数的最大 | pandas |
| cummin() | 依次给出前1,2,3……n个数的最小 | pandas |
| 方法名 | 函数功能 | 所属库 |
| rolling_sum() | 计算数据样本的总和(按列计算) | Pandas |
| rolling_mean() | 数据样本的算术平均数 | Pandas |
| rolling_var() | 计算数据样本的方差 | Pandas |
| rolling_std() | 计算数据样本的标准差 | Pandas |
| rolling_corr() | 计算数据样本的Spearman(Pearson)相关系数矩阵 | Pandas |
| rolling_cov() | 计算数据样本的协方差矩阵 | Pandas |
| rolling_skew() | 样本值的偏度 | Pandas |
| rolling_kurt() | 样本值得峰度 | Pandas |
其中,cum系列函数是作为DataFrame或者是Series对象的方法而出现的,因此命令格式为D.cumsum(),但是rolling系列是pandas的函数,并不是DataFrame或者Series对象的方法,因此他们的使用格式为pd.rolling_mean(D,k),意思为每K列计算一次平均值,滚动计算。
pandas的一些的更多相关文章
- pandas基础-Python3
未完 for examples: example 1: # Code based on Python 3.x # _*_ coding: utf-8 _*_ # __Author: "LEM ...
- 10 Minutes to pandas
摘要 一.创建对象 二.查看数据 三.选择和设置 四.缺失值处理 五.相关操作 六.聚合 七.重排(Reshaping) 八.时间序列 九.Categorical类型 十.画图 十一 ...
- 利用Python进行数据分析(15) pandas基础: 字符串操作
字符串对象方法 split()方法拆分字符串: strip()方法去掉空白符和换行符: split()结合strip()使用: "+"符号可以将多个字符串连接起来: join( ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- pandas.DataFrame对行和列求和及添加新行和列
导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFra ...
- pandas.DataFrame排除特定行
使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame 如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列 ...
随机推荐
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- Webpack 学习总结
1.Webpack的特性 webpack 模块打包机,分析你的项目结构,找到JavaScript模块以及其他一些浏览器不能直接运行的拓展语言(Scss,TypeScript等),将其打包为合适的格式以 ...
- CefSharp 与 js 相互调用
https://blog.csdn.net/gong_hui2000/article/details/48155547
- MemCache在网站中的使用
MemCache安装好后,网站一直没法使用,后来查找资料,发现需要在配置文件里写几行代码,如下所示 <enyim.com> <memcached protocol="Tex ...
- 随手用JQ写个选项卡
<div class="box"> <ul> <li class="one">选项卡1</li> <li& ...
- [php]php设计模式 (总结)
转载自[php]php设计模式 (总结) 传统的23种模式(没有区分简单工厂与抽象工厂) http://www.cnblogs.com/bluefrog/archive/2011/01/04/1925 ...
- Jacey:烧了500万才知道,信息流广告OCPC竟然要这样玩!心疼
现在很多线索类广告主,已经不满足于表单.在线咨询等获客方式,随着微商的火热,很多行业都玩起了个人微信号加粉的方式来获取潜在消费者. 随着手机的普遍,移动流量呈大幅上涨趋势,越来越多广告主将目光投向了信 ...
- appium 使用环境安装配置记录
一.安装配置Java (cmd输入java,回车,没有出现“不是内部或外部命令,也不是可运行的程序或批处理文件”,即为成功) 二.安装node.js (cmd输入node -v,显示版本号即为成功) ...
- java面试题复习(一)
//基础最重要,如果面试官问一个答不上一个,那有难度的都都不用问了,直接就pass了,就像我,嘿嘿. //每天最好熟记10个问题,这些问题在编程是会很厚帮助,帮你避免很多不应该出现的错误. 一.面向对 ...
- ssh 使用技巧
参考:https://deepzz.com/post/how-to-setup-ssh-config.html SSH Config 那些你所知道和不知道的事 预览目录 配置项说明 相关技巧 管理多组 ...