HDFS-HA高可用 | Yarn-HA
HDFS-HA
HA(High Available),即高可用(7*24小时不中断服务)
单点故障即有一台机器挂了导致全部都挂了;HA就是解决单点故障,就是针对NameNode;
主Active:读写、从standby只读;所依赖的服务都必须是高可用的;
两种解决共享空间的方案:NFS、QJM(主流的)

奇数台机器;QJM跟zookeeper(数据全局一致;半数以上的机器存活就可以提供服务)高可用的方式一模一样,;
QJM也是基于Paxos算法,系统容错不能超过n-1/2, 5台容错2台;
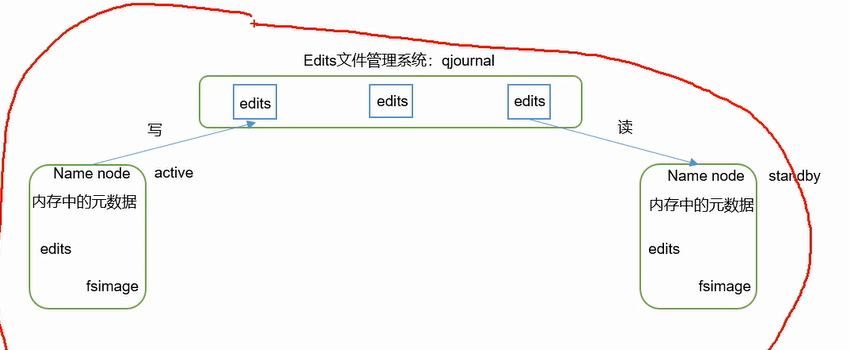
这个架构只能手动决定哪个是active哪个是standby;必须只能有一个active!!如果出现两个NameNode,即两个都是active,它可能还不报错,那么可能会导致整个集群的数据都是错的,问题很严重!两个AA的情况叫脑裂(split brain缩写sb)。
standby要想变成active,要确保active那个,需要安全可靠的zookeeper(文件系统+通知机制)第三方来联系两方 ---> 实现故障的自动转移;
由Zkfc来联系zookeeper,并不是namenode直接联系,(zookeeper客户端);HA是hadoop2.0才有的,namenode在1.0时就有了;没有把zkfc写进namenode是为了保持NameNode的健壮性,没有zkfc之前就已经运行的很好了(鲁棒性);NameNode和Zkfc虽然是两个进程但它们是绑定到一起的。
两个zkfc怎么决定谁初始化就是active呢,谁快谁就是active; 是active状态它会在zookeeper中有一个临时节点,zkfc会尝试看看zookeeper中有没有这个临时节点,如果没有我就变成这个临时节点,成为active,慢的一看有了,就变成standby;
NameNode发生假死,zkfc就会把zookeeper中的临时节点删除,去通知另外一个namenode的zkfc,让它去成为active,这个namenode就会去强行杀死假死的namenode,防止脑裂!如果杀不死就自定义一个脚本强制它关机,成功之后才会变成active。
现在合并fsimage是由standby来完成的,没有secondaryNameNode;
在module目录下创建一个ha文件夹
mkdir ha 将/opt/module/下的 hadoop-2.7.2拷贝到/opt/module/ha目录下
cp -r hadoop-2.7.2/ /opt/module/ha/
删除data logs等文件
配置core-site.xml
<configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/ha/hadoop-2.7.2/data/tmp</value>
</property> <property>
<name>ha.zookeeper.quorum</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property> </configuration>
配置hdfs-site.xml
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property> <!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property> <!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop101:9000</value>
</property> <!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop102:9000</value>
</property> <!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop101:50070</value>
</property> <!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop102:50070</value>
</property> <!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop101:8485;hadoop102:8485;hadoop103:8485/mycluster</value>
</property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/kris/.ssh/id_rsa</value>
</property> <!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/ha/hadoop-2.7.2/data/jn</value>
</property> <!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> </configuration>
发送到其他机器
xsync ha
启动HDFS-HA集群
. 在各个JournalNode节点上,输入以下命令启动journalnode服务
sbin/hadoop-daemons.sh start journalnode //加个s就可以3台一块启动;都启动之后才能格式化namenode;只能格式化一次!
. 在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format
// :: INFO util.GSet: Computing capacity for map NameNodeRetryCache
// :: INFO util.GSet: VM type = -bit
// :: INFO util.GSet: 0.029999999329447746% max memory MB = 273.1 KB
// :: INFO util.GSet: capacity = ^ = entries
// :: INFO namenode.FSImage: Allocated new BlockPoolId: BP--192.168.1.101-
// :: INFO common.Storage: Storage directory /opt/module/ha/hadoop-2.7./data/tmp/dfs/name has been successfully formatted.
// :: INFO namenode.NNStorageRetentionManager: Going to retain images with txid >=
// :: INFO util.ExitUtil: Exiting with status
// :: INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop101/192.168.1.101
************************************************************/
启动namenode: sbin/hadoop-daemon.sh start namenode . 在[nn2]上,同步nn1的元数据信息
bin/hdfs namenode -bootstrapStandby
......
STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on --22T10:49Z
STARTUP_MSG: java = 1.8.0_144
************************************************************/
// :: INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
// :: INFO namenode.NameNode: createNameNode [-bootstrapStandby]
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: mycluster
Other Namenode ID: nn1
Other NN's HTTP address: http://hadoop101:50070
Other NN's IPC address: hadoop101/192.168.1.101:9000
Namespace ID:
Block pool ID: BP--192.168.1.101-
Cluster ID: CID-d20dda0d-49d1-48f4-b9e8-2c99b72a15c2
Layout version: -
isUpgradeFinalized: true
=====================================================
// :: INFO common.Storage: Storage directory /opt/module/ha/hadoop-2.7./data/tmp/dfs/name has been successfully formatted.
// :: INFO namenode.TransferFsImage: Opening connection to http://hadoop101:50070/imagetransfer?getimage=1&txid=0&storageInfo=-63:1640720426:0:CID-81cbaa0d-6a6f-4932-98ba-ff2a46d87514
// :: INFO namenode.TransferFsImage: Image Transfer timeout configured to milliseconds
// :: INFO namenode.TransferFsImage: Transfer took .02s at 0.00 KB/s
// :: INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size bytes.
// :: INFO util.ExitUtil: Exiting with status
// :: INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop102/192.168.1.102
************************************************************/
出现这个信息是:(只需格式化一次;)
Re-format filesystem in Storage Directory /opt/module/ha/hadoop-2.7.2/data/tmp/dfs/name ? (Y or N) N
Format aborted in Storage Directory /opt/module/ha/hadoop-2.7.2/data/tmp/dfs/name
19/02/21 19:06:50 INFO util.ExitUtil: Exiting with status 5 ##这个是退出状态!
19/02/21 19:06:50 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop102/192.168.1.102
************************************************************/
. 启动[nn2]
sbin/hadoop-daemon.sh start namenode
. 在[nn1]上,启动所有datanode; hadoop-daemons.sh是3台都启动datanode
sbin/hadoop-daemons.sh start datanode
################手动切换namenode
. 将[nn1]切换为Active
bin/hdfs haadmin -transitionToActive nn1
. 查看是否Active
bin/hdfs haadmin -getServiceState nn1 http://hadoop101:50070/dfshealth.html#tab-overview
http://hadoop102:50070/dfshealth.html#tab-overview
配置HDFS-HA自动故障转移(直接启动不需先按手动的启动方式)
配置好自动故障转移后手动模式就不可用了
Automatic failover is enabled for NameNode at hadoop102/192.168.1.102:
Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state.
If you are very sure you know what you are doing, please
specify the --forcemanual flag.
配置HDFS-HA自动故障转移
. 具体配置 ;在上个基础上添加如下:
()在hdfs-site.xml中增加
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
()在core-site.xml文件中增加
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop101:,hadoop102:,hadoop103:</value>
</property>
. 启动
()关闭所有HDFS服务:
sbin/stop-dfs.sh
()启动Zookeeper集群:
bin/zkServer.sh start
()初始化HA在Zookeeper中状态:(只初始化一次)
bin/hdfs zkfc -formatZK // :: INFO zookeeper.ClientCnxn: Socket connection established to hadoop102/192.168.1.102:, initiating session
// :: INFO zookeeper.ClientCnxn: Session establishment complete on server hadoop102/192.168.1.102:, sessionid = 0x268e2dee6e40000, negotiated timeout =
// :: INFO ha.ActiveStandbyElector: Session connected.
// :: INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.
// :: INFO zookeeper.ZooKeeper: Session: 0x268e2dee6e40000 closed
// :: INFO zookeeper.ClientCnxn: EventThread shut down ()启动HDFS服务:
sbin/start-dfs.sh hadoop101: starting namenode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-namenode-hadoop101.out
hadoop102: starting namenode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-namenode-hadoop102.out
hadoop102: starting datanode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-datanode-hadoop102.out
hadoop101: starting datanode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-datanode-hadoop101.out
hadoop103: starting datanode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-datanode-hadoop103.out
Starting journal nodes [hadoop101 hadoop102 hadoop103]
hadoop103: starting journalnode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-journalnode-hadoop103.out
hadoop102: starting journalnode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-journalnode-hadoop102.out
hadoop101: starting journalnode, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-journalnode-hadoop101.out
Starting ZK Failover Controllers on NN hosts [hadoop101 hadoop102]
hadoop101: starting zkfc, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-zkfc-hadoop101.out
hadoop102: starting zkfc, logging to /opt/module/ha/hadoop-2.7./logs/hadoop-kris-zkfc-hadoop102.out . 验证
()将Active NameNode进程kill
kill - namenode的进程id ---> 另外一个namenode上位;( 杀掉之后,可单独启动: sbin/hadoop-daemon.sh start namenode,启动之后它不会变成之前的active;而是standby)
() 将DFSZKFailoverController的进程kill
kill - --->尽管它的namenode没有挂,但另外一个namenode也会上位,它变成standby
再启动它要先停止->sbin/stop-dfs.sh sbin/start-dfs.sh
()将Active NameNode机器断开网络
sudo service network stop ---> 把网络断开之后,配的隔离机制是sshfence尝试远程登录区杀敌hadoop101,直到把101网络连接上才杀死,102才成为active;
断网上位很容易脑裂,那边网已恢复就炸了;如果真的断网,它这个是不会自动切的是为了防脑裂。虽然可以通过配置断网可以直接上,但很危险;断网上不去反而安全。
[zk: localhost:(CONNECTED) ] ls /
[zookeeper, hadoop-ha]
[zk: localhost:(CONNECTED) ] ls /
[zookeeper, hadoop-ha]
[zk: localhost:(CONNECTED) ] ls /hadoop-ha
[mycluster]
[zk: localhost:(CONNECTED) ] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock] 选举的关键节点,谁占领了这个节点谁就是active;
[zk: localhost:(CONNECTED) ] get /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn1 hadoop101 �F(�>
cZxid = 0x10000000f
ctime = Wed Feb :: CST
mZxid = 0x10000000f
mtime = Wed Feb :: CST
pZxid = 0x10000000f
cversion =
dataVersion =
aclVersion =
ephemeralOwner = 0x268e2dee6e40002 临时节点,
dataLength =
numChildren =
进程
hadoop101 hadoop102 hadoop103
NameNode NameNode
JournalNode JournalNode JournalNode
DataNode DataNode DataNode
DFSZKFailoverController DFSZKFailoverController ZooKeeperMain(bin/zkCli.sh ,启动zookeeperd客户端)
ResourceManager ResourceManager
NodeManager NodeManager NodeManager QuorumPeerMain QuorumPeerMain QuorumPeerMain (bin/zkServer.sh start 启动zookeeper服务器) DFSZKFailoverController是Hadoop-2.7.0中HDFS NameNode HA实现的中心组件,它负责整体的故障转移控制等。
它是一个守护进程,通过main()方法启动,继承自ZKFailoverController。 zkfc
使用JournalNode实现两个NameNode(Active和Standby)之间数据的共享
YARN-HA配置
YARN-HA工作机制
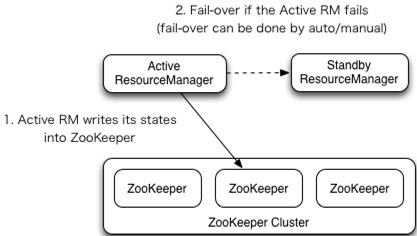
Yarn原生根zookeeper兼容很好,配置比较简单;
配置YARN-HA集群
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> //混合服务还是shuffle,用shuffle确定reducer获取数据的方式
</property> <!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property> <!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property> <property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property> <property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop101</value>
</property> <property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop102</value>
</property> <!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop101:2181,hadoop102:2181,hadoop103:2181</value>
</property> <!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property> <!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
yarn-site.xml 在hadoop101中配置好将其分发到其他机器:xsync etc/
启动zookeeper;3台其他都启动;
[kris@hadoop101 ~]$ /opt/module/zookeeper-3.4./bin/zkServer.sh start
启动hdfs
sbin/start-dfs.sh 启动YARN
()在hadoop101中执行:
sbin/start-yarn.sh
[kris@hadoop101 hadoop-2.7.]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/ha/hadoop-2.7./logs/yarn-kris-resourcemanager-hadoop101.out
hadoop101: starting nodemanager, logging to /opt/module/ha/hadoop-2.7./logs/yarn-kris-nodemanager-hadoop101.out
hadoop103: starting nodemanager, logging to /opt/module/ha/hadoop-2.7./logs/yarn-kris-nodemanager-hadoop103.out
hadoop102: starting nodemanager, logging to /opt/module/ha/hadoop-2.7./logs/yarn-kris-nodemanager-hadoop102.out ()在hadoop102中执行:
sbin/yarn-daemon.sh start resourcemanager //脚本只在上面一台上启动了,hadoop102上的resourcemanager要手动启;
[kris@hadoop102 hadoop-2.7.]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/ha/hadoop-2.7./logs/yarn-kris-resourcemanager-hadoop102.out ()查看服务状态
bin/yarn rmadmin -getServiceState rm1 //rm1就是hadoop101; rm2为hadoop102
[kris@hadoop102 hadoop-2.7.]$ bin/yarn rmadmin -getServiceState rm1
active
[kris@hadoop102 hadoop-2.7.]$ bin/yarn rmadmin -getServiceState rm2
standby ################
hdfs-ha & yarn-ha
[kris@hadoop101 hadoop-2.7.]$ jpsall
-------hadoop101-------
ResourceManager
NodeManager
NameNode
Jps
QuorumPeerMain
DFSZKFailoverController
DataNode
JournalNode
-------hadoop102-------
NameNode
ResourceManager
JournalNode
DFSZKFailoverController
DataNode
QuorumPeerMain
Jps
NodeManager
-------hadoop103-------
Jps
JournalNode
QuorumPeerMain
NodeManager
DataNode
http://hadoop101:8088/cluster http://hadoop102:8088/cluster -->它会重定向到hadoop101
HDFS-HA高可用 | Yarn-HA的更多相关文章
- HDFS namenode 高可用(HA)搭建指南 QJM方式 ——本质是多个namenode选举master,用paxos实现一致性
一.HDFS的高可用性 1.概述 本指南提供了一个HDFS的高可用性(HA)功能的概述,以及如何配置和管理HDFS高可用性(HA)集群.本文档假定读者具有对HDFS集群的组件和节点类型具有一定理解.有 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- Hdfs的HA高可用
1.Hdfs的HA高可用:保证Hdfs高可用,其实就是保证namenode的高可用,保证namenode的高可用的机制有两个,editlog共享机制+ZKFC.ZKFC就是ZookeeperFailO ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
- 大数据技术之HA 高可用
HDFS HA高可用 1.1 HA概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA ...
随机推荐
- vue.js插槽
具体讲解的url https://github.com/cunzaizhuyi/vue-slot-demo //例子 用jsfiddle.net去运行就好 <!DOCTYPE html> ...
- git bash的命令
git bash cd /f 该命令可以把当前目录切换到f盘 git clone git上的项目的url
- linux流量异常查看哪些程序占用的
Linux下进程/程序网络带宽占用情况查看工具 -- NetHogs http://www.vpser.net/manage/nethogs.html 来自. 最后略有修改 之前VPS侦探曾 ...
- MSChart的研究(转)
介绍MSChart的常用属性和事件 MSChart的元素组成 最常用的属性包括 ChartAreas:增加多个绘图区域,每个绘图区域包含独立的图表组.数据源,用于多个图表类型在一个绘图区不兼容时. A ...
- PID控制器开发笔记之十一:专家PID控制器的实现
前面我们讨论了经典的数字PID控制算法及其常见的改进与补偿算法,基本已经覆盖了无模型和简单模型PID控制经典算法的大部.再接下来的我们将讨论智能PID控制,智能PID控制不同于常规意义下的智能控制,是 ...
- java 中int与integer的区别
int与integer的区别从大的方面来说就是基本数据类型与其包装类的区别: int 是基本类型,直接存数值,而integer是对象,用一个引用指向这个对象 1.Java 中的数据类型分为基本数据类型 ...
- socket-WebSocket-HttpListener-TcpListener服务端客户端的具体使用案例
/// <summary> /// 启动服务监听的ip和端口的主线程 /// </summary> /// <param name="tunnelPort&qu ...
- 简化版的AXI-LITE4和配合使用的RTL
////////////////////////////////////////////////////////////////////////////////// // // The ZYNQ FI ...
- LeetCode(120):三角形最小路径和
Medium! 题目描述: 给定一个三角形,找出自顶向下的最小路径和.每一步只能移动到下一行中相邻的结点上. 例如,给定三角形: [ [2], [3,4], [6,5,7], [4,1,8,3] ] ...
- 动手动脑——JAVA语法基础
EnumTest.java public class EnumTest { public static void main(String[] args) { Size s=Size.SMALL; Si ...