scrapy架构简介
一.scrapy架构介绍
1.结构简图:
主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine
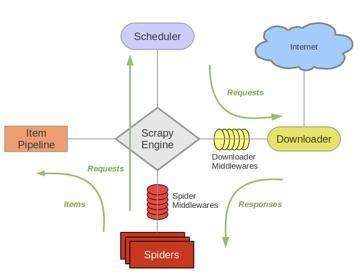
2.结构详细图:
主要步骤(往复循环):
1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——>
2.engine拿到requests返回给scheduler(什么也没做)——>
3.然后scheduler会生成一个requests交给engine(url调度器)——>
4.engine通过downloader的middleware一层一层过滤然后将requests交给downloader——>
5.downloader下载完成后又通过middleware过滤将response返回给engine——>
6.engine拿到response之后将response通过spiders的middleware过滤后返回给spider,然后spider做一些处理(如返回items或requests)——>
7.spiders将处理后得到的一些items和requests通过中间件过滤返回给engine——>
8.engine判断返回的是items或requests,如果是items就直接返回给item pipelines,如果是requests就将requests返回给scheduler(和第二步一样)

源码简介:
源码核心的东西
engine.py中介绍:通过_next_request_from_scheduler判断是否有requests(request返回给engine直接返回给scheduler【第一步】),request会首先调用schedule()函数发送给schedule(第二步),然后返回给engine
downloader简介:

可以处理很多类型的下载
Request和Response简介:
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None):
......
官网介绍(具体官网网址:https://doc.scrapy.org/en/latest/topics/request-response.html):
| 参 数: |
|
|---|
class Response(object_ref):
def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None):
self.headers = Headers(headers or {})
self.status = int(status)
self._set_body(body)
self._set_url(url)
self.request = request
self.flags = [] if flags is None else list(flags)
......
| 参数: |
|
|---|
scrapy架构简介的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- LoadRunner系统架构简介
1.LoadRunner系统架构简介 LoadRunner是通过创建虚拟用户来代替真实实际用户来操作客户端软件比如Internet Explorer,来向IIS.Apache等Web服务器发送HTTP ...
- crtmpserver的架构简介
crtmpserver的架构简介 一.层 Layers . 机器层 Machine layer . 操作系统层 Operating System Layer This layer is compo ...
- Extjs6官方文档译文——应用架构简介(MVC,MVVM)
应用架构简介 Extjs 同时提供对于MVC和MVVM应用架构的支持.这两个架构方式共享某些概念,而且都旨在沿着逻辑层面划分应用程序代码.每种方法在选择如何划分应用组件上都有其各自的优势. 本指南的目 ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Scrapy架构概述
Scrapy架构概述 1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象. 2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器) ...
- Kafka:架构简介【转】
转:http://www.cnblogs.com/f1194361820/p/6026313.html Kafka 架构简介 Kafka是一个开源的.分布式的.可分区的.可复制的基于日志提交的发布订阅 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- Python -- Scrapy 架构概览
架构概览 本文档介绍了Scrapy架构及其组件之间的交互. 概述 接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详 ...
随机推荐
- vue组件详解——使用props传递数据
每天学习一点点 编程PDF电子书.视频教程免费下载:http://www.shitanlife.com/code 在 Vue 中,父子组件的关系可以总结为 props向下传递,事件向上传递.父组件通过 ...
- day10--函数之形参与实参
''' def fn(形参们): pass fn(实参们) ''' # 形参:定义函数,在括号内声明的变量名,用来结束外界传来的值 # 实参:调用函数,在括号内传入的实际值,值可以为常量.变量.表达式 ...
- python之函数、参数、作用域、递归
函数的定义 函数也就是带名字的代码块.使用关键字def来定义,指出函数名及参数,以冒号结尾. def fibs(num): result =[0,1] for i in range(num-2): r ...
- item 23: 理解std::move和std::forward
本文翻译自<effective modern C++>,由于水平有限,故无法保证翻译完全正确,欢迎指出错误.谢谢! 博客已经迁移到这里啦 根据std::move和std::forward不 ...
- LeetCode264:Ugly Number II
自己的做法超时了.主要是每次生成一个数据,保存到list中,然后对List重新排序.排序太耗费时间 记录下讨论组里的写法 public int NthUglyNumber(int n) { int[] ...
- 性能调优7:多表连接 - join
在产品环境中,往往存在着大量的表连接情景,不管是inner join.outer join.cross join和full join(逻辑连接符号),在内部都会转化为物理连接(Physical Joi ...
- centos中docker的安装
之前学习docker的时候,是在windows上直接使用可执行文件安装的,最近需要在自己的服务器上安装docker,特此了解了一下如何安装,这里补一下. 小白学Docker之基础篇 小白学Docker ...
- flask 跨域请求
Flask中,跨域请求主要有两种方式: 1.在响应头信息中添加允许跨域 如下,使用装饰器app.after_request(我这里的web是定义的蓝图),这样在每次请求后,加入header 2.使用第 ...
- 微软是如何让我再次爱上.Net Core和C#的
“为什么你还想用ASP.NET,难道你还活在90年代吗?”这正是我的一位老同事在几年前我们即将开始的项目中我提出考虑使用ASP.NET时所说的话.当时我很大程度上认同他的看法,微软已经开发了伟大的开发 ...
- python第三章:循环语句--小白博客
Python条件语句 Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块. 可以通过下图来简单了解条件语句的执行过程: Python程序语言指定任何非0和非 ...