Python -- Scrapy 架构概览
架构概览
本文档介绍了Scrapy架构及其组件之间的交互。
概述
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
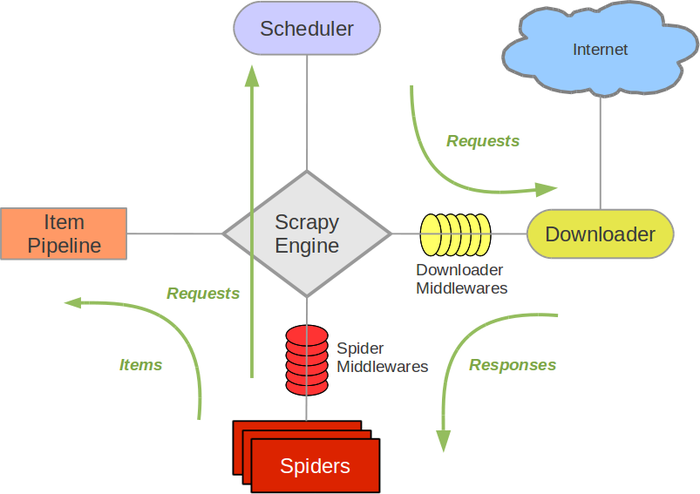
组件
引擎(Scrapy Engine)
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
爬虫(Spiders)
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
项目管道(Item Pipeline)
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
事件驱动网络(Event-driven networking)
Scrapy基于事件驱动网络框架 Twisted 编写。因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
关于异步编程及Twisted更多的内容请查看下列链接:
Python -- Scrapy 架构概览的更多相关文章
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Python——Scrapy初学
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中.Scrapy最初是为了页面抓取(更确切来说, 网络抓取)所设计的,也 ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- python Scrapy 从零开始学习笔记(一)
在之前我做了一个系列的关于 python 爬虫的文章,传送门:https://www.cnblogs.com/weijiutao/p/10735455.html,并写了几个爬取相关网站并提取有效信息的 ...
- python scrapy版 极客学院爬虫V2
python scrapy版 极客学院爬虫V2 1 基本技术 使用scrapy 2 这个爬虫的难点是 Request中的headers和cookies 尝试过好多次才成功(模拟登录),否则只能抓免费课 ...
- Python.Scrapy.14-scrapy-source-code-analysis-part-4
Scrapy 源代码分析系列-4 scrapy.commands 子包 子包scrapy.commands定义了在命令scrapy中使用的子命令(subcommand): bench, check, ...
随机推荐
- Javascript--运算符判断成绩运算
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- activemq 消息队列服务器
ActiveMQ 安装配置 更多 安装 前置条件:1)安装JDK:2)配置 JAVA_HOME 环境变量,确保 echo $JAVA_HOME 输出JDK的安装路径 下载:wget http://ww ...
- python 字符串的I/O 操作
想使用操作类文件对象的程序来操作文本或二进制字符串 使用io.StringIO() 和io.BytesIO() 类来创建类文件对象操作字符串数据 >>> s = io.StringI ...
- za
http://www.szjs.gov.cn/bsfw/zdyw_1/zfbz/jgcx/
- Linux基础命令---chgrp
chgrp 改变文件或者目录所属的群组,使用参数“--reference”,可以改变文件的群组为指定的关联文件群组. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.o ...
- 单片机裸机下写一个自己的shell调试器(转)
源: 单片机裸机下写一个自己的shell调试器
- 08: Django使用haystack借助Whoosh实现全文搜索功能
参考文章01:http://python.jobbole.com/86123/ 参考文章02: https://segmentfault.com/a/1190000010866019 参考官网自定制v ...
- C++中两个类中互相包含对方对象的指针问题(转载)
出处:http://www.cnblogs.com/hanxi/archive/2012/07/25/2608068.html // A.h #include "B.h" clas ...
- Visual Status各个版本官网下载
网址:https://www.visualstudio.com/zh-hans/vs/older-downloads/
- linux的dns被劫持
环境:ubuntu16.04 解说:ubuntu使用dnsmasq获取要解析的网站ip,dnsmasq通过域名服务器获取网站ip,并将ip缓存起来,那么就可以减少对外网域名服务器的访问,从而可以使系统 ...