一起学Hadoop——Hadoop的前世今生
Hadoop是什么?
Hadoop是一个处理海量数据的开源框架。2002年Nutch项目面世,这是一个爬取网页工具和搜索引擎系统,和其他众多的工具一样,都遇到了在处理海量数据时效率低下,无法存储爬取网页和搜索网页时产生的海量数据的问题。2003年谷歌发布了一篇论文,专门介绍他们的分布式文件存储系统GFS。鉴于GFS在存储超大文件方面的优势,Nutch按照GFS的思想在2004年实现了Nutch的开源分布式文件系统,即NDFS。2004年谷歌发布了另一篇论文,专门介绍他们处理大数据的计算框架MapReduce,2005年初Nutch开发人员在Nutch上实现了开源的MapReduce,这就是Hadoop的雏形。2006年Nutch将NDFS和MapReduce迁出Nutch,并命名为Hadoop,同时雅虎公司专门为Hadoop建立一个团队,将其发展成为能够处理海量数据的Web框架,2008年Hadoop成为Apache的顶级项目。
2007年9月发布hadoop 0.14.1,第一个稳定版本。
2009年4月发布hadoop 0.20.0版本。
2011年12月发布hadoop 1.0.0版本,这是经过将近6年的酝酿后发布的一个版本,该版本基于0.20安全代码线,增加如下的功能:
安全,
Hbase(append/hsynch/hflush和security)
webhdfs(完全支持安全)
增加HBase访问本地文件系统的性能
2.12年5月发布hadoop 2.0.0-alpha,则是hadoop-2.X系列的第一个版本,增加很多重要的特性:
1、NameNode HA(High Availability高可靠性),当主NameNode挂掉时,备用NameNode可以快速启动,成为主NameNode节点,向外提供服务。
2、HDFS Federation。
3、YARN aka NextGen MapReduce。
2017年9月份发布Hadoop 3.0.0 generally版本,这是hadoop 3.x系列的第一个版本。
目前市面上还是以Hadoop2.x系列为主,Hadoop3.x还没正式的运用到生产系统中。
一句话总结:Hadoop是开源的大数据处理框架,分为处理数据的MapReduce和存储数据的HDFS。
Hadoop能做什么?
Hadoop可以用来处理海量数据,对数据进行分析。现在互联网企业每天都产生大量的日志数据,有的甚至达到PB级别,像国外的facebook,twitter,国内的阿里、腾讯、京东、百度等企业。在Haddop没出现之前,都是用小型机处理数据,价格昂贵不说,还耗费时间,Hadoop面世之后,可以使用廉价机器搭建Hadoop集群,一台小型机的价格就可以搭建起一个20个节点的Hadoop集群。2007年雅虎在900个节点的hadoop集群上对1T的数据进行排序只需要209秒,引起业界的关注,从此Haddoop逐渐成为大数据处理的标准,众多厂商纷纷向其靠拢。目前国内的互联网企业对Hadoop的使用都比较成熟,在2015年的时候百度的Hadoop集群就达到4000个节点。
Hadoop的缺点
Hadoop适合处理海量的离线数据,对于处理实时数据却不合适,例如实时股票交易分析。实时海量数据处理目前有比较好的框架,分别是Spark Streaming,Storm,Flink。他们也都是基于Hadoop的基础上实现的,数据Hadoop生态系统中的一员。
Hadoop生态框架
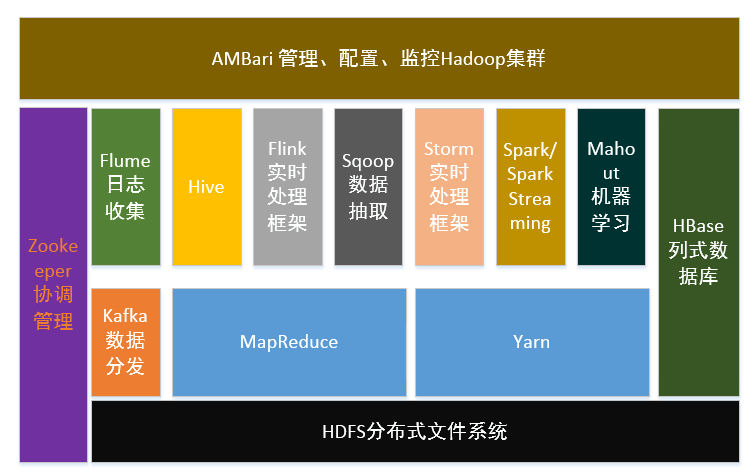
现在我们讲Hadoop,泛指Hadoop生态系统中的各种组件,包括用于构架数据仓库和分析数据的Hive,基于HDFS的列式数据库HBase,实时数据处理框架Flink、Storm、Spark Streaming等。下图是Hadoop的生态系统图。
一起学Hadoop——Hadoop的前世今生的更多相关文章
- [Hadoop]Hadoop章2 HDFS原理及读写过程
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统. HDFS有很多特点: ① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份. ② ...
- hadoop hadoop install (1)
vmuser@vmuser-VirtualBox:~$ sudo useradd -m hadoop -s /bin/bash[sudo] vmuser 的密码: vmuser@vmuser-Virt ...
- Hadoop hadoop 机架感知配置
机架感知脚本 使用python3编写机架感知脚本,报存到topology.py,给予执行权限 import sys import os DEFAULT_RACK="/default-rack ...
- EDW on Hadoop(Hadoop上的数据仓库)技术选型和实践思考
在这篇文章中, 将讨论EDW on Hadoop 有哪些备选方案, 以及我个人的倾向性, 最后是建构方法. 欢迎转载, 但必须注明原贴(刘忠武, http://www.cnblogs.com/ha ...
- [Hadoop] Hadoop学习历程 [持续更新中…]
1. Hadoop FS Shell Hadoop之所以可以实现分布式计算,主要的原因之一是因为其背后的分布式文件系统(HDFS).所以,对于Hadoop的文件操作需要有一套全新的shell指令来完成 ...
- [Hadoop] Hadoop学习笔记之Hadoop基础
1 Hadoop是什么? Google公司发表了两篇论文:一篇论文是“The Google File System”,介绍如何实现分布式地存储海量数据:另一篇论文是“Mapreduce:Simplif ...
- [hadoop] hadoop “util.NativeCodeLoader: Unable to load native-hadoop library for your platform”
执行 bin/hdfs dfs -mkdir /user,创建目录时出现警告信息. WARN util.NativeCodeLoader: Unable to load native-hadoop l ...
- java.io.FileNotFoundException: /home/hadoop/hadoop/dfs/namenode/current/VERSION (Permission denied)
今天布置hadoop集群,尝试单独将secondarynamenode分属到一台独立的虚拟机上, 当格式化后,start-dfs.sh.namenode没启动.查看日志.报错例如以下 查看权限才发现, ...
- [Hadoop] - Hadoop Mapreduce Error: GC overhead limit exceeded
在运行mapreduce的时候,出现Error: GC overhead limit exceeded,查看log日志,发现异常信息为 2015-12-11 11:48:44,716 FATAL [m ...
随机推荐
- percona mysql5.7关闭审计功能方法
数据库的审计日志占用大量空间,当时是为了测试审计功能开启的,现在需要关闭 # /data/mysql_data]# du -sh * 124G audit.log # 查询审计相关参数 mysql&g ...
- 持续集成之②:整合jenkins与代码质量管理平台Sonar并实现构建失败邮件通知
持续集成之②:整合jenkins与代码质量管理平台Sonar并实现构建失败邮件通知 一:Sonar是什么?Sonar 是一个用于代码质量管理的开放平台,通过插件机制,Sonar 可以集成不同的测试工具 ...
- 【转】Jmeter中使用CSV Data Set Config参数化不重复数据执行N遍
Jmeter中使用CSV Data Set Config参数化不重复数据执行N遍 要求: 今天要测试上千条数据,且每条数据要求执行多次,(模拟多用户多次抽奖) 1.用户id有175个,且没有任何排序规 ...
- [其它]安装ios12 developer beta 3出错
ios11设备升级到ios12有时候会出现 安装ios12 developer beta 3出错 提示.此时有一种可能就是,你手机或者ipad空间不足2G多(因为ios12是2.13G) 仅作为记录使 ...
- python-进程之间通信、多线程介绍
一.进程之间通信 进程的任务有三种状态:运行,就绪,阻塞. 加锁可以让多个进程修改同一块数据时,同一时间只能由一个任务可以进行修改,即串行的修改.牺牲了速度,保证了数据安全. 虽然可以使用文件共享数据 ...
- Uiautomator - 6.0 以上权限受限问题
问题:在android studio中使用UiAutomator 2.0 编写测试用例时,要实现截图(非命令方式),写入文件时出现权限被拒绝的提示.例如: java.io.FileNotFoundEx ...
- AD9361寄存器配置顺序,循环模式,自收自发
:] cmd_data; :] index; begin case(index) 'h000,8'h00};//set spi -- 'h3df,8'h01};//set init -- 'h037, ...
- python冒泡排序法
- 《剑指offer》二叉搜索树的后序遍历序列
本题来自<剑指offer> 二叉搜索树的后序遍历序列 题目: 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果.如果是则输出Yes,否则输出No.假设输入的数组的任意两个数字 ...
- linux学习笔记之 basename, dirname
前言: basename: 用于打印目录或者文件的基本名称 dirname: 去除文件名中的非目录部分,仅显示与目录有关的内容.dirname命令读取指定路径名保留最后一个/及其后面的字符,删除其他部 ...