浅谈SQL Server数据内部表现形式
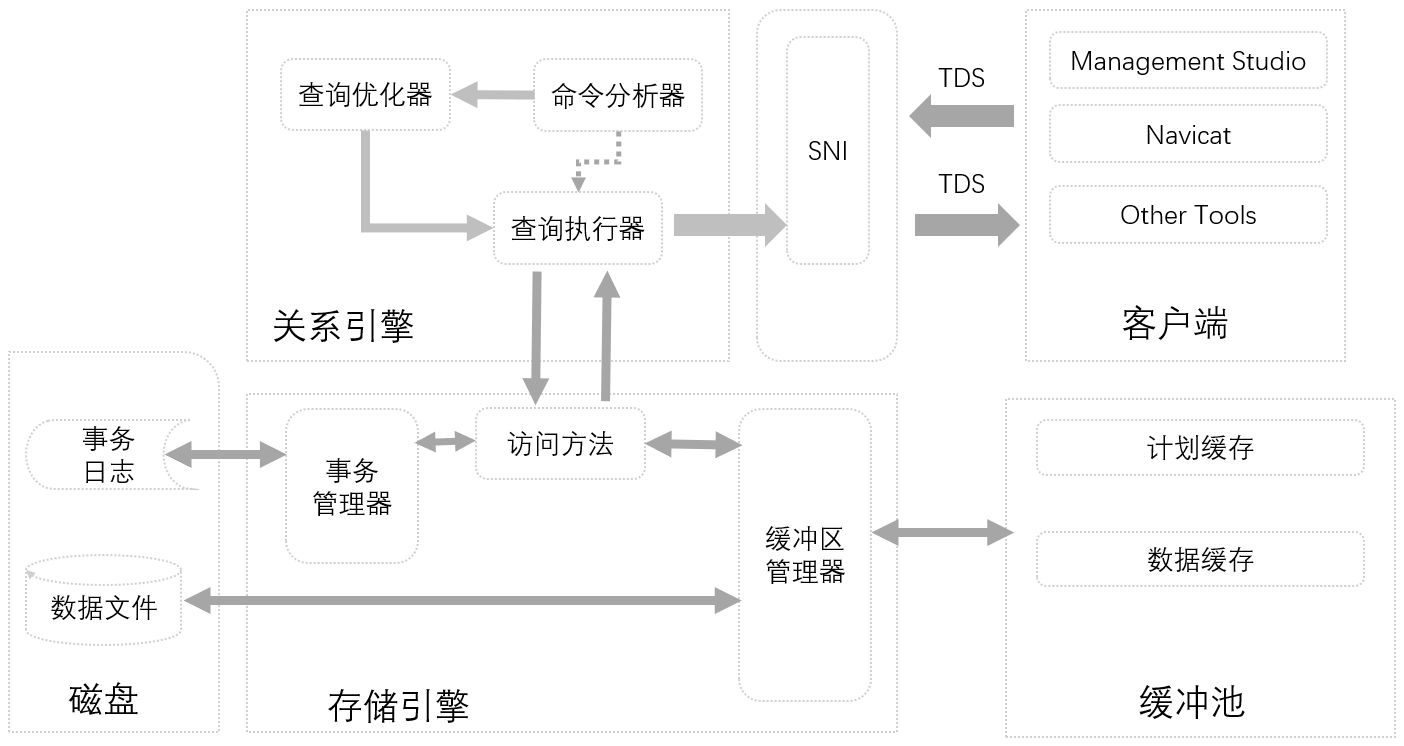
在上篇文章 浅谈SQL Server内部运行机制 中,与大家分享了SQL Server内部运行机制,通过上次的分享,相信大家已经能解决如下几个问题:
1.SQL Server 体系结构由哪几部分组成?
2.SQL Server 体系结构各模块之间关系是怎样的?
3.SQL Server 体系结构内部运行机制是怎样的?
4.简单的一条SELECT语句,在SQL Server中是如何一步一步执行的?
然而,仅仅能解决如上几个问题,是不具有SQL Server数据库优化能力的,为什么这么说,我们先提出如下几个问题:
1.为什么会内存溢出?(上篇文章开篇提出的)
2.为什么会产生死锁,闩锁?
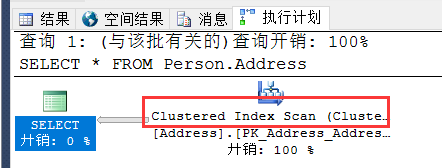
3.什么叫执行计划,如何分析执行计划?
4. Index Scan 与Index Seek区别?

5.什么叫聚集索引和非聚集索引?
6.什么叫堆和B-数?
7.优化SQL Server,应该建立怎样的一套优化理念?
8.SQL Server优化时,常用的检测工具,优化工具和优化手段都有哪些?
9.你了解这些表与函数吗?
Sys.dm_exec_requests,Sys.dm_exec_sql_text,Sys.dm_exec_session,Sys.dm_exec_connections,Sys.dm_exec_query_stats,Sys.dm_exec_query_resource_semaphores
10.为什么磁盘臂是I/O的最大开销?
11.什么叫碎片,为什么会产生碎片?
12.什么叫跨域,什么叫主从同步?
13.为什么要分区,为什么要拆表(水平拆分,垂直拆分)?
..........
如上的这些基础问题,若不能很好地解决,就急忙去研究SQL Server优化,甚至去实战,是会绕很多弯路的,且学得一知半解。我们就拿索引举个例子,一张UserInfo(UserName,Address,Sex)有1000万条数据,
当我们查询时,非常缓慢,为了提高查询速度,我们优先想到的是建立索引(其他条件不变情况下,如不增加CPU,不增加内存,不改变磁盘等),有经验的DBA和数据库优化高手,是不会选择Addresss和sex作为索引字
段的,想想为什么?
基于如上的种种问题,本篇文章还是继续从理论角度分析SQL Server的一些基本理论,为后续的SQL Server优化实战打好良好的功底,至于具体的优化实战,应该会在第四篇或第五篇文章开始讲解(本篇文章
为SQL Server数据库优化系列第二篇),本篇文章大致包括如下内容。(当然,本篇文章未必能全部解决如上提出的问题,但在SQL Server理论性问题介绍结束,大家应该知道如何解决,然后再去实战)
- SQL Server引擎及集群
- SQL Server数据文件存储
- SQL Server table表数据的存储形式
- Page的基本构成
- 若干基本概念:堆(Heap)、分区、B-Tree、行数据溢出、Master-Slave等
一 SQL Server引擎及集群
首先,我们要知道什么叫做SQL Server服务器?SQL Server服务器部署在服务器端,用来存储数据的,如系统数据(如系统数据库master,tempdb等)、用户数据(如自定义数据库数据)和日志数据(如Log Files)等。
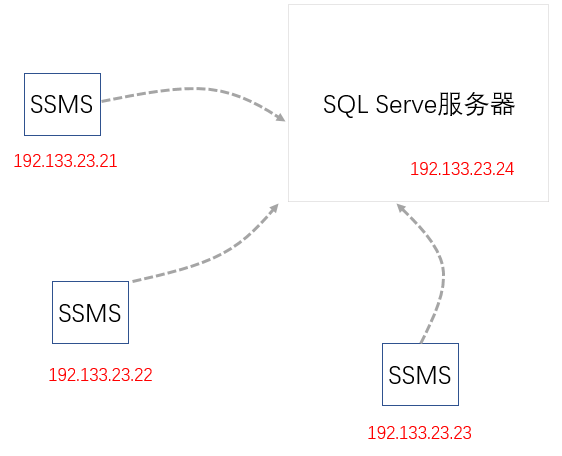
一般地,SQL Server为我们提供了客户端访问工具SSMS(Microsoft SQL Server Management Studio),通过该工具,我们能访问SQL Server服务器,从而通过客户端SQL语句,获取我们想要的数据,SQL Server最为简
单的模式是:客户端《=》服务器模式,即只有一台SQL Server服务器,供一个或多个客户端访问,这种架构是最为简单的,也是大部分小公司常用的架构。下图为三个不同IP的SQL Server客户端工具SSMS访问同一个
SQL Server服务器。
其次,对于具有一定规模,有一定数据量的公司,单台SQL Server服务满足不了业务需求,如系统访问速度慢(一般用户能容忍的时间是3秒,时间超过3秒,用户就感觉不良好)、数据量大(单台SQL Server服务器无法支撑)等,
这时,就需要2台及以上SQL Server服务器(当然,实际的架构中,不仅仅是SQL Server服务器之间集群,还有可能是SQL Server服务器,Oracle服务器、MySQL服务器之间跨服务器、跨域的集群),通过多台SQL Server服务器集群,
形成一个庞大的中央服务器,来处理高并发,大数据量、访问速度等性能问题,常见的是一个例子就是读写分离,主从同步。

下图是在四个IP不同的服务器上分别部署一台SQL Server服务器引擎和每台服务器的SQL Server引擎包括的基本内容。
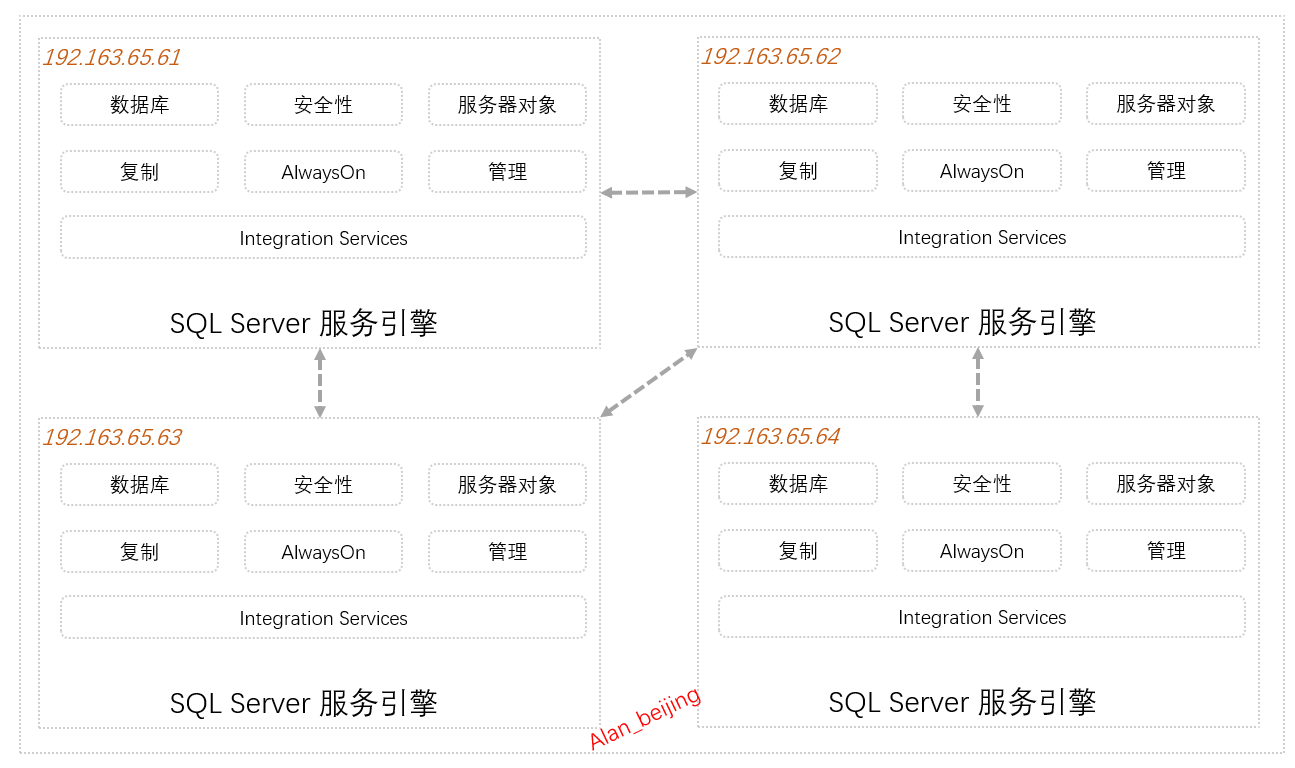
(一)SQL Server 引擎基本内容
1.数据库
2.安全性
3.服务器对象
4.复制
5.AlwaysON
6.管理
7.Integration Services
(二)SQL Server引擎之间关系
1.跨域
2.跨域数据主从同步
二 SQL Server 数据文件存储
在了解SQL Server服务器基本构成,SQL Server服务器部署,SQL Server服务器集群和客户端访问工具SSMS如何访问SQL Server服务器后,接下来,我们将目标定位在单个SQL Server服务器上,研究
SQL Server单个服务器,通过第一部分,我们知道单个SQL Server服务器的基本组成,接下来,我们来分析SQL Server服务器都有哪些文件,且它们分别以什么样的形式存储,存储在哪?
对于SQL Server,数据库文件和日志文件是其两大类核心文件。

数据文件主要用来存储相关数据的,如系统数据库(master,model,msdb,tempdb)文件,用户自定义数据库文件,日志文件等。
1.数据库文件主要包括两个核心文件(.mdf-文件为主要文件,.ndf-文件为次要文件),当创建数据库时,系统默认会创建.mdf文件和.ndf文件,这两个文件是以页(page)的
方式存储的,它们用来保存一些数据库对象,如保存表数据,索引数据,约束等;
2.日志文件(Virtual Log Files,简称VLF),这种文件不是按照页的方式存储的,换句说,他们存储的大小是不确定的,是任意的。
三 Table表数据的存储形式
通过第二部分,我们知道了SQL Server服务器主要有两大类资源文件,即数据库文件和日志文件,其中,对于用户或者一般开发人员来说,数据库文件应该算是他们最关心的文件,
然而,数据库文件有很多资源对象,如实体表(table),视图(View),索引(Index),约束(Constraint)等等,面对这么多数据库对象,我们该如何研究呢?是全部研究,还是选择重点研究?当然是选择重点研究,
我们将选择用户或开发人员使用频率最多的实体表(table)作为研究对象。
本小节,我们主要讨论几个问题:table是如何存储的,什么是分区,什么是堆,什么是B-树,以及它们之间的关系是怎样的?
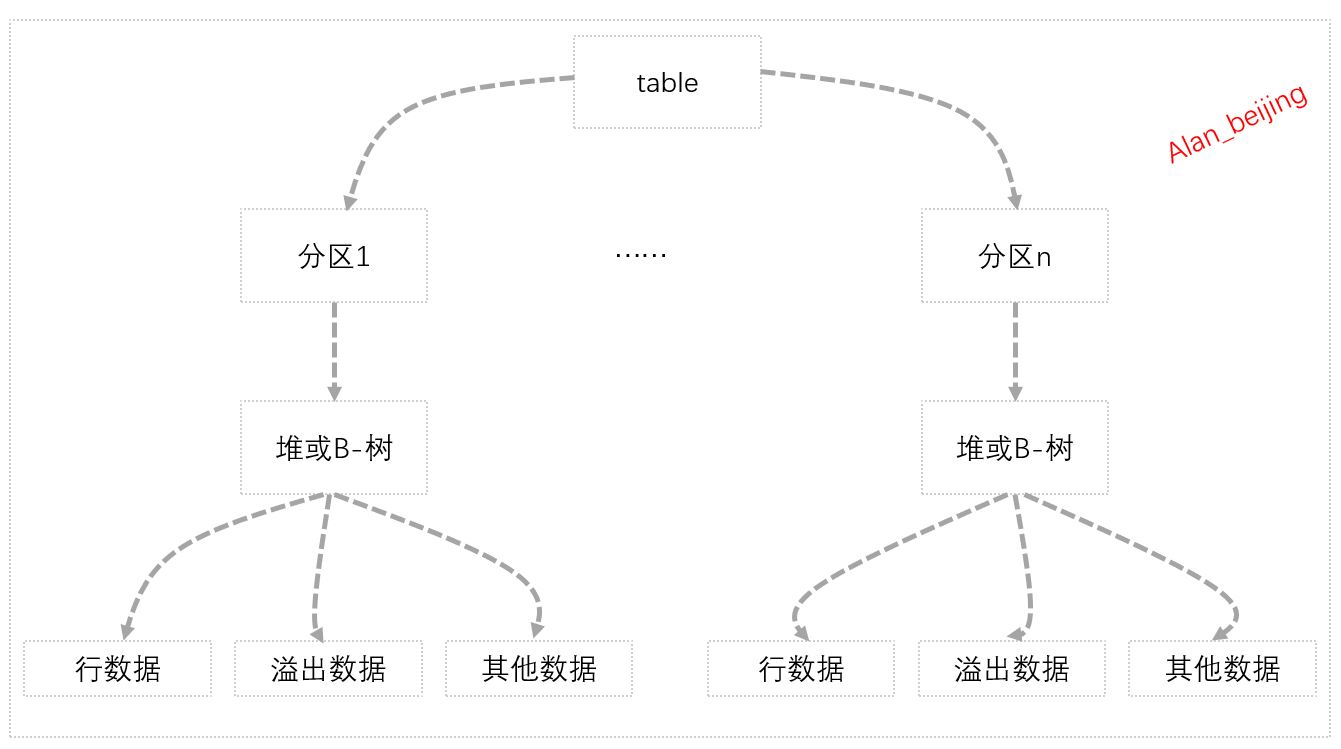
(一)实体表的两种存储方式
对于SQL Server中的实体表数据,在SQL Server中的存储形式表现为堆存储(Heap)和B树存储(B-Tree,B+Tree)。
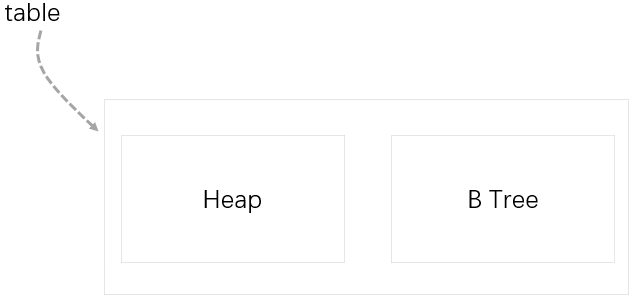
(二)Heap
1.堆,指不含有聚集索引的表,之所以称为堆,是因为它的数据不按任何顺序进行组织,而是按分区组对数据进行组织。
2.在堆中,用于保存数据之间关系的唯一索引结构是索引分配映射(IAM,Index Allocation Map)的位图,对于混合区(mixed extent)分配的前8个页,这个位图中有指向这些页的指针,
它还包括一个大位图(每个位代表文件中的4G范围内的一个区)。
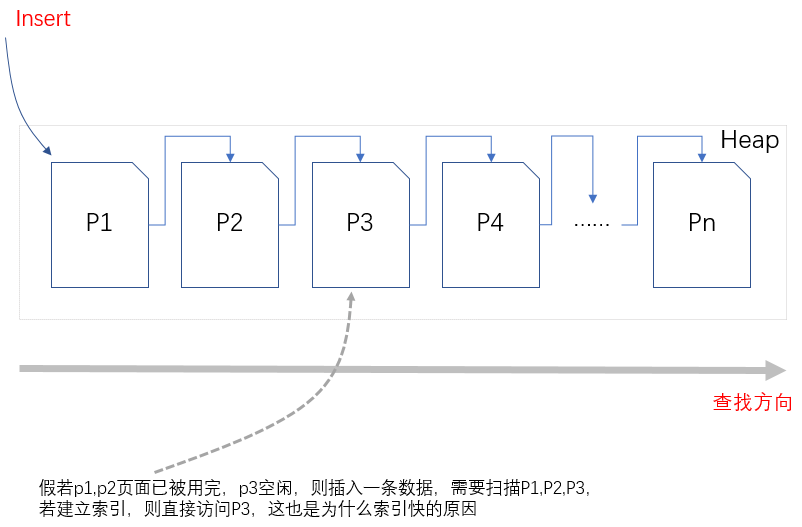
3.堆不是按照特定顺序来维护的,所以新增加到列表中的行可以保存到任何数据页上。SQL Server使用页可用空间页(PFS,Page Free Space)的位图来跟踪数据页中的可用空间,以
便可以快速地找到有足够空间能够容纳新行的页面,如果这样的页面不存在,则分配一个新页面,对于长度可变的列进行更新时,行的大小就会扩展,页可能会因为没有空间而无法容纳
新增加的行,此时,SQL Server 会把扩展后的行移动到具有足够空间的页上,而在原来的位置上保留一个所谓的正向指针(forwarding pointer),,通过它指向行的新位置。
(三)区
区是由8个物理连续的页组成的单元。当表或索引需要更多的空间以存储数据时,SQL Server为对象分配一个完整的区。

1.对于包含少量数据的对象,当对象不足64KB时,SQL Server通常只分配一个单独的页,而不是整个区
2.区按存储是否为同一对象,可分为混合区(区8个连续的页存储不同对象)和非混合区(区8个连续的页存储相同的对象)
3.当删除(delete)或清空(Truncate)表时,将会释放区
4.一些读操作,如大型表或索引扫描的预读(read-ahead),可以在区级别,或更高的快级别读取数据
5.I/O操作最大的开销是磁盘臂的移动,而真正的磁盘读写操作开销要小得多,因此,读取一个页和读取一个区所用得时间几乎一样
(四)B Tree
B树是一种存储结构,如B+Tree,B-Tree,其中,B-Tree是我们重点关心的,B-Tree是一种平衡树,主要用来存储聚集索引相关数据的,在这里不重点论述,只要知道有这么个概念即可,
在索引(Index)章节,我会重点论述。
(五)行数据、溢出数据和其他数据
详见本篇博文第四部分。
四 页的基本构成
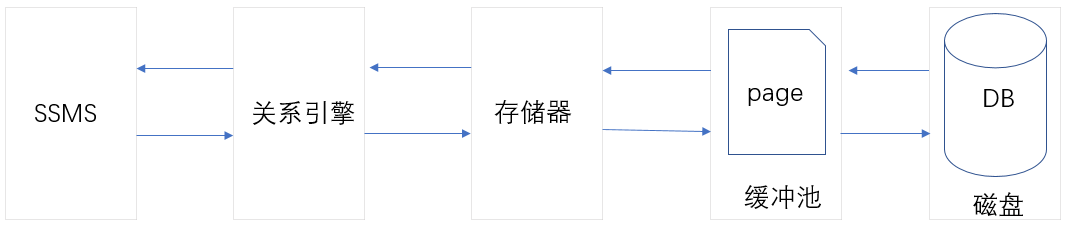
通过前面几节介绍,我们知道,页是存储的最小单位(其实,页也是IO的最小单位,每次从磁盘DB中读取数据到缓冲池,都是以页为单位读取的),那么SQL Server中的Page又是什么呢?它
的基本结构又是怎样的呢?下图为SQL Server中,一个Page的基本构成。
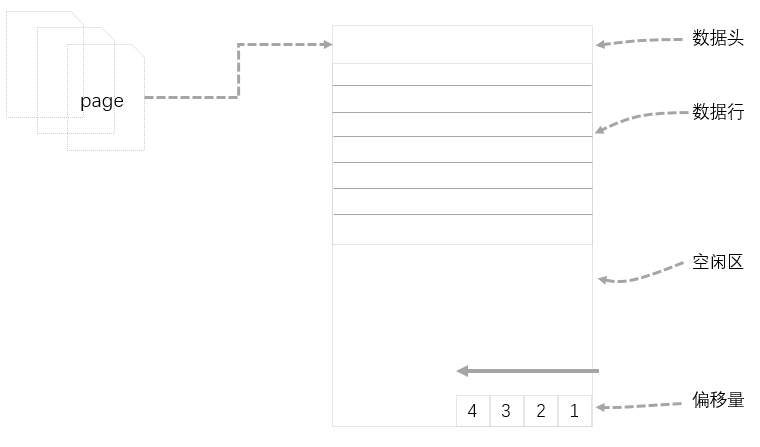
(一)页描述
页是SQL Server存储数据的基本单位,大小为8KB,它可以包含表或索引数据、分配位图、可用空间信息等。在SQL Server中,页是数据存储的最小单位,也是数据读取的最小IO。
(二)页的基本构成
SQL Server Page主要由四部分构成,页头(Page Header),数据行(Data Row),空闲区(Free)和偏移量(Offset)。
1.页是数据存储的最小单位,页是数据读取的最小IO;
2.一个页的大小为8KB,其中页头占据96B(96个字节),页尾维护的行指针占据2B(2个字节),还有其他保留字段以备后用。
3.SQL Server 2005后,为了满足VARCHAR,NVARCHAR,VARBINARY,SQL_VARIANT和CLR用户定义类型,放宽了对行大小的限制,这个技术就叫做行溢出数据。
4.行溢出数据,指当行超过8060字节时,这些类型的值将被移动到一个成为行溢出分配单元中的页中,而在原始页上保留一个24字节的指针,指向行外的数据,如此,行就
可以跨多个页,但行内数据任然在8060字节限制内。如果类型值在8000字节以内,它们的值将被移动到行溢出页中;如果超过8000字节,这些值在内部将被存储为一个大类型
对象,而在原始行上维护一个16字节的指针,指向该大型对象值。
五 参考文献
【01】《SQL Server 2012 深入解析与性能优化 第3版》Christian Bolton,Justin Langford,Glenn Berry,Gavin Payne,Amit Banerjee,Rob Farley著
【02】《SQL Server 2008查询性能优化》Grant Fritchey,Sajal Dam著
【03】《Microsoft SQL Server 2008 技术内幕:T-SQL查询》ltzik Ben-Gran,Lubor Kollar,Dejan Sarka,Steve Kass著
六 版权区
- 感谢您的阅读,若有不足之处,欢迎指教,共同学习、共同进步。
- 博主网址:http://www.cnblogs.com/wangjiming/。
- 极少部分文章利用读书、参考、引用、抄袭、复制和粘贴等多种方式整合而成的,大部分为原创。
- 如您喜欢,麻烦推荐一下;如您有新想法,欢迎提出,邮箱:2098469527@qq.com。
- 可以转载该博客,但必须著名博客来源。
浅谈SQL Server数据内部表现形式的更多相关文章
- 浅谈SQL Server内部运行机制
对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说,逻辑的增删改查,或者较复杂的SQL语句,都是非常简单的,不存在任何挑战,不值得一提,那么,SQL的哪些方面是他们的挑战 或者软肋呢? 那就是 ...
- 【SqlServer系列】浅谈SQL Server事务与锁(上篇)
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章视图采用图文的方式来与大家一起探讨. “浅谈SQL Server 事务与锁”这个专题共分两篇,上篇主讲事务及 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 浅谈SQL Server事务与锁(上篇)
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章试图采用图文的方式来与大家一起探讨. “浅谈SQL Server 事务与锁”这个专题共分两篇,上篇主讲事务及 ...
- 浅谈SQL Server中的事务日志(一)----事务日志的物理和逻辑构架
简介 SQL Server中的事务日志无疑是SQL Server中最重要的部分之一.因为SQL SERVER利用事务日志来确保持久性(Durability)和事务回滚(Rollback).从而还部分确 ...
- 浅谈SQL Server中的事务日志(二)----事务日志在修改数据时的角色
简介 每一个SQL Server的数据库都会按照其修改数据(insert,update,delete)的顺序将对应的日志记录到日志文件.SQL Server使用了Write-Ahead logging ...
- 浅谈SQL Server中的三种物理连接操作
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 浅谈SQL Server 对于内存的管理
简介 理解SQL Server对于内存的管理是对于SQL Server问题处理和性能调优的基本,本篇文章讲述SQL Server对于内存管理的内存原理. 二级存储(secondary storage) ...
- 浅谈SQL Server中的三种物理连接操作(HASH JOIN MERGE JOIN NESTED LOOP)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
随机推荐
- 设计模式之桥接模式——Java语言描述
桥接适用于把抽象化和实现化解耦,使得二者可以独立变化.这种类型的设计模式属于结构性模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦 这种模式设计到一个作为桥接的接口,使得实体类的功能独立 ...
- 用weexplus从0到1写一个app
说明 基于wexplus开发app是来新公司才接触的,之前只是用过weex体验过写demo,当时就被用vue技术栈来开发app的开发体验惊艳到了,这个开发体验比react native要好很多,对于我 ...
- vba读文本如果文本文件太大会提示错误!
Sub 文本文件太大会提示错误() Dim TT, p Open "I:\xxxxx\yyyzz.txt" For Input As #1 '读取txt文件 Do Wh ...
- ERROR 1129 (HY000): mysqladmin flush-hosts
mysql报错:ERROR 1129 (HY000): Host * is blocked because of many connection errors; unblock with 'mysql ...
- 二维前缀和模板题:P2004 领地选择
思路:就是使用二维前缀和的模板: 先放模板: #include<iostream> using namespace std; #define ll long long ; ll a[max ...
- java日志框架log4j详细配置及与slf4j联合使用教程
最后更新于2017年02月09日 一.log4j基本用法 首先,配置log4j的jar,maven工程配置以下依赖,非maven工程从maven仓库下载jar添加到“build path” <d ...
- 使用ASP.NET Core开发GraphQL服务器 -- 预备知识(下)
上一篇文章:https://www.cnblogs.com/cgzl/p/9734083.html 处理数据 嵌套字段 看例子: 我想查看viewer下的repositories.注意里面的edges ...
- Android APP应用启动页白屏(StartingWindow)优化
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 StartingWindow 的处理方式: 使用系统默认的 StartingWindow :用户点了应用图标启动应用,马上弹出系统默 ...
- unity+xlua开发中的问题笔记
转载请标明出处:http://www.cnblogs.com/zblade/ 一.概述 整理遇到的一些较难处理的bug,总结相关经验 二.主要问题 2.1 material类型的依赖修改 对于mate ...
- javascript小记五则:用JS写一个图片左右自由滚动的“跑马灯”效果
之前看了很多百度搜索出的东西,十个有九个是不能实用的,个个讲的都不详细,今天详细给大家讲解下关于这个图片“跑马灯”滚动效果,源码如下: <!DOCTYPE html PUBLIC "- ...