java爬虫系列第一讲-爬虫入门
1. 概述
java爬虫系列包含哪些内容?
- java爬虫框架webmgic入门
- 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页、电影下载地址等信息)
- 使用webmgic爬取 极客时间 的课程资源(文章系列课程 和 视频系列的课程)
本篇文章主要内容:
- 介绍java中好用的爬虫框架
- java爬虫框架webmagic介绍
- 使用webgic爬取动作电影列表信息
2. java中好用的爬虫框架
如何判断框架是否优秀?
- 容易学习和使用,网上对应的学习资料比较多,并且比较完善
- 使用的人比较多,存在的坑别人已经帮你填的差不多了,用起来会更顺心一些
- 框架更新比较快,社区活跃,可以快速体验一些更好的功能,并与作者进行交流
- 框架稳定、方便扩展
按照以上几点的,推荐一款非常好用的java爬虫框架webmgic
3. webmgic介绍
- WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
- webmagic官网:http://webmagic.io/
- webmgic中文学习文档:http://webmagic.io/docs/zh/
4.使用webgic爬取动作电影列表
使用webgic爬取 爱电影 电影列表资源信息
1. 新建springboot项目java-pachong
2. 导入maven配置
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- webmagic start -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<artifactId>fastjson</artifactId>
<groupId>com.alibaba</groupId>
</exclusion>
<exclusion>
<artifactId>commons-io</artifactId>
<groupId>commons-io</groupId>
</exclusion>
<exclusion>
<artifactId>commons-io</artifactId>
<groupId>commons-io</groupId>
</exclusion>
<exclusion>
<artifactId>fastjson</artifactId>
<groupId>com.alibaba</groupId>
</exclusion>
<exclusion>
<artifactId>fastjson</artifactId>
<groupId>com.alibaba</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-selenium</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>net.minidev</groupId>
<artifactId>json-smart</artifactId>
<version>2.2.1</version>
</dependency>
<!-- webmagic end -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.49</version>
</dependency>
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.11</version>
</dependency>
<dependency>
<groupId>commons-collections</groupId>
<artifactId>commons-collections</artifactId>
<version>3.2.2</version>
</dependency>
</dependencies>
3. 编写抓取电影数据的代码
在谷歌浏览器中访问 爱电影动作片列表
F12发现列表页中数据是通过一个ajax请求获取的,我们获取请求地址
编写抓取代码
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* <b>description</b>:第一个爬虫示例,爬去动作片列表信息 <br>
* <b>time</b>:2019/4/20 10:58 <br>
* <b>author</b>:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/listJson/1/2?_=1555726508180";
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
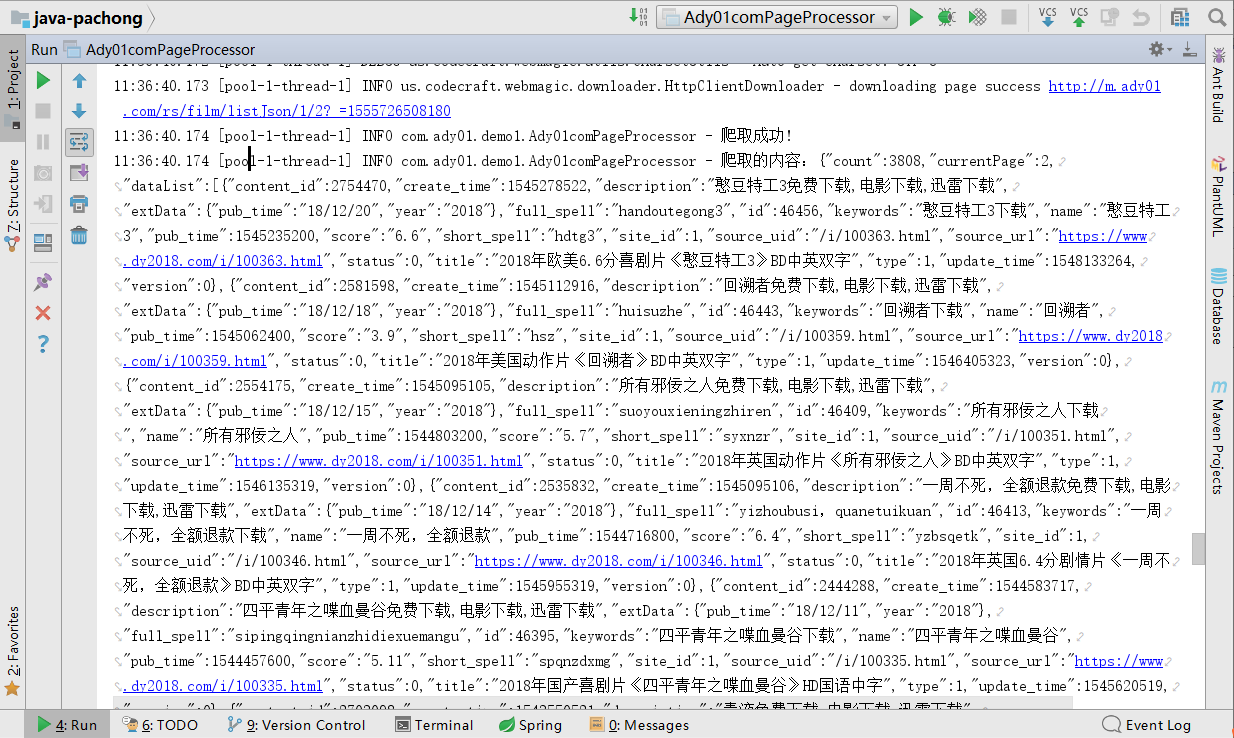
4. 运行爬虫代码
运行Ady01comPageProcessor中的main方法,执行结果如下:
5.总结
- 本文中主要用了一个示例说明webgic是如此简单就可以完成数据的抓取工作,从代码中可以看出复杂的代码webmagic都帮我们屏蔽了,只需要我们去关注业务代码的编写。
- 文章中没有详细介webmagic如何使用,至于我为何没有在文档中去做说明,主要是webigc已经提供了非常完善的学习文档,可以移步到webgic中文文档,需要更深入了解的可以研究一下webgic的源码,对你编写爬虫是非常有用的。
- 明日我们将爬取每个动作电影详情页信息,采集详情页中电影的下载地址
- 示例代码,导入到idea中运行,idea中需要安装maven和lombok的支持
- 更多技术文章请关注公众号:javacode2018
java爬虫系列第一讲-爬虫入门的更多相关文章
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- Python 爬虫3——第一个爬虫脚本的创建
在进行真正的爬虫工程创建之前,我们先要明确我们所要操作的对象是什么?完成所有操作之后要获取到的数据或信息是什么? 首先是第一个问题:操作对象,爬虫全称是网络爬虫,顾名思义,它所操作的对象当然就是网页, ...
- python爬虫__第一个爬虫程序
前言 机缘巧合,最近在学习机器学习实战, 本来要用python来做实验和开发环境 得到一个需求,要爬取大众点评中的一些商户信息, 于是开启了我的第一个爬虫的编写,里面有好多心酸,主要是第一次. 我的文 ...
- Java多线程系列——从菜鸟到入门
持续更新系列. 参考自Java多线程系列目录(共43篇).<Java并发编程实战>.<实战Java高并发程序设计>.<Java并发编程的艺术>. 基础 Java多线 ...
- Scrapy爬虫框架第一讲(Linux环境)
1.What is Scrapy? 答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰.模块之间的耦合程度低,具有较强的扩张性,能满足各种需求.(前 ...
- python爬虫系列之初识爬虫
前言 我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握爬虫的基础知识,做网络爬虫还是需要基本的前端的 ...
- java selenium webdriver第一讲 seleniumIDE
Selenium是ThoughtWorks公司,一个名为Jason Huggins的测试为了减少手工测试的工作量,自己实现的一套基于Javascript语言的代码库 使用这套库可以进行页面的交互操作, ...
- JAVA通信系列三:Netty入门总结
一.Netty学习资料 书籍<Netty In Action中文版> 对于Netty的十一个疑问http://news.cnblogs.com/n/205413/ 深入浅出Nettyhtt ...
随机推荐
- JDK10安装配置详解
JDK10安装配置详解 1. 下载jdk10 1.1 官网下载jdk7的软件包: 地址:http://www.oracle.com/technetwork/java/javase/dow ...
- Spark学习之键值对操作总结
键值对 RDD 是 Spark 中许多操作所需要的常见数据类型.键值对 RDD 通常用来进行聚合计算.我们一般要先通过一些初始 ETL(抽取.转化.装载)操作来将数据转化为键值对形式.键值对 RDD ...
- java~springboot~目录索引
回到占占推荐博客索引 最近写了不过关于java,spring,微服务的相关文章,今天把它整理一下,方便大家学习与参考. java~springboot~目录索引 Java~关于开发工具和包包 Java ...
- uni-app—从安装到卸载
uni-app实现了一套代码,同时运行到多个平台.支持iOS模拟器.Android模拟器.H5.微信开发者工具.支付宝小程序Studio.百度开发者工具.字节跳动开发者工具 工具安装 开发uni-ap ...
- ArrayList 和 LinkedList 源码分析
List 表示的就是线性表,是具有相同特性的数据元素的有限序列.它主要有两种存储结构,顺序存储和链式存储,分别对应着 ArrayList 和 LinkedList 的实现,接下来以 jdk7 代码为例 ...
- DevOps实践之一:基于Docker构建企业Jenkins CI平台
基于Docker构建企业Jenkins CI平台 一.什么是CI 持续集成(Continuous integration)是一种软件开发实践,每次集成都通过自动化的构建(包括编译,发布,自动化测试)来 ...
- Docker最全教程之使用TeamCity来完成内部CI、CD流程(十六)
本篇教程主要讲解基于容器服务搭建TeamCity服务,并且完成内部项目的CI流程配置.教程中也分享了一个简单的CI.CD流程,仅作探讨.不过由于篇幅有限,完整的DevOps,我们后续独立探讨. 为了降 ...
- Java之品优购课程讲义_day06(7)
商品录入[SKU 商品信息]5.1 需求分析 基于上一步我们完成的规格选择,根据选择的规格录入商品的 SKU 信息,当用户选择相应的规格,下面的 SKU 列表就会自动生成,如下图:实现思路:实现思路: ...
- Oracle数据库知识要点
一.卸载安装(来自百度经验) 完全卸载: 1. 停止相关服务 2. 运行Universal Installer,卸载产品 3. 清理注册表 4. 重启电脑,删除目录(Oracle文件夹和app文件夹) ...
- 好看又能打的CRM系统大比拼:Salesforce, SugarCRM, Odoo等
介绍 今天的CRM市场提供了大量的解决方案和软件替代品.有些适合大型企业(通常需要内部托管),而其他企业则更多地应用于SME的需求(通常使用云托管解决方案). 在CRM解决方案方面,提供商必须调整其产 ...