Python----支持向量机SVM
1.1. SVM介绍
SVM(Support Vector Machines)——支持向量机。其含义是通过支持向量运算的分类器。其中“机”的意思是机器,可以理解为分类器。
1.2. 工作原理
在最大化支持向量到超平面距离前,我们首先要定义我们的超平面f(x)(称为超平面的判别函数,也称给w和b的泛函间隔),其中w为权重向量,b为偏移向量:
核心思想:
- 首先通过两个分类的最近点,找到f(x)的约束条件。
- 有了约束条件,就可以通过拉格朗日乘子法和KKT条件来求解,这时,问题变成了求拉格朗日乘子αi和 b。
- 对于异常点的情况,加入松弛变量ξξ来处理。
- 使用SMO来求拉格朗日乘子αi和b。这时,我们会发现有些αi=0,这些点就可以不用在分类器中考虑了。
- 惊喜! 不用求w了,可以使用拉格朗日乘子αi和b作为分类器的参数。
- 非线性分类的问题:映射到高维度、使用核函数。
划分标准:最大间隔
找两个点p1,p2到直线最近的点,两点到直线距离的和叫,最小间隔。最小间隔距离值最大,及最小间隔最大化。
1.3. 实例
数据集:
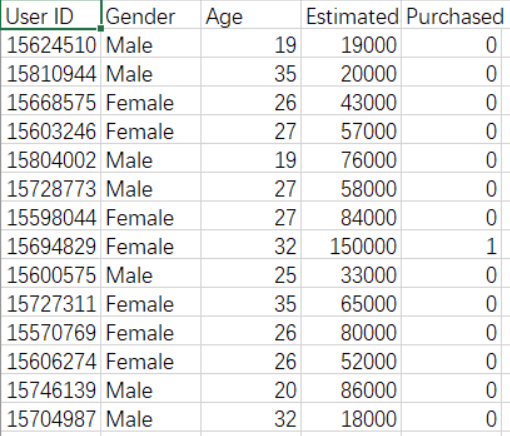
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd # Importing the dataset
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2,3]].values
y = dataset.iloc[:, 4].values # Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test) # Fitting Logistic Regression to the Training set
#训练集拟合SVM的分类器
#从模型的标准库中导入SVM的类
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear', random_state = 0)
classifier.fit(X_train, y_train) # Predicting the Test set results
#运用拟合好的分类器预测测试集的结果情况
#创建变量(包含预测出的结果)
y_pred = classifier.predict(X_test) # Making the Confusion Matrix
#通过测试的结果评估分类器的性能
#用混淆矩阵,评估性能
#65,24对应着正确的预测个数;8,3对应错误预测个数;拟合好的分类器正确率:(65+24)/100
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred) # Visualising the Training set results
#在图像看分类结果
from matplotlib.colors import ListedColormap
#创建变量
X_set, y_set = X_train, y_train
#x1,x2对应图中的像素;最小值-1,最大值+1,-1和+1是为了让图的边缘留白,像素之间的距离0.01;第一行年龄,第二行年收入
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
#将不同像素点涂色,用拟合好的分类器预测每个点所属的分类并且根据分类值涂色
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
#标注最大值及最小值
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
#为了滑出实际观测的点(黄、蓝)
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('orange', 'blue'))(i), label = j)
plt.title('SVM (Training set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
#显示不同的点对应的值
plt.legend()
#生成图像
plt.show() # Visualising the Test set results
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('orange', 'blue'))(i), label = j)
plt.title('SVM (Test set)')
plt.xlabel('Age')
plt.ylabel('Estimated Salary')
plt.legend()
plt.show()
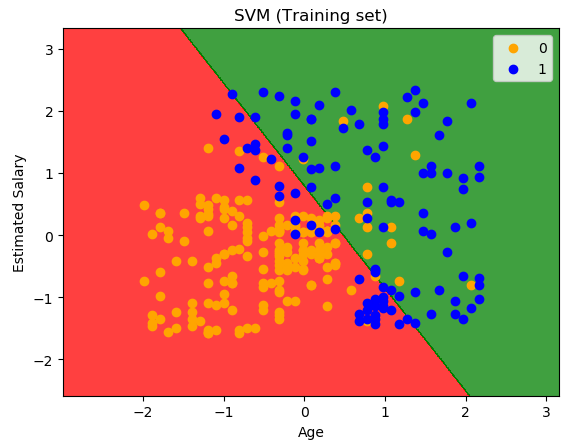
测试集图像显示结果
Python----支持向量机SVM的更多相关文章
- Python实现SVM(支持向量机)
Python实现SVM(支持向量机) 运行环境 Pyhton3 numpy(科学计算包) matplotlib(画图所需,不画图可不必) 计算过程 st=>start: 开始 e=>end ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- python机器学习之支持向量机SVM
支持向量机SVM(Support Vector Machine) 关注公众号"轻松学编程"了解更多. [关键词]支持向量,最大几何间隔,拉格朗日乘子法 一.支持向量机的原理 Sup ...
- 支持向量机SVM
SVM(Support Vector Machine)有监督的机器学习方法,可以做分类也可以做回归.SVM把分类问题转化为寻找分类平面的问题,并通过最大化分类边界点距离分类平面的距离来实现分类. 有好 ...
- 以图像分割为例浅谈支持向量机(SVM)
1. 什么是支持向量机? 在机器学习中,分类问题是一种非常常见也非常重要的问题.常见的分类方法有决策树.聚类方法.贝叶斯分类等等.举一个常见的分类的例子.如下图1所示,在平面直角坐标系中,有一些点 ...
- OpenCV 学习笔记 07 支持向量机SVM(flag)
1 SVM 基本概念 本章节主要从文字层面来概括性理解 SVM. 支持向量机(support vector machine,简SVM)是二类分类模型. 在机器学习中,它在分类与回归分析中分析数据的监督 ...
- 支持向量机SVM 参数选择
http://ju.outofmemory.cn/entry/119152 http://www.cnblogs.com/zhizhan/p/4412343.html 支持向量机SVM是从线性可分情况 ...
- 4、2支持向量机SVM算法实践
支持向量机SVM算法实践 利用Python构建一个完整的SVM分类器,包含SVM分类器的训练和利用SVM分类器对未知数据的分类, 一.训练SVM模型 首先构建SVM模型相关的类 class SVM: ...
- 机器学习第7周-炼数成金-支持向量机SVM
支持向量机SVM 原创性(非组合)的具有明显直观几何意义的分类算法,具有较高的准确率源于Vapnik和Chervonenkis关于统计学习的早期工作(1971年),第一篇有关论文由Boser.Guyo ...
随机推荐
- 每日分享!~ JavaScript(js数组如何在指定的位置插入一个元素)
这个想法是在一个面试题中看到的: 题目是这样的: // 一个数组,在指定的index 位置插入一个元素,返回一个新的数组,不改变原来的数组 <script> function inse ...
- 鸟哥Linux私房菜基础学习篇学习笔记3
鸟哥Linux私房菜基础学习篇学习笔记3 第十二章 正则表达式与文件格式化处理: 正则表达式(Regular Expression) 是通过一些特殊字符的排列,用以查找.删除.替换一行或多行文字字符: ...
- 从壹开始前后端分离 [ Vue2.0+.NET Core2.1] 二十三║Vue实战:Vuex 其实很简单
前言 哈喽大家周五好,马上又是一个周末了,下周就是中秋了,下下周就是国庆啦,这里先祝福大家一个比一个假日嗨皮啦~~转眼我们的专题已经写了第 23 篇了,好几次都坚持不下去想要中断,不过每当看到群里的交 ...
- mysql的学习笔记(六)
1.字符函数 (1).CONCAT(str1,str2,...)函数,将多列信息合并输出. SELECT CATCAT('hello','mysql') as test (2).CONCAT_WS(' ...
- 由ODI初始化资料档案库(RUC)引起修改ORACLE字符集(ZHS16GBK-AL32UTF8)
如果要部署代理,需要在RUC中进行资料档案库的初始化,这样可以免去配置代理的繁琐.在RUC连接数据库时会有先决条件检查,如果出现下图的警告,就需要在ORACLE中修改字符集. 具体操作如下: 登录SQ ...
- Exceptionless邮箱设置
在web.config中配置邮箱: <system.net> <mailSettings> <smtp from="xxx@163.com"> ...
- 推荐系统(Recommendation system )介绍
前言 随着电子商务的发展,网络购物成为一种趋势,当你打开某个购物网站比如淘宝.京东的时候,会看到很多给你推荐的产品,你是否觉得这些推荐的产品都是你似曾相识或者正好需要的呢.这个就是现在电子商务里面的推 ...
- 前端笔记之JavaScript面向对象(三)初识ES6&underscore.js&EChart.js&设计模式&贪吃蛇开发
一.ES6语法 ES6中对数组新增了几个函数:map().filter().reduce() ES5新增的forEach(). 都是一些语法糖. 1.1 forEach()遍历数组 forEach() ...
- 强化学习(四)用蒙特卡罗法(MC)求解
在强化学习(三)用动态规划(DP)求解中,我们讨论了用动态规划来求解强化学习预测问题和控制问题的方法.但是由于动态规划法需要在每一次回溯更新某一个状态的价值时,回溯到该状态的所有可能的后续状态.导致对 ...
- SOFARPC源码解析-搭建环境
文档地址:https://www.sofastack.tech 简介摘要 SOFA 是蚂蚁金服自主研发的金融级分布式中间件,包含构建金融级云原生架构所需的各个组件,包括微服务研发框架,RPC 框架,服 ...