中国农产品信息网站scrapy-redis分布式爬取数据
---恢复内容开始---
基于scrapy_redis和mongodb的分布式爬虫
项目需求:
1:自动抓取每一个农产品的详细数据
2:对抓取的数据进行存储
第一步:
创建scrapy项目


创建爬虫文件

在items.py里面定义我们要爬取的数据
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NongcpspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 供求关系
supply = scrapy.Field()
# 标题
title = scrapy.Field()
# 发布时间
create_time = scrapy.Field()
# 发布单位
unit = scrapy.Field()
# 联系人
contact = scrapy.Field()
# 手机号码
phone_number = scrapy.Field()
# 地址
address = scrapy.Field()
# 详细地址
detail_address = scrapy.Field()
# 上市时间
market_time = scrapy.Field()
# 价格
price = scrapy.Field()
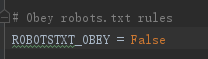
将settings.py改为false
写spider爬虫文件nongcp_spider.py,进行字段解析使用xpath,正则表达式
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import NongcpspiderItem
class NongcpSpiderSpider(scrapy.Spider):
name = 'nongcp_spider'
# allowed_domains = ['http://www.nongnet.com/']
start_urls = ['http://www.nongnet.com/']
def parse(self, response):
"""
解析详情页和下一页url
:param response:
:return:
"""
detail_urls = response.xpath('//li[@class="lileft"]/a/@href').extract()
for detail_url in detail_urls:
yield scrapy.Request(url=self.start_urls[0]+detail_url, callback=self.detail_parse)
next_url = response.xpath("//span[@id='ContentMain_lblPage']/a/@href").extract()
if next_url:
yield scrapy.Request(url=self.start_urls[0]+next_url[-2])
def detail_parse(self, response):
"""
解析具体的数据
:param response:
:return:
"""
items = NongcpspiderItem()
title_result = response.xpath('//h1[@class="h1class"]/text()').extract_first()
if title_result:
items['supply'] = title_result.strip()[1:2]
items['title'] = title_result.strip()[3:]
creatte_time = re.findall(r"<font color='999999'>时间:(\d+/\d+/\d+ \d+:\d+)  ", response.text)
if creatte_time:
items['create_time'] = creatte_time[0]
unit = re.findall(r"发布单位</div><div class='xinxisxr'><a href='.*?.aspx'>(.*?)</a>", response.text, re.S)
if unit:
items['unit'] = unit[0]
price = response.xpath('//div[@class="scdbj1"]/text()').extract()
if price:
items['price'] = ''.join(price)
yield items
编写pipelines.py,往mongodb里面存储数据
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
class NongcpspiderPipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
def __init__(self):
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
self.db = client['nong']
self.connection = self.db['Info']
self.dbinfo = self.db.authenticate('xxxx', 'xxxx')
def process_item(self, item, spider):
self.connection.save(dict(item))
return item
完成以上步骤就可以进行数据的爬取了,接下来我们来测试一下爬取的效果
编写启动脚本start.py
#encoding: utf-8
from scrapy import cmdline
# cmdline.execute("scrapy crawl qsbk_spider".split())
cmdline.execute(["scrapy", 'crawl', 'nongcp_spider'])
开启settings.py pipelines字段

运行程序,爬取到的效果如下

接下来实现分布式去重爬取
先安装scrapy-redis

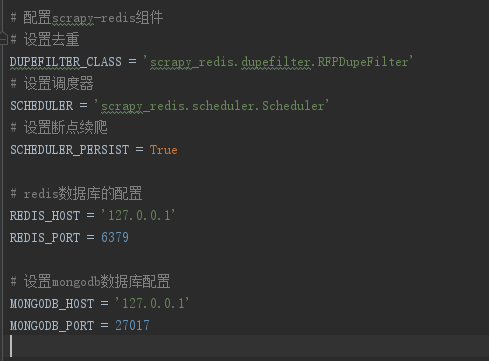
在settings.py里面配置scrapy-redis组件
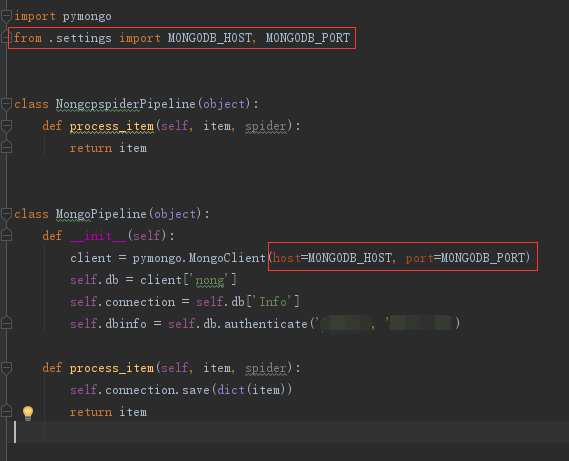
在pipelines.py引入mongdb配置
修改nongcp_spider.py文件
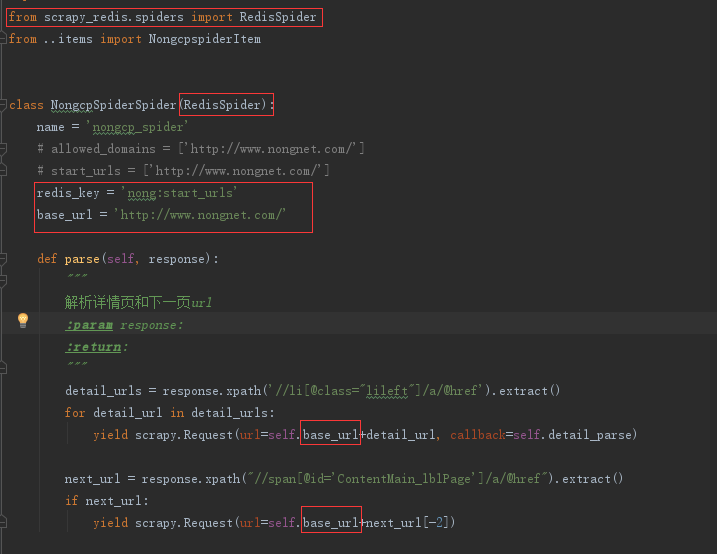
如果爬取过程中出现封ip的操作,我们可以设置middlewares.py,,在该文件设置代理
使用阿布云代理

先启动start.py文件,在运行redis-cli

然后就可以抓取数据了到mongdb里面了
---恢复内容结束---
中国农产品信息网站scrapy-redis分布式爬取数据的更多相关文章
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
- Scrapy持久化存储-爬取数据转义
Scrapy持久化存储 爬虫爬取数据转义问题 使用这种格式,会自动帮我们转义 'insert into wen values(%s,%s)',(item['title'],item['content' ...
- scrapy使用PhantomJS爬取数据
环境:python2.7+scrapy+selenium+PhantomJS 内容:测试scrapy+PhantomJS 爬去内容:涉及到js加载更多的页面 原理:配置文件打开中间件+修改proces ...
- scrapy-redis + Bloom Filter分布式爬取tencent社招信息
scrapy-redis + Bloom Filter分布式爬取tencent社招信息 什么是scrapy-redis 什么是 Bloom Filter 为什么需要使用scrapy-redis + B ...
- scrapy-redis分布式爬取tencent社招信息
scrapy-redis分布式爬取tencent社招信息 什么是scrapy-redis 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/tencent.py 编写 pip ...
- Scrapy 分布式爬取
由于受到计算机能力和网络带宽的限制,单台计算机运行的爬虫咋爬取数据量较大时,需要耗费很长时间.分布式爬取的思想是“人多力量大”,在网络中的多台计算机同时运行程序,公童完成一个大型爬取任务, Scrap ...
- scrapy-redis实现爬虫分布式爬取分析与实现
本文链接:http://blog.csdn.net/u012150179/article/details/38091411 一 scrapy-redis实现分布式爬取分析 所谓的scrapy-redi ...
- scrapy-redis分布式爬取知乎问答,使用docker布置多台机器。
先上结果: 问题: 答案: 可以看到现在答案文档有十万多,十万个为什么~hh 正文开始: 分布式爬虫应该是在多台服务器(A B C服务器)布置爬虫环境,让它们重复交叉爬取,这样的话需要用到状态管理器. ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
随机推荐
- [转载]AMOLED结构详解,BOE专家给你分析驱动补偿
关键词: AMOLED, 驱动补偿 有机发光显示二极管(OLED)作为一种电流型发光器件已越来越多地被应用于高性能显示中.由于它自发光的特性,与LCD相比,AMOLED具有高对比度.超轻薄.可弯曲等诸 ...
- bootstrap时时提醒填入数据是否与数据库数据重复
standardcode: { group: '.col-sm-4',//对应前台input的class占用宽度 validators: { notEmpty: { message: '请输入标准代号 ...
- 最简单的dockerfile使用教程 - 创建一个支持SSL的Nginx镜像
什么是dockerfile?简单的说就是一个文本格式的脚本文件,其内包含了一条条的指令(Instruction),每一条指令负责描述镜像的当前层(Layer)如何构建. 下面通过一个具体的例子来学习d ...
- 如何修改Fiori Launchpad里Tile计数调用的时间间隔
Fiori launchpad里的Tile上有一个数字,例如下图My Leads的例子:每隔指定的时间间隔,会向后台发起一次数据请求,读取当前Lead的个数. 这个请求可以在Chrome Develo ...
- python_列表/元组/元组列表以及如何使用
1.list是处理一组有序项目的数据结构 #定义一个列表 list=[1,2,3] print type(list) print list[0] 输出: <type 'list'> 1 2 ...
- 2016-2017 ACM Central Region of Russia Quarterfinal Programming Contest
2016-2017 ACM Central Region of Russia Quarterfinal Programming Contest A. Fried Fish 题意:有N条鱼,有一个同时可 ...
- VOJ1067 【矩阵经典7 构造矩阵】
任意门:https://vijos.org/records/5be95b65d3d8a1366270262b 背景 守望者-warden,长期在暗夜精灵的的首都艾萨琳内担任视察监狱的任务,监狱是成长条 ...
- 【转】深度分析Java的ClassLoader机制(源码级别)
原链接 Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中, JVM在加载类的时候,都是通过ClassLoa ...
- 调用URL 接口服务
1.Net调用URL 接口服务 using System; using System.Collections; using System.Configuration; using System.Dat ...
- 【luogu P1195 口袋的天空】 题解
题目链接:https://www.luogu.org/problemnew/show/P1195 嗯~我是被题目背景吸引到才做的,想吃棉花糖啦! 话说回来,这道题其实很容易就能想明白,k棵最小生成树. ...