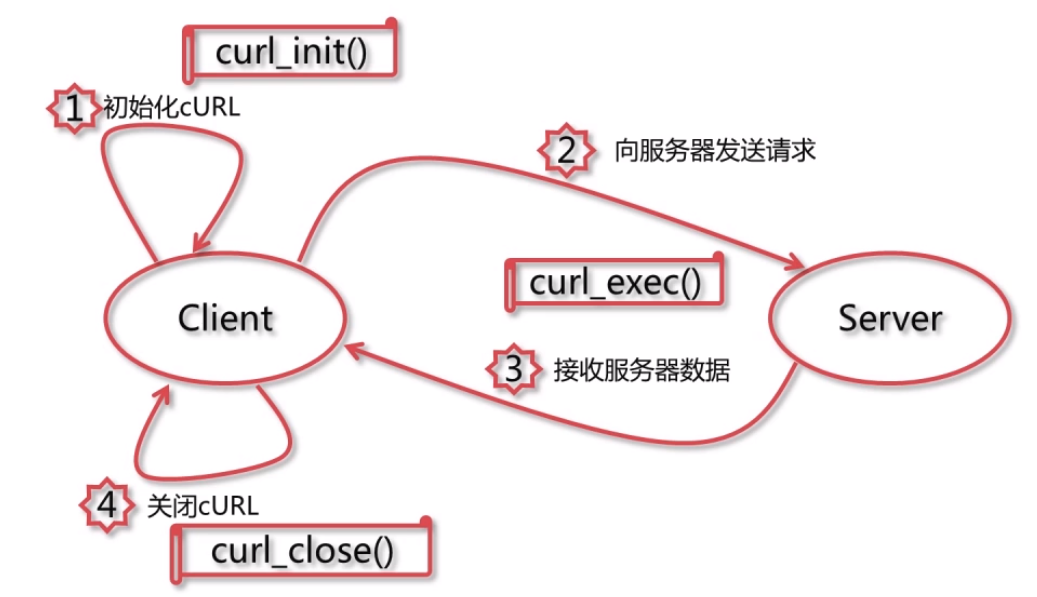
php爬虫神器cURL
cURL
网页资源(编写网页爬虫)
接口资源
ftp服务器文件资源
其他资源
static public function curl($url, $data = array(), $timeout = 5) {
$ch = curl_init ();
if (is_array ( $data ) && $data) {
// http_build_query — 生成 URL-encode 之后的请求字符串,支持数组提交
$formdata = http_build_query ( $data );
curl_setopt ( $ch, CURLOPT_POST, true );
curl_setopt ( $ch, CURLOPT_POSTFIELDS, $formdata );
}
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, true );
curl_setopt ( $ch, CURLOPT_CONNECTTIMEOUT, $timeout );
curl_setopt ( $ch, CURLOPT_TIMEOUT, $timeout );
$result = curl_exec ( $ch );
curl_close ( $ch );
return $result;
}
下面是简单的爬虫,爬网页数据。
<?php
/**
* 简单爬虫
*/
$ch = curl_init('http://www.baidu.com');
curl_exec($ch);
curl_close($ch);
替换爬出来的网页数据。
<?php
/**
* 简单爬虫
*/
$curlobj = curl_init();
curl_setopt($curlobj,CURLOPT_URL,"http://www.baidu.com"); // 设置抓取的网页
curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); // 设置不打印
$output=curl_exec($curlobj); // 执行
curl_close($curlobj); // 关闭
echo str_replace("百度","搜索",$output);
post调接口数据
http://ws.webxml.com.cn/WebServices/WeatherWS.asmx?op=getWeather

<?php
/**
* 简单爬虫
*/
$curlobj = curl_init();
$url = "http://ws.webxml.com.cn/WebServices/WeatherWS.asmx/getWeather";
$data= "theCityCode=宿迁&theUserID=6c0fbb1189324dfab6a66963738d768b"; // 麻痹,这个只能试用五天
curl_setopt($curlobj,CURLOPT_URL,$url); // 设置抓取的网页
curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); // 设置不打印
curl_setopt($curlobj,CURLOPT_POST,1); // 设置post
curl_setopt($curlobj,CURLOPT_POSTFIELDS,$data); // 设置post数据
$output=curl_exec($curlobj); // 执行
if(!curl_errno($curlobj)){ // 返回错误代码或在没有错误发生时返回 0 (零)。
echo $output;
} else {
echo 'Curl error:'.curl_error($curlobj);
}
curl_close($curlobj); // 关闭
<?xml version="1.0" encoding="utf-8"?>
<ArrayOfString xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns="http://WebXml.com.cn/">
<string>江苏 宿迁</string>
<string>宿迁</string>
<string>1907</string>
<string>2018/04/26 22:10:44</string>
<string>今日天气实况:气温:18℃;风向/风力:西南风 1级;湿度:78%</string>
<string>紫外线强度:弱。空气质量:良。</string>
<string>紫外线指数:弱,辐射较弱,涂擦SPF12-15、PA+护肤品。
健臻·血糖指数:较易波动,血糖较易波动,注意监测。
感冒指数:较易发,温差较大,较易感冒,注意防护。
穿衣指数:较舒适,建议穿薄外套或牛仔裤等服装。
洗车指数:较适宜,无雨且风力较小,易保持清洁度。
空气污染指数:良,气象条件有利于空气污染物扩散。
</string>
<string>4月26日 多云</string>
<string>13℃/23℃</string>
<string>南风3-4级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>4月27日 多云</string>
<string>11℃/26℃</string>
<string>东北风转东南风3-4级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>4月28日 多云</string>
<string>17℃/27℃</string>
<string>东南风3-4级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>4月29日 多云</string>
<string>19℃/28℃</string>
<string>东南风3-4级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>4月30日 多云</string>
<string>19℃/30℃</string>
<string>东南风转东风3-4级</string>
<string>1.gif</string>
<string>1.gif</string>
<string>5月1日 小雨</string>
<string>17℃/26℃</string>
<string>东北风4-5级</string>
<string>7.gif</string>
<string>7.gif</string>
<string>5月2日 多云转阴</string>
<string>11℃/27℃</string>
<string>东北风4-5级转无持续风向小于3级</string>
<string>1.gif</string>
<string>2.gif</string>
</ArrayOfString>
读取FTP数据
<?php
/**
* 简单爬虫
*/
$curlobj = curl_init();
$url = "ftp://192.168.199.126/info.txt";
curl_setopt($curlobj,CURLOPT_URL,$url); // 设置抓取的网页
curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); // 设置不打印
curl_setopt($curlobj,CURLOPT_HEADER,0);
curl_setopt($curlobj,CURLOPT_TIMEOUT,300); // 设置300秒的下载时间
$outfile = fopen('download_file.txt','wb'); // 保存到本地的文件名
curl_setopt($curlobj,CURLOPT_FILE,$outfile);
$r=curl_exec($curlobj); // 执行
fclose($outfile);
if(!curl_errno($curlobj)){ // 返回错误代码或在没有错误发生时返回 0 (零)。
echo "RETURN:" .$r;
} else {
echo 'Curl error:'.curl_error($curlobj);
}
curl_close($curlobj); // 关闭
RETURN:1
<?php
/**
* 简单爬虫
*/
$curlobj = curl_init();
$url = "ftp://192.168.199.126/info.txt";
curl_setopt($curlobj,CURLOPT_URL,$url); // 设置抓取的网页
curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); // 设置不打印
curl_setopt($curlobj,CURLOPT_HEADER,0);
curl_setopt($curlobj,CURLOPT_TIMEOUT,300); // 设置300秒的下载时间
//$outfile = fopen('download_file.txt','wb'); // 保存到本地的文件名
//curl_setopt($curlobj,CURLOPT_FILE,$outfile);
$r=curl_exec($curlobj); // 执行
//fclose($outfile);
if(!curl_errno($curlobj)){ // 返回错误代码或在没有错误发生时返回 0 (零)。
echo "RETURN:" .$r;
} else {
echo 'Curl error:'.curl_error($curlobj);
}
curl_close($curlobj); // 关闭
RETURN:hello world!
上传FTP数据
<?php
/**
* 简单爬虫
*/
$curlobj = curl_init();
$localfile = 'upload_file.txt';
$fp = fopen($localfile,'r');
$url = "ftp://192.168.199.126/upload/for_upload_file.txt"; // 确保目录有写权限
curl_setopt($curlobj,CURLOPT_URL,$url); // 设置抓取的网页
curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); // 设置不打印
curl_setopt($curlobj,CURLOPT_HEADER,0);
curl_setopt($curlobj,CURLOPT_TIMEOUT,300); // 设置300秒的下载时间
curl_setopt($curlobj,CURLOPT_UPLOAD,1);
curl_setopt($curlobj,CURLOPT_INFILE,$fp);
curl_setopt($curlobj,CURLOPT_INFILESIZE,filesize($localfile));
$r=curl_exec($curlobj); // 执行
fclose($fp);
if(!curl_errno($curlobj)){ // 返回错误代码或在没有错误发生时返回 0 (零)。
echo "RETURN:上传成功!";
} else {
echo 'Curl error:'.curl_error($curlobj);
}
curl_close($curlobj); // 关闭
还是很牛逼的,常用于post提交获取数据和爬虫获取资源。
php爬虫神器cURL的更多相关文章
- shell神器curl命令的用法 curl用法实例笔记
shell神器curl命令的用法举例,如下: ##基本用法(配合sed/awk/grep) $curl http://www.jquerycn.cn ##下载保存 $curl http://www.j ...
- 爬虫神器XPath,程序员带你免费获取周星驰等明星热门电影
本教程由"做全栈攻城狮"原创首发,本人大学生一枚平时还需要上课,但尽量每日更新文章教程.一方面把我所习得的知识分享出来,希望能对初学者有所帮助.另一方面总结自己所学,以备以后查看. ...
- cmder 神器 +curl
cmder 神器 https://www.jianshu.com/p/7a706c0a3411 curl https://www.cnblogs.com/zhuzhenwei918/p/6781314 ...
- Python爬虫利器 cURL你用过吗?
hello,小伙伴们,今天给大家分享的开源项目是一个python爬虫利器,感兴趣的小伙伴看完这篇文章不妨去尝试一下,这个开源项目就是curlconverter,不知道小伙伴们分析完整个网站后去code ...
- 网络爬虫2--PHP/CURL库(client URL Request Library)
PHP/CURL库功能 多种传输协议.CURL(client URL Request Library),含义是“客户端URL请求库”. 不像上一篇所用的PHP内置网络函数,PHP/CURL支持多种 ...
- python爬虫神器PyQuery的使用方法
你是否觉得 XPath 的用法多少有点晦涩难记呢? 你是否觉得 BeautifulSoup 的语法多少有些悭吝难懂呢? 你是否甚至还在苦苦研究正则表达式却因为少些了一个点而抓狂呢? 你是否已经有了一些 ...
- 爬虫神器xpath的用法(三)
xpath的多线程爬虫 #encoding=utf-8 ''' pool = Pool(4) cpu的核数为4核 results = pool.map(爬取函数,网址列表) ''' from mult ...
- App爬虫神器mitmproxy和mitmdump的使用
原文 mitmproxy是一个支持HTTP和HTTPS的抓包程序,有类似Fiddler.Charles的功能,只不过它是一个控制台的形式操作. mitmproxy还有两个关联组件.一个是mitmdum ...
- 爬虫神器xpath的用法(四)
使用xpath多线程爬取百度贴吧内容 #encoing=utf-8 from lxml import etree from multiprocessing.dummy import Pool as T ...
随机推荐
- ReflectionZ_测试_01
1.Java代码 public class TreflectionZ { public static void main(String[] args) throws Exception { Class ...
- LeetCode第[33]题(Java):Search in Rotated Sorted Array
题目:在翻转有序中搜索 难度:Medium 题目内容: Suppose an array sorted in ascending order is rotated at some pivot unkn ...
- 火车头采集器db3导出sql语句
1.通过火狐 sqlite mananger工具,将.db3文件,导出为.sql文件2.右击表面content,属性:Export table 3.不要勾选 include create table. ...
- CMD下利用subst命令将一个文件夹镜像成本地的一个虚拟磁盘
我们都知道net use可以建立网络驱动器映射,这里不说了. 我今天刚看到这命令的,叫镜像虚拟磁盘subst命令,这个命令可以简化好多操作,比如一个常用的文件放在一个路径很深的文件夹中,每次我们想要操 ...
- python 实现简单点名程序
程序会遍历文件所有姓名,遍历完之前不会有重复值,遍历所有后将提示推出. #-*-coding:utf-8-*-#author:wangxing #点名程序 import randomimport os ...
- InnoDB存储引擎的B+树索引算法
关于B+树数据结构 ①InnoDB存储引擎支持两种常见的索引. 一种是B+树,一种是哈希. B+树中的B代表的意思不是二叉(binary),而是平衡(balance),因为B+树最早是从平衡二叉树演化 ...
- ffmpeg推送RTSP直播流到EasyDarwin报错问题的修复
在之前的博客<ffmpeg推送,EasyDarwin转发,vlc播放 实现整个RTSP直播>中,我们介绍了如何采用ffmpeg进行RTSP推送,实现EasyDarwin直播分发的功能,近期 ...
- C语言中的extern关键字用法
在C语言中,修饰符extern用在变量或者函数的声明前,用来说明“此变量/函数是在别处定义的,要在此处引用”. 1. extern修饰变量的声明.举例来说,如果文件a.c需要引用b.c中变量int v ...
- JavaScript中的二分法插入算法
算法主体部分 var OnlineUser = { //list : 待查找的数组 //key : 待插入的值 //order : 数组的顺序 1:从小到大 0:从大到小 //start : 开始查找 ...
- (十七)js bom/dom
window 是所有BOM中所有对象的核心. window 的属性 window.self代表自己本身,相当于window. eg: console.log(window.self === windo ...