集腋成裘-11-sql性能优化
SQL Nexus是一个用于将SQL Trace数据、性能监视日志及T-SQL输出整合进一个单独的SQL Server数据库的工具。
先决条件
开始使用SQL Nexus之前,注意下面要做的事项:
- 安装Microsoft Report Viewer for SQL Server 2016 MSI控件,以便使用工具自带的客户端报表查看整合的报告;
- 安装Microsoft RML Utilities for SQL Server,以便SQL Nexus导入SQL Traces;
- 安装Microsoft System CLR Types for SQL Server 2016;
- 核实安装.NET Framework 4.7
一:问题定位
1:通过SQLserver自带的工具SQL Server Profiler
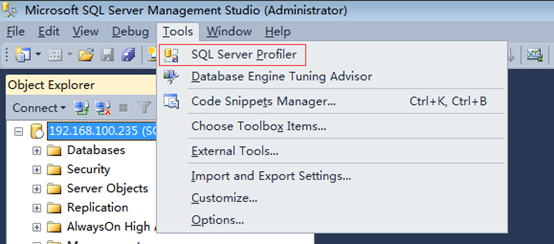
2:选择要监控的事件
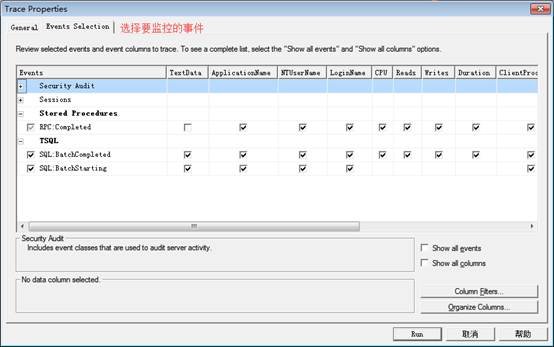
3:导出执行的脚本,将任务置于后台执行,提高效率
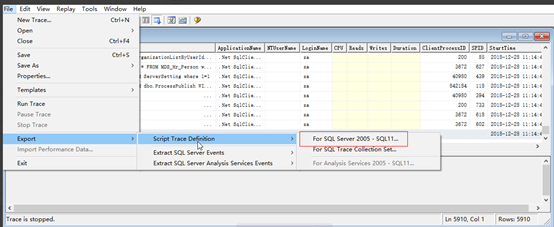
4:执行导出的脚本,目的是开启监控
/****************************************************/
/* Created by: SQL Server 2012 Profiler */
/* Date: 2019/01/16 21:18:17 */
/****************************************************/ -- Create a Queue
declare @rc int
declare @TraceID int
declare @maxfilesize bigint
set @maxfilesize = -- Please replace the text InsertFileNameHere, with an appropriate
-- filename prefixed by a path, e.g., c:\MyFolder\MyTrace. The .trc extension
-- will be appended to the filename automatically. If you are writing from
-- remote server to local drive, please use UNC path and make sure server has
-- write access to your network share exec @rc = sp_trace_create @TraceID output, , N'd:\a\logTrace', @maxfilesize, NULL
if (@rc != ) goto error -- Client side File and Table cannot be scripted -- Set the events
declare @on bit
set @on =
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on
exec sp_trace_setevent @TraceID, , , @on -- Set the Filters
declare @intfilter int
declare @bigintfilter bigint exec sp_trace_setfilter @TraceID, , , , N'SQL Server Profiler - 45caddf4-8520-4a3a-88c9-1afd4251fc0b'
-- Set the trace status to start
exec sp_trace_setstatus @TraceID, -- display trace id for future references
select TraceID=@TraceID
goto finish error:
select ErrorCode=@rc finish:
go
开启监控(Trace)的脚本
5:检查步骤4执行的效果。
--查看所有的trace
select * from sys.traces
--设置trace的状态 0代表停止,1代表开启,2代表删除,第一个参数代表traceid
--sp_trace_setstatus ,
--go
--sp_trace_setstatus ,
--go
--sp_trace_setstatus ,

二、使用sqlnexus统计数据
1:连接服务器,为了方便把一中5的日志记录创建到该服务器的数据库

2:导入文本
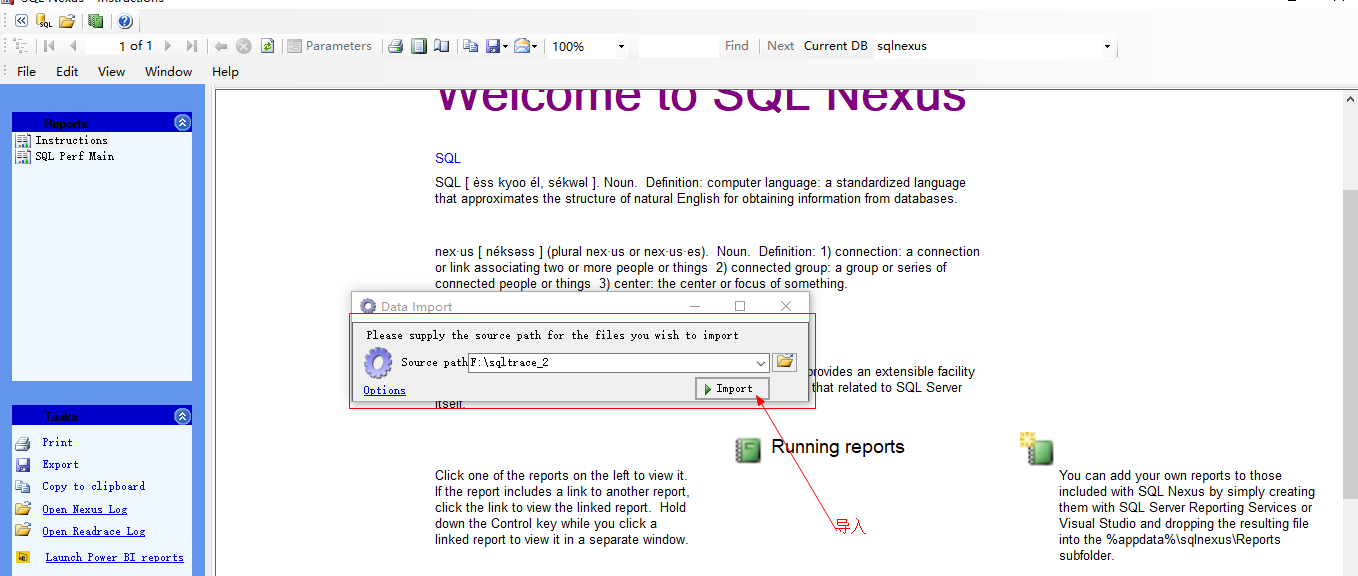
3:主要看以下几个指标

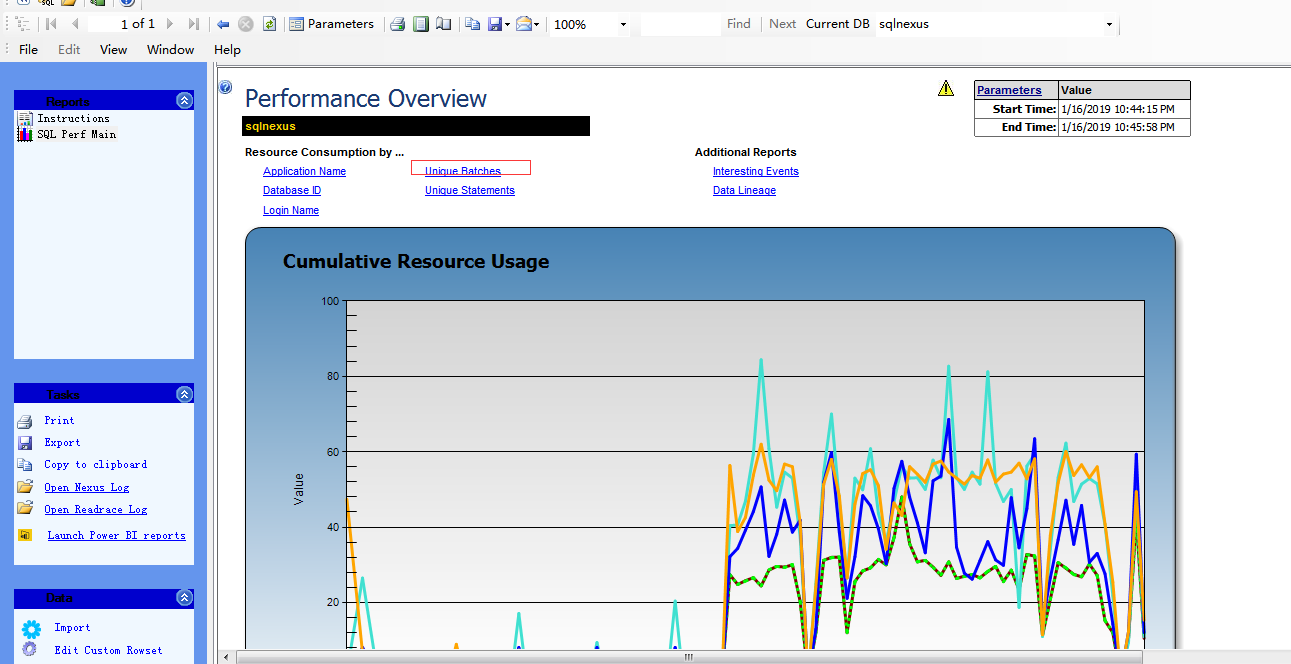
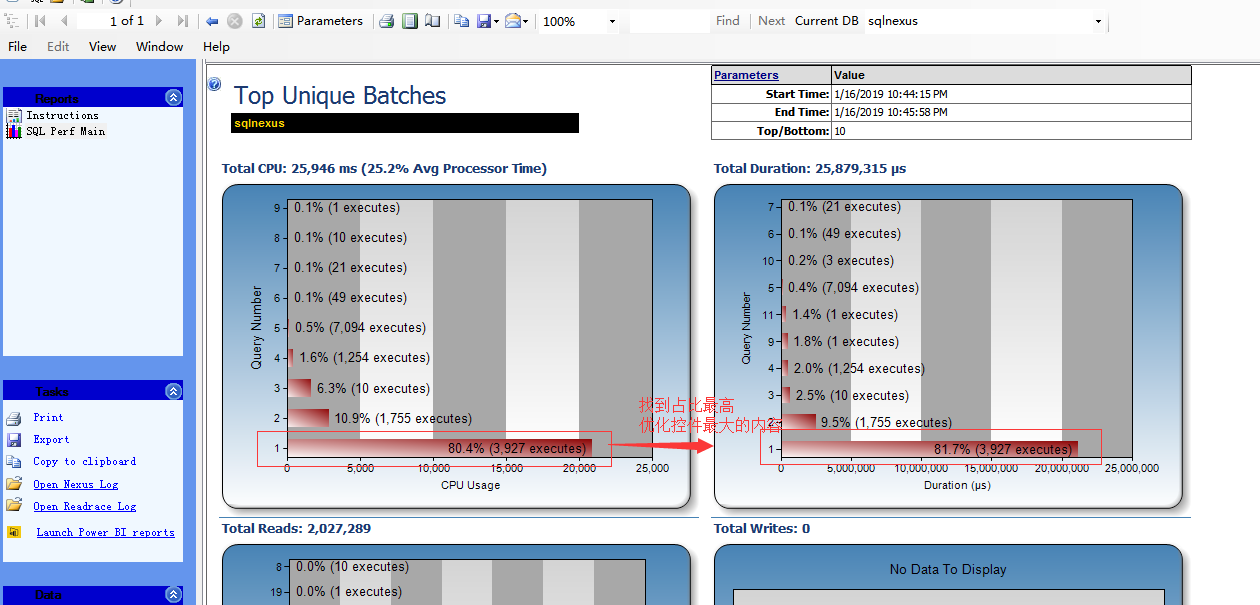
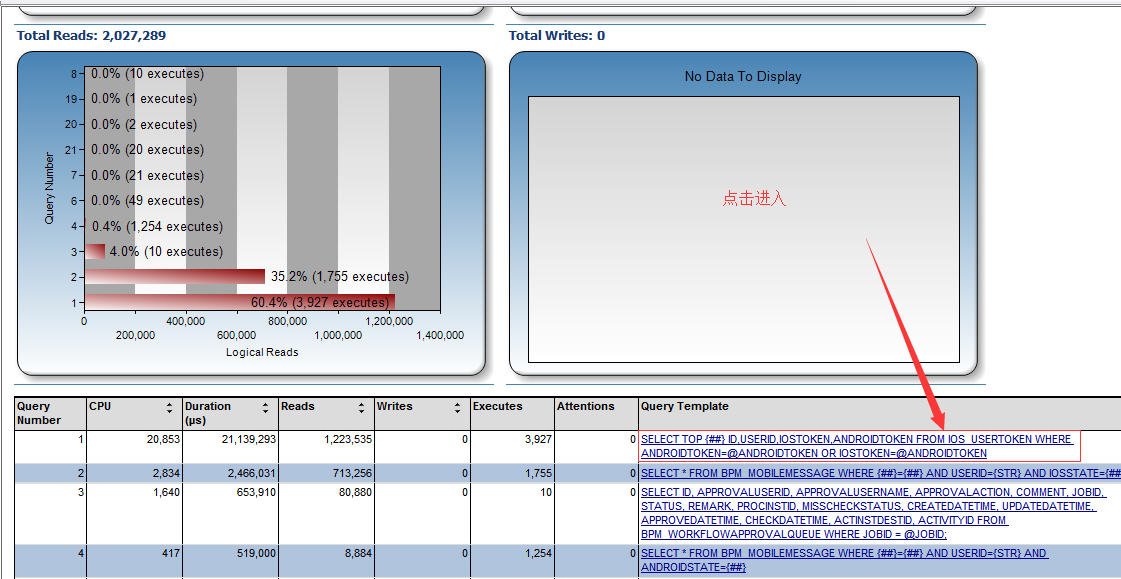

三、提取并且优化sql
(1)sql语句参数化,或将其修改为存储过程。
理由1:未参数化的sql除非每次执行的语句完全一致否则每一次执行都将会先去执行编译,下面将展示此过程
--步骤1:在Manage studio当中打开统计功能
SET STATISTICS IO ON --展示IO读写
SET STATISTICS TIME ON --展示执行时间
GO
--步骤2:执行sql语句
declare @P0001 nvarchar(124)
set @P0001 = N'select top 1 ID,UserId,IosToken,AndroidToken from IOS_UserToken where AndroidToken=@AndroidToken or IosToken=@AndroidToken'
declare @P0002 nvarchar(26)
set @P0002 = N'@AndroidToken varchar(100)'
declare @P0003 varchar(100)
set @P0003 = 'f02b23dd0c59a143e979616b1023411f6f350cb814be7c30989e8987aadcd9c4'
exec sp_executesql @P0001, @P0002, @AndroidToken = @P0003

四、临时紧急处理
熔断:服务调用的一种雪崩现象,通过截断对依赖服务的调用来保证调用端的可用性。
(1) 控制资源申请:控制cpu的消耗,既单个脚本占用cpu的核数,防止某一个长时间操作占用大量cpu。设置标准:qps高的情况下将cpu执行数往低设置,当qps低的情况下将cpu并行数据往高处设置,最高不要超过8。

限流:通过限制对服务的调用访问来保证服务端的可用性。

降级:通过放弃对非核心服务的调用,来保证核心服务的可用性。
扩容:通过增加服务的数量来保证服务的可用性。
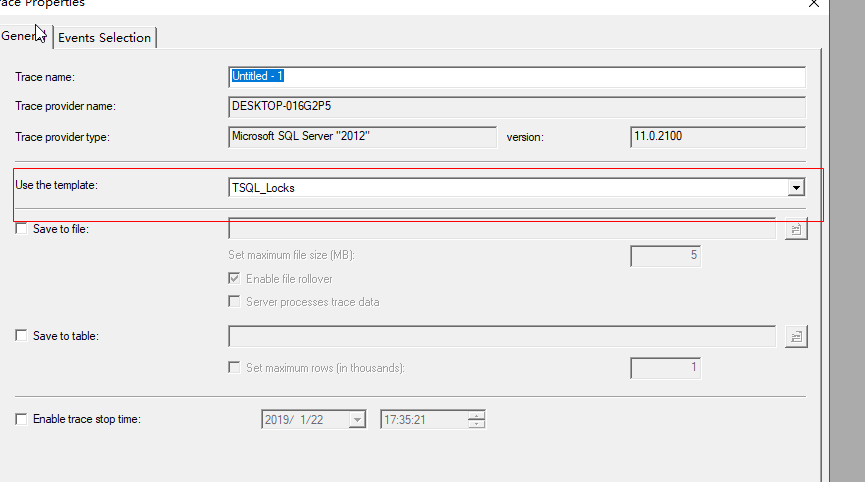
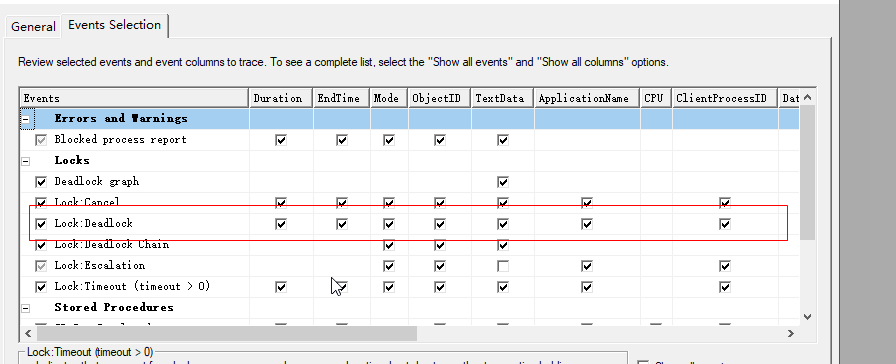
五、查看数据库死锁问题(模板换一下)
集腋成裘-11-sql性能优化的更多相关文章
- SQL性能优化
引言: 以前在面试的过程中,总有面试官问道:你做过sql性能优化吗?对此,我的答复是没有.一次没有不是自己的错误,两次也不是,但如果是多次呢?今天痛下决心,把有关sql性能优化的相关知识总结一下,以便 ...
- 如何进行正确的SQL性能优化
在SQL查询中,为了提高查询的效率,我们常常采取一些措施对查询语句进行SQL性能优化.本文我们总结了一些优化措施,接下来我们就一一介绍. 1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE ...
- 如何进行SQL性能优化
在SQL查询中,为了提高查询的效率,我们常常采取一些措施对查询语句进行SQL性能优化.本文我们总结了一些优化措施,接下来我们就一一介绍. 1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE ...
- 关于SQL性能优化的十条经验
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便会 ...
- ORACLE数据库学习之SQL性能优化详解
Oracle sql 性能优化调整 ...
- SQL 性能优化 总结
SQL 性能优化 总结 (1)选择最有效率的表名顺序(只在基于规则的优化器中有效): ORACLE的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driving ...
- Oracle SQL性能优化技巧大总结
http://wenku.baidu.com/link?url=liS0_3fAyX2uXF5MAEQxMOj3YIY4UCcQM4gPfPzHfFcHBXuJTE8rANrwu6GXwdzbmvdV ...
- Oracle SQL 性能优化技巧
Select语句完整的执行顺序: SQL Select语句完整的执行顺序: 1. from子句组装来自不同数据源的数据: 2.where子句基于指定的条件对记录行进行筛选: 3.group by子句将 ...
- 兄弟连教育分享-SQL性能优化十条经验
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'——红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 兄弟连教育分享-SQL性能优化十条经验 解决办法: 其 ...
- SQL性能优化概要
基本概要 1.查询的模糊匹配时,避免使用Like '%开头',使得索引失效 2.索引问题 ◆ 避免对索引字段进行运算操作和使用函数 ◆ 避免在索引字段上使用not,<>,!= ◆ 避免在索 ...
随机推荐
- 消息队列与Kafka
2019-04-09 关键词: 消息队列.为什么使用消息队列.消息队列的好处.消息队列的意义.Kafka是什么 本篇文章系本人就当前所掌握的知识关于 消息队列 与 kafka 知识点的一些简要介绍,不 ...
- 内置函数(sorted、map、enumerate、filter、reduce)
1.sorted() 语法: sorted(iterable, cmp=None, key=None, reverse=False) 把iterable中的items进行排序之后,返回一个新的列表,原 ...
- Scrapy 框架简介
Scrapy 框架 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的 ...
- vscode常用插件
vscode写JS/html/css是比较适合的,因为轻量级. 只是需要一些插件来完善VSCODE功能,感觉VSCODE就是要靠插件的,不然的话,只是一个高级的代码编辑器.可能比editplus&qu ...
- 20165223 《信息安全系统设计基础》 stat命令的实现-mysate
学习使用stat(1),并用C语言实现 1. 提交学习 stat(1) 的截图 2. man -k ,grep -r的使用 ...
- 牛客小白月赛13-J小A的数学题 (莫比乌斯反演)
链接:https://ac.nowcoder.com/acm/contest/549/J来源:牛客网 题目描述 小A最近开始研究数论题了,这一次他随手写出来一个式子,∑ni=1∑mj=1gcd(i,j ...
- c do{}while(0)
1 goto bool foo(){ int *p = (int*)malloc(5*sizeof(int)); bool bOk = true;//执行并处理错误 if(!fun1()) goto ...
- shiro 介绍和基本使用
一.什么是shiro 它是一个功能强大且易于使用的Java安全框架,可以执行身份验证.授权.加密和会话管理.使用Shiro易于理解的API,您可以快速且轻松地保护任何应用程序——从最小的移动应用程序到 ...
- 浅析HTTP代理原理--转
代理服务器是HTTP协议中一个重要的组件,发挥着重要的作用. 关于HTTP代理的文章有很多,本文不再赘述,如果不清楚的可以看一下 HTTP代理的基础知识. 本文主要介绍代理的事例,分析一个真实的案例来 ...
- Person Transfer GAN to Bridge Domain Gap for Person Re-identification
目录 相关背景 主要内容 MSMT17 Person Transfer GAN(PTGAN) 总结 注:原创不易,转载请务必注明原作者和出处,感谢支持! 相关背景 行人再识别(Person Re-id ...