局部敏感哈希(LSH)之simhash和minhash
minhash
1. 把文档A分词形成分词向量L
2. 使用K个hash函数,然后每个hash将L里面的分词分别进行hash,然后得到K个被hash过的集合
3. 分别得到K个集合中的最小hash,然后组成一个长度为K的hash集合
4. 最后用Jaccard index求出两篇文档的相似度
simhash
1. 把文档A分词形成分词向量L,L中的每一个元素都包涵一个分词C以及一个分词的权重W
2. 对L中的每一个元素的分词C进行hash,得到C1,然后组成一个新的向量L1
3. 初始化一个长度大于C1长度的向量V,所有元素初始化为0
4. 分别判断L1中的每一个元素C1的第i位,如果C1i是1,那么Vi加上w,否则Vi减去w
5. 最后判断V中的每一项,如果第i项大于0,那么第i项变成1,否则变成0
6. 两篇文档a,b分别得到aV,bV
6. 最后求出aV和bV的海明距离,一般距离不大于3的情况下说明两篇文档是相似的
SimHash的工作原理


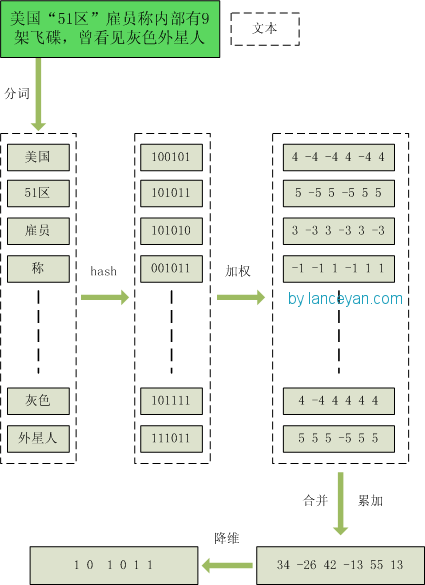
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程图为:


局部敏感哈希(LSH)之simhash和minhash的更多相关文章
- 海量数据挖掘MMDS week7: 局部敏感哈希LSH(进阶)
http://blog.csdn.net/pipisorry/article/details/49686913 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- [机器学习] 在茫茫人海中发现相似的你:实现局部敏感哈希(LSH)并应用于文档检索
简介 局部敏感哈希(Locality Sensitive Hasing)是一种近邻搜索模型,由斯坦福大学的Mose Charikar提出.我们用一种随机投影(Random Projection)的方式 ...
- 局部敏感哈希LSH
之前介绍了Annoy,Annoy是一种高维空间寻找近似最近邻的算法(ANN)的一种,接下来再讨论一种ANN算法,LSH局部敏感哈希. LSH的基本思想是: 原始空间中相邻的数据点通过映射或投影变换后, ...
- 局部敏感哈希LSH(Locality-Sensitive Hashing)——海量数据相似性查找技术
一. 前言 最近在工作中需要对海量数据进行相似性查找,即对微博全量用户进行关注相似度计算,计算得到每个用户关注相似度最高的TOP-N个用户,首先想到的是利用简单的协同过滤,先定义相似性度量(c ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍 本文主要介绍一种用于海量高维数据的近似近期邻高速查找技术--局部敏感哈希(Locality-Sensitive ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)
本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive Hashing, LSH),内容包括了LSH的原理.LSH哈希函数集.以及LSH的一些参 ...
- 局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍(转)
局部敏感哈希(Locality-Sensitive Hashing, LSH)方法介绍 本文主要介绍一种用于海量高维数据的近似最近邻快速查找技术——局部敏感哈希(Locality-Sensitive ...
- 海量数据挖掘MMDS week2: 局部敏感哈希Locality-Sensitive Hashing, LSH
http://blog.csdn.net/pipisorry/article/details/48858661 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- [Algorithm] 局部敏感哈希算法(Locality Sensitive Hashing)
局部敏感哈希(Locality Sensitive Hashing,LSH)算法是我在前一段时间找工作时接触到的一种衡量文本相似度的算法.局部敏感哈希是近似最近邻搜索算法中最流行的一种,它有坚实的理论 ...
- 局部敏感哈希算法(Locality Sensitive Hashing)
from:https://www.cnblogs.com/maybe2030/p/4953039.html 阅读目录 1. 基本思想 2. 局部敏感哈希LSH 3. 文档相似度计算 局部敏感哈希(Lo ...
随机推荐
- 利用Python爬去囧网福利(多线程、urllib、request)
import os; import urllib.request; import re; import threading;# 多线程 from urllib.error import URLErro ...
- linux为什么不可以添加硬链接
假设有个文件夹1 文件夹1里面还有个文件夹2 文件夹2里面还有个文件夹3 然后发现哎呀直接文件夹3放到文件夹1下就行了访问多方便. 也就是文件夹1下有文件夹2和文件夹3,然后问题就来了文件夹1下的文件 ...
- 监控mysql
Mysql服务器监控 管理MySql服务器属于应用程序监控范畴.这是因为绝大多数性能参数是有MySql软件产生的,而不属于主操作系统的一部分. 如当前所提到的,应该总是先监控基础操作系统,然后监控My ...
- Magicodes.NET框架之路——产品之路(谈谈产品管理)
虽然Magicodes.NET现在还不属于产品,但是却不妨碍她想成为产品的心. 为什么突然有了此篇,这篇不是空穴来风,而是我思考良久的结果: 为了让大家知道我在干什么,我想干什么,我将要干什么还有我干 ...
- [二]Java虚拟机 jvm内存结构 运行时数据内存 class文件与jvm内存结构的映射 jvm数据类型 虚拟机栈 方法区 堆 含义
前言简介 class文件是源代码经过编译后的一种平台中立的格式 里面包含了虚拟机运行所需要的所有信息,相当于 JVM的机器语言 JVM全称是Java Virtual Machine ,既然是虚拟机, ...
- [十一]基础数据类型之Character
Character与Unicode Character 基本数据类型char 的包装类 Character 类型的对象包含一个 char 类型的字段 该类提供了几种方法来确定字符的类别(小写字母 ...
- 【MongoDB】MongoDB环境配置
软件下载与安装 1.mongDB下载,可到官网下载,我用的是3.4.6版本.可以放到任意目录下,我的MongDB安装目录为 D:\software\small_softeware\MongoDB 2. ...
- 第56章 Client - Identity Server 4 中文文档(v1.0.0)
该Client模型的OpenID Connect或OAuth 2.0 客户端-例如,本地应用,Web应用程序或基于JS的应用程序. 56.1 Basics Enabled 指定是否启用客户端.默认为t ...
- MEF 基础简介 一
前言 小编菜鸟级别的程序员最近感慨颇多,经历了三五春秋深知程序路途遥远而我沧海一粟看不到的尽头到不了的终点何处是我停留的驿站.说了段废话下面进入正题吧! 什么是MEF? MEF:全称Managed E ...
- 利用 c# linq 实现跨数据库的联合查询
有个需求就是,我们要查询的信息分布在两个不同的数据库中,通过外键相互关联起来,然后返回datatable在前端展示内容. 根据需求我们可以考虑c#的linq 先在从不同的数据中获取相关的datatab ...