pytorch: 准备、训练和测试自己的图片数据
大部分的pytorch入门教程,都是使用torchvision里面的数据进行训练和测试。如果我们是自己的图片数据,又该怎么做呢?
一、我的数据
我在学习的时候,使用的是fashion-mnist。这个数据比较小,我的电脑没有GPU,还能吃得消。关于fashion-mnist数据,可以百度,也可以 点此 了解一下,数据就像这个样子:

下载地址:https://github.com/zalandoresearch/fashion-mnist
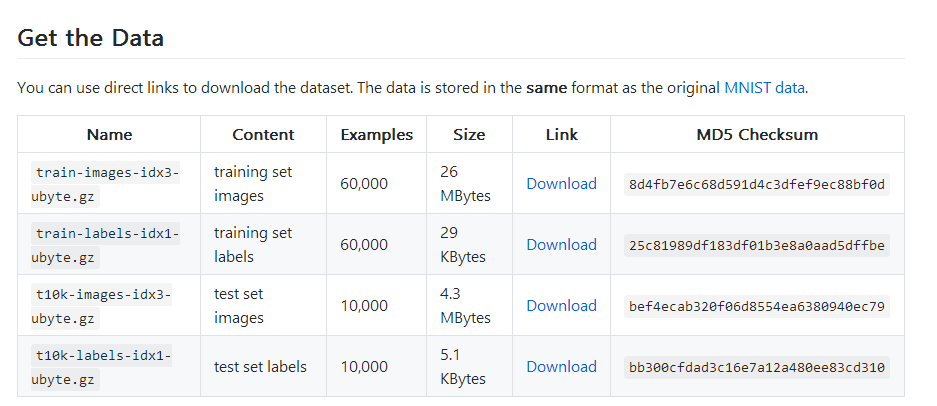
但是下载下来是一种二进制文件,并不是图片,因此我先转换成了图片。
我先解压gz文件到e:/fashion_mnist/文件夹
然后运行代码:
import os
from skimage import io
import torchvision.datasets.mnist as mnist root="E:/fashion_mnist/"
train_set = (
mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte'))
)
test_set = (
mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte'))
)
print("training set :",train_set[0].size())
print("test set :",test_set[0].size()) def convert_to_img(train=True):
if(train):
f=open(root+'train.txt','w')
data_path=root+'/train/'
if(not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(train_set[0],train_set[1])):
img_path=data_path+str(i)+'.jpg'
io.imsave(img_path,img.numpy())
f.write(img_path+' '+str(label)+'\n')
f.close()
else:
f = open(root + 'test.txt', 'w')
data_path = root + '/test/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(test_set[0],test_set[1])):
img_path = data_path+ str(i) + '.jpg'
io.imsave(img_path, img.numpy())
f.write(img_path + ' ' + str(label) + '\n')
f.close() convert_to_img(True)
convert_to_img(False)
这样就会在e:/fashion_mnist/目录下分别生成train和test文件夹,用于存放图片。还在该目录下生成了标签文件train.txt和test.txt.
二、进行CNN分类训练和测试
先要将图片读取出来,准备成torch专用的dataset格式,再通过Dataloader进行分批次训练。
代码如下:
import torch
from torch.autograd import Variable
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
root="E:/fashion_mnist/" # -----------------ready the dataset--------------------------
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataset(Dataset):
def __init__(self, txt, transform=None, target_transform=None, loader=default_loader):
fh = open(txt, 'r')
imgs = []
for line in fh:
line = line.strip('\n')
line = line.rstrip()
words = line.split()
imgs.append((words[0],int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader def __getitem__(self, index):
fn, label = self.imgs[index]
img = self.loader(fn)
if self.transform is not None:
img = self.transform(img)
return img,label def __len__(self):
return len(self.imgs) train_data=MyDataset(txt=root+'train.txt', transform=transforms.ToTensor())
test_data=MyDataset(txt=root+'test.txt', transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_data, batch_size=64) #-----------------create the Net and training------------------------ class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(3, 32, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2))
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 64, 3, 1, 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(2)
)
self.dense = torch.nn.Sequential(
torch.nn.Linear(64 * 3 * 3, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 10)
) def forward(self, x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
conv3_out = self.conv3(conv2_out)
res = conv3_out.view(conv3_out.size(0), -1)
out = self.dense(res)
return out model = Net()
print(model) optimizer = torch.optim.Adam(model.parameters())
loss_func = torch.nn.CrossEntropyLoss() for epoch in range(10):
print('epoch {}'.format(epoch + 1))
# training-----------------------------
train_loss = 0.
train_acc = 0.
for batch_x, batch_y in train_loader:
batch_x, batch_y = Variable(batch_x), Variable(batch_y)
out = model(batch_x)
loss = loss_func(out, batch_y)
train_loss += loss.data[0]
pred = torch.max(out, 1)[1]
train_correct = (pred == batch_y).sum()
train_acc += train_correct.data[0]
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
train_data)), train_acc / (len(train_data)))) # evaluation--------------------------------
model.eval()
eval_loss = 0.
eval_acc = 0.
for batch_x, batch_y in test_loader:
batch_x, batch_y = Variable(batch_x, volatile=True), Variable(batch_y, volatile=True)
out = model(batch_x)
loss = loss_func(out, batch_y)
eval_loss += loss.data[0]
pred = torch.max(out, 1)[1]
num_correct = (pred == batch_y).sum()
eval_acc += num_correct.data[0]
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_data)), eval_acc / (len(test_data))))
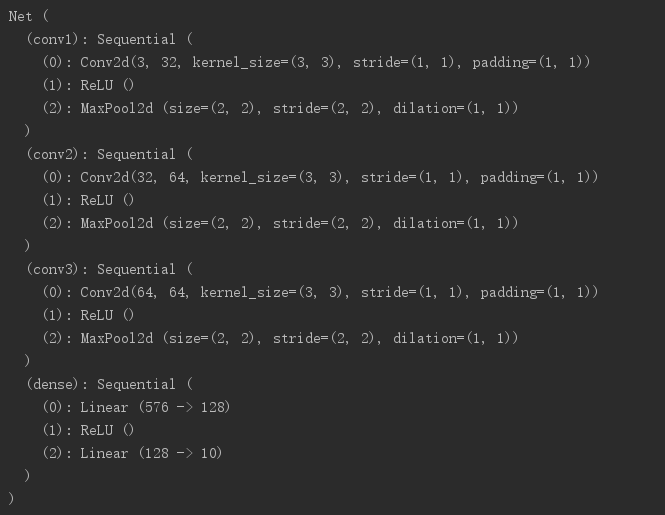
打印出来的网络模型:
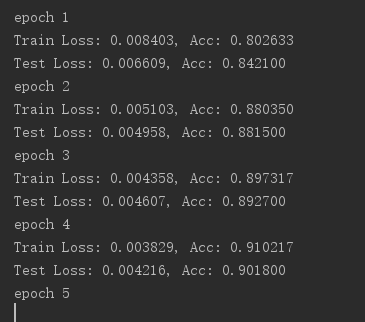
训练和测试结果:
pytorch: 准备、训练和测试自己的图片数据的更多相关文章
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- caffe学习系列(2):训练和测试自己的图片
参考:http://www.cnblogs.com/denny402/p/5083300.html 上述主要介绍的是从自己的原始图片转为lmdb数据,再到训练.测试的整个流程(另外可参考薛开宇的笔记) ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 使用LeNet训练自己的手写图片数据
一.前言 本文主要尝试将自己的数据集制作成lmdb格式,送进lenet作训练和测试,参考了http://blog.csdn.net/liuweizj12/article/details/5214974 ...
- 用python制作训练集和测试集的图片名列表文本
# -*- coding: utf-8 -*- from pathlib import Path #从pathlib中导入Path import os import fileinput import ...
- Ubuntu16.04下caffe CPU版的图片训练和测试
一 数据准备 二.转换为lmdb格式 1.首先,在examples下面创建一个myfile的文件夹,来用存放配置文件和脚本文件.然后编写一个脚本create_filelist.sh,用来生成train ...
- 随机切分csv训练集和测试集
使用numpy切分训练集和测试集 觉得有用的话,欢迎一起讨论相互学习~Follow Me 序言 在机器学习的任务中,时常需要将一个完整的数据集切分为训练集和测试集.此处我们使用numpy完成这个任务. ...
- Windows下mnist数据集caffemodel分类模型训练及测试
1. MNIST数据集介绍 MNIST是一个手写数字数据库,样本收集的是美国中学生手写样本,比较符合实际情况,大体上样本是这样的: MNIST数据库有以下特性: 包含了60000个训练样本集和1000 ...
随机推荐
- keras安装-【老鱼学keras】
为何要用keras? 两个字:简单. Keras让深度学习像搭建积木一样方便地来进行,使前面的tensorflow能够更加方便地使用. 虽然还有其它更多的理由,比如:Keras 支持多个后端引擎,不会 ...
- Python 常用Web框架的比较
转载来自:https://www.cnblogs.com/sunshine-1/p/7372934.html 从GitHub中整理出的15个最受欢迎的Python开源框架.这些框架包括事件I/O,OL ...
- stylus 样式
- 向mysql中导入向导时如表xlsx
如果出现这种问题那么是因为没有打开这个文件,如果想导入这个文件需要到开这个文件,然后再导入
- Array库
/** * 查找元素在数组中出现的所有位置 * @param {要查找的数组} array * @param {要查找的元素} ele * @param {回调函数} callback */ func ...
- 印象笔记 MAC安装使用旧版本
印象笔记终于支持markdown了,赞! 第一个beta版用起来非常不错.提示更新安装新版本后保存markdown一直提示 "Note content is invalid.",无 ...
- BZOJ 2169
$f_{ij}$ 表示加入 $i$ 条边, $j$ 个点的度数是奇数的方案数,然后暴力 #include<bits/stdc++.h> using namespace std; #defi ...
- jQuery(一)
jquery介绍 jQuery是目前使用最广泛的javascript函数库.据统计,全世界排名前100万的网站,有46%使用jQuery,远远超过其他库.微软公司甚至把jQuery作为他们的官方库. ...
- 13-事务&数据库连接池&DBUtiles
事务&数据库连接池&DBUtils 事务 Transaction 其实指的一组操作,里面包含许多个单一的逻辑.只要有一个逻辑没有执行成功,那么都算失败. 所有的数据都回归到最初的状态 ...
- java 新手指南
Java新手指南 不小心走上了一条不归路的我 因为对可视化感兴趣,然后学了MFC,发现MFC好麻烦啊,不如开发APP吧,刚学开发APP,艹,居然是用java做开发,那只好学java了,,呜呜,不知道什 ...