Hive SQL 分类
题目:
请使用Hive SQL实现下面的题目。
下面是一张表名为user_buy_log的表,有三个字段,user(用户),grp(分组编号),time(购物时间)。
需要将用户按照grp分组,对time进行升序排序,
如果用户间购物时间间隔小于5分钟,则认为是一个小团体,标号为1;
如果时间间隔大于5分,标号开始累加1。
|
user |
grp |
time |
|
num15 |
B |
2019-01-06 13:44:20.0 |
|
num17 |
B |
2019-01-06 13:47:24.0 |
|
num10 |
A |
2019-01-09 15:45:50.0 |
|
num18 |
B |
2019-01-06 13:47:49.0 |
|
num16 |
B |
2019-01-06 13:46:40.0 |
|
num3 |
A |
2019-01-09 11:21:12.0 |
|
num4 |
A |
2019-01-09 11:24:42.0 |
|
num1 |
A |
2019-01-09 09:16:08.0 |
|
num12 |
B |
2019-01-06 13:43:32.0 |
|
num13 |
B |
2019-01-06 13:43:44.0 |
|
num2 |
A |
2019-01-09 09:17:11.0 |
|
num7 |
A |
2019-01-09 15:42:28.0 |
|
num11 |
A |
2019-01-09 15:46:05.0 |
|
num5 |
A |
2019-01-09 11:24:53.0 |
|
num9 |
A |
2019-01-09 15:45:32.0 |
|
num8 |
A |
2019-01-09 15:43:02.0 |
|
num6 |
A |
2019-01-09 11:25:04.0 |
|
num14 |
B |
2019-01-06 13:44:06.0 |
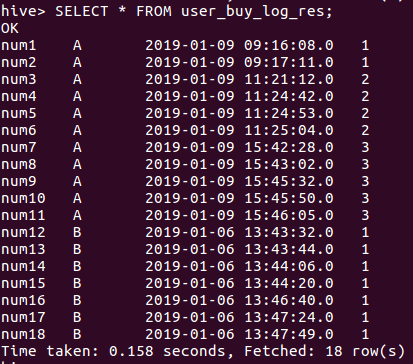
最终输出结果表名:user_buy_log_res,结果如下:
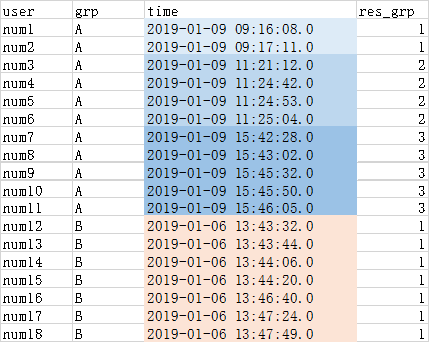
结果解析:
由于num1,num2时间间隔小于5分钟,而且他们是组A的最开始的分组,因此组号(res_grp)为1。
由于num3与num2的时间间隔超过5分钟,因此num3的组号(res_grp)开始累加,因此(res_grp)为2。
Num7跟num6的间隔超过5分钟,num7组号(res_grp)开始再次累加,因此(res_grp)为3。
num12是属于新的分组B,因此其(res_grp)重新从1开始编号,因为后续用户的购物时间间隔都小于5分钟,因此编号没有再累加。
解决办法:
set hive.support.sql11.reserved.keywords=false;
create database tab
use tab
create table user_buy_log (user string, grp string,time string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
load data local inpath '/home/hadoop/Desktop/user_buy_log.txt' into table user_buy_log;
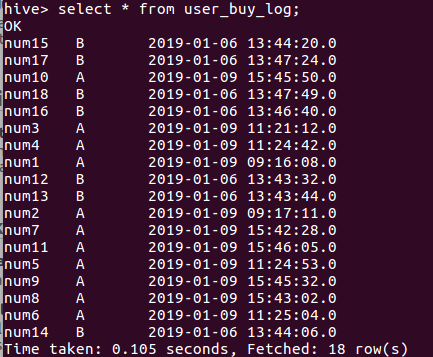
CREATE TABLE user_buy_log_1 AS
SELECT user,grp,time,
CAST(( UNIX_TIMESTAMP(time)-UNIX_TIMESTAMP(lag(time) over(PARTITION BY grp ORDER BY time ASC)))/60 AS INT) period,
row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num
FROM user_buy_log;
SELECT * FROM user_buy_log_1;
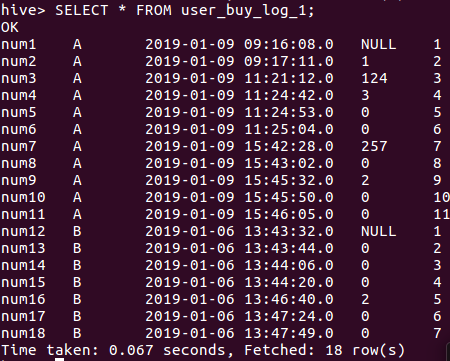
CREATE TABLE user_buy_log_2 AS
SELECT user,grp,time, period , row_num,CASE
WHEN period > 5 THEN 2
WHEN period is null THEN 1
ELSE NULL
END
AS res_grp
FROM user_buy_log_1;
SELECT * FROM user_buy_log_2;
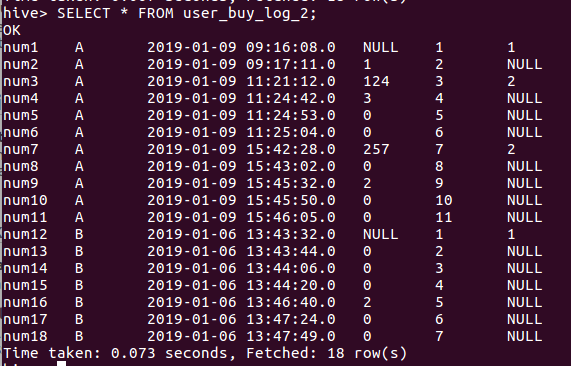
CREATE TABLE user_buy_log_3 AS
SELECT user,grp,time,row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num
FROM user_buy_log_2
WHERE res_grp is not null;
SELECT * FROM user_buy_log_3;
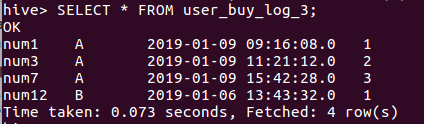
CREATE TABLE user_buy_log_4 AS
SELECT t2.user,t2.grp,t2.time,t2.row_num,t3.row_num AS res_grp
FROM user_buy_log_2 t2
LEFT JOIN user_buy_log_3 t3
ON t2.user = t3.user;
SELECT * FROM user_buy_log_4;
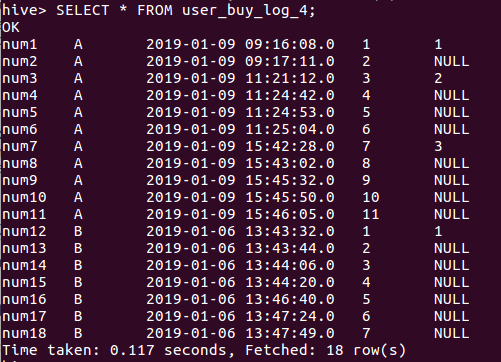
CREATE TABLE user_buy_log_res AS
SELECT user,grp,time,
MAX(res_grp) over(PARTITION BY grp ORDER BY time ASC) AS res_grp
FROM user_buy_log_4;
SELECT * FROM user_buy_log_res;
所有代码:
set hive.support.sql11.reserved.keywords=false; create database tab use tab create table user_buy_log (user string, grp string,time string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE; load data local inpath '/home/hadoop/Desktop/user_buy_log.txt' into table user_buy_log; CREATE TABLE user_buy_log_1 AS
SELECT user,grp,time,
CAST(( UNIX_TIMESTAMP(time)-UNIX_TIMESTAMP(lag(time) over(PARTITION BY grp ORDER BY time ASC)))/60 AS INT) period,
row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num
FROM user_buy_log; SELECT * FROM user_buy_log_1; CREATE TABLE user_buy_log_2 AS
SELECT user,grp,time, period , row_num,CASE
WHEN period > 5 THEN 2
WHEN period is null THEN 1
ELSE NULL
END
AS res_grp
FROM user_buy_log_1; SELECT * FROM user_buy_log_2; CREATE TABLE user_buy_log_3 AS
SELECT user,grp,time,row_number() over (PARTITION BY grp ORDER BY time ASC) AS row_num
FROM user_buy_log_2
WHERE res_grp is not null; SELECT * FROM user_buy_log_3; CREATE TABLE user_buy_log_4 AS
SELECT t2.user,t2.grp,t2.time,t2.row_num,t3.row_num AS res_grp
FROM user_buy_log_2 t2
LEFT JOIN user_buy_log_3 t3
ON t2.user = t3.user; SELECT * FROM user_buy_log_4; CREATE TABLE user_buy_log_res AS
SELECT user,grp,time,
MAX(res_grp) over(PARTITION BY grp ORDER BY time ASC) AS res_grp
FROM user_buy_log_4; SELECT * FROM user_buy_log_res;
user_buy_log.txt
num15 B 2019-01-06 13:44:20.0
num17 B 2019-01-06 13:47:24.0
num10 A 2019-01-09 15:45:50.0
num18 B 2019-01-06 13:47:49.0
num16 B 2019-01-06 13:46:40.0
num3 A 2019-01-09 11:21:12.0
num4 A 2019-01-09 11:24:42.0
num1 A 2019-01-09 09:16:08.0
num12 B 2019-01-06 13:43:32.0
num13 B 2019-01-06 13:43:44.0
num2 A 2019-01-09 09:17:11.0
num7 A 2019-01-09 15:42:28.0
num11 A 2019-01-09 15:46:05.0
num5 A 2019-01-09 11:24:53.0
num9 A 2019-01-09 15:45:32.0
num8 A 2019-01-09 15:43:02.0
num6 A 2019-01-09 11:25:04.0
num14 B 2019-01-06 13:44:06.0
Hive SQL 分类的更多相关文章
- 【甘道夫】使用HIVE SQL实现推荐系统数据补全
需求 在推荐系统场景中,假设基础行为数据太少,或者过于稀疏,通过推荐算法计算得出的推荐结果非常可能达不到要求的数量. 比方,希望针对每一个item或user推荐20个item,可是通过计算仅仅得到8个 ...
- Hive sql函数
date: 2018-11-16 19:03:08 updated: 2018-11-16 19:03:08 Hive sql函数 一.关系运算 等值比较: = select 1 from dual ...
- 最强最全面的Hive SQL开发指南,超四万字全面解析
本文整体分为两部分,第一部分是简写,如果能看懂会用,就直接从此部分查,方便快捷,如果不是很理解此SQL的用法,则查看第二部分,是详细说明,当然第二部分语句也会更全一些! 第一部分: hive模糊搜索表 ...
- 【hive】——Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- Hive SQL 监控系统 - Hive Falcon
1.概述 在开发工作当中,提交 Hadoop 任务,任务的运行详情,这是我们所关心的,当业务并不复杂的时候,我们可以使用 Hadoop 提供的命令工具去管理 YARN 中的任务.在编写 Hive SQ ...
- hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- Hive sql 语法解读
一. 创建表 在官方的wiki里,example是这种: Sql代码 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name d ...
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
随机推荐
- typora快捷键
目录 基础信息 常用快捷键 修改快捷键 基础信息 typora是一款极佳的markdown写作软件,编辑和预览两者合二为一,免费良心软件,推荐使用. 官网:https://www.typora.io/ ...
- eclipse IDE使用git方法简单介绍
eclipse下使用git插件上传代码至github 1.eclipse下安装git eclipse git 插件的安装. 点击 Help->Install New Software-> ...
- 在搭建tesseract-OCR环境中遇到问题和反省
Tesseract,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎,特点是开源,免费,支持多语言,多平台. 在搭 ...
- VMware实现iptables NAT及端口映射
1. 前言 本文只讲解实战应用,不会涉及原理讲解.如果想要了解iptables的工作流程或原理可参考如下博文. 具体操作是在PC机的VMware虚拟机上进行的,因此涉及的地址都是内网IP.在实际工作中 ...
- 如何提高 windows 的使用效率?--巧用运行命令
windows 操作系统可以使用 win+R 运行一些命令执行任务,好处是:高效.快速.准确. 启动程序 将程序 chrome 写入以下注册表中, SOFTWARE\Microsoft\Windows ...
- 通过shell命令往android中写入配置
C:\Users>adb shell setprop "persist.sys.btylevel" 100 C:\Users>adb shell getprop &qu ...
- menu
<template> <el-row :gutter="10"> <div> <el-row :gutter="10" ...
- 跨域 - 自定义 jsonp实现跨域
问题:在现代浏览器中默认是不允许跨域. 办法:通过jsonp实现跨域 在js中,我们直接用XMLHttpRequest请求不同域上的数据时,是不可以的.但是,在页面上引入不同域上的js脚本文件却是 ...
- HBase2.0中的Benchmark工具 — PerformanceEvaluation
简介 在项目开发过程中,我们经常需要一些benchmark工具来对系统进行压测,以获得系统的性能参数,极限吞吐等等指标. 而在HBase中,就自带了一个benchmark工具—PerformanceE ...
- 获取与esp8266连接的客户端的Mac地址 IP 端口 控制停止等问题
两个关键的库 ESP8266WebServer.h WiFiClient.h ESP8266WiFiAP.cpp C:\Users\dongdong\Desktop\Arduino-master\li ...