数据规整化:pandas 求合并数据集(交集并集等)
数据集的合并或连接运算是通过一个或多个键将行链接起来的。这些运算是关系型数据库的核心。pandas的merge函数是对数据应用这些算法的这样切入点。
默认是交集, inner连接
列名不同可以分别指定:

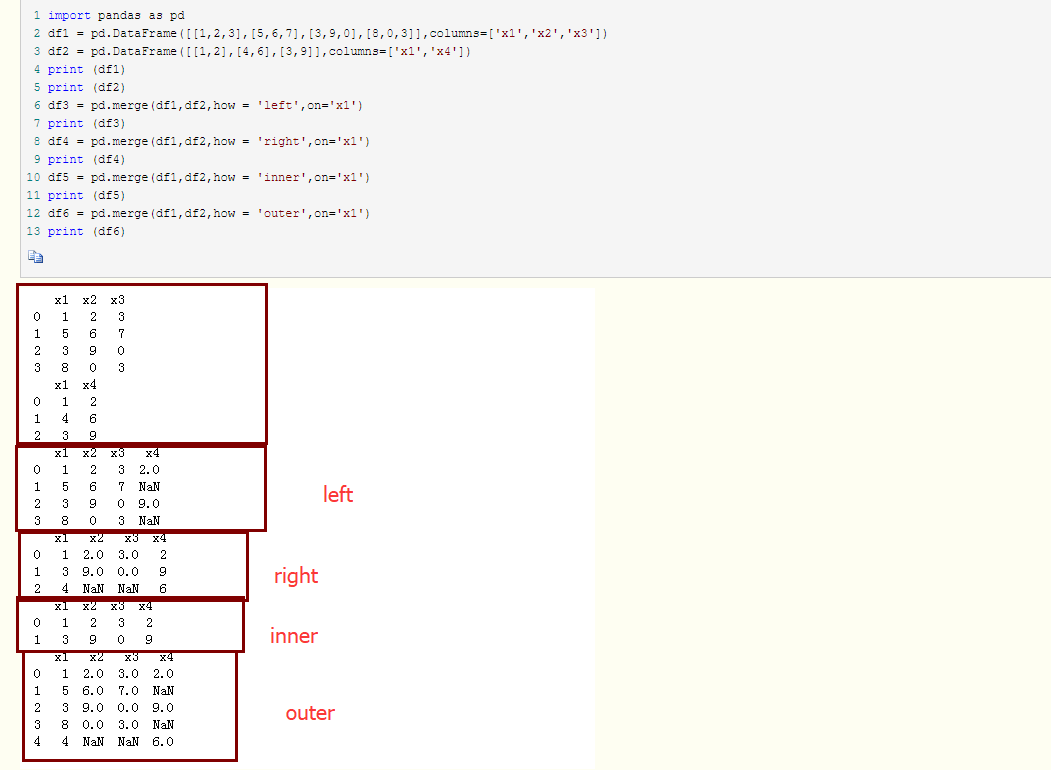
其他方式还要‘left’、‘right’以及“outer”。外链接求取的是键的并集, 组合了左连接和右连接的效果。

how 的作用是合并时候以谁为标准,是否保留NaN值
多对多

多对多 连接产生的行的笛卡尔积。由于左边的DataFrame有3个‘b’行, 右边的有2个,所以最终结果中
就有6个‘b’行。

根据多个键进行合并, 传入一个由列明组成的列表即可:
left = DataFrame(
{"key1": ['foo', 'foo', 'bar'],
"key2": ['one', 'two', 'one'],
"lval": [, , ]
}
)
right = DataFrame(
{"key1": ['foo', 'foo', 'bar', 'bar'],
"key2": ['one', 'one', 'one', 'two'],
"rval": [, , , ]
}
)
print(left)
print(right)
pm = pd.merge(left, right, on=["key1", "key2"], how="outer")
print(pm)


on与left_on 和right_on的区别

这个是left_on 和right_on

去重或更改后缀

merge函数的参数

索引上的合并

merge方法求取连接键的并集

对于层次化索引的数据
这个时候必须以列表的形式指明用作合并键的多个列(注意对重复索引的处理)
lefth = DataFrame({'key1':[ 'Ohio', 'Ohio', 'Ohio','Nevada', 'Nevada',],
"key2":[, , ,, ],
"data":np.arange(.)
})
righth = DataFrame(np.arange().reshape((, )),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[, , , , , ]],
columns=['event1', 'event2']
)
print(lefth)
print(righth)
pm = pd.merge(lefth, righth,left_on=['key1', 'key2'], right_index=True)
print(pm)

索引并集

DataFrame.join实例方法
它能更为方便地实现索引合并。它还可用于和合并多个带有相同或相似索引的DataFrame对象, 而不管他们
之间有重叠的列。

print(left1.join(right1, how='inner')) left2.join([1, 2], how='outer') #多个
数据规整化:pandas 求合并数据集(交集并集等)的更多相关文章
- Python之数据规整化:清理、转换、合并、重塑
Python之数据规整化:清理.转换.合并.重塑 1. 合并数据集 pandas.merge可根据一个或者多个不同DataFrame中的行连接起来. pandas.concat可以沿着一条轴将多个对象 ...
- 《python for data analysis》第七章,数据规整化
<利用Python进行数据分析>第七章的代码. # -*- coding:utf-8 -*-# <python for data analysis>第七章, 数据规整化 imp ...
- 【学习】数据规整化:清理、转换、合并、重塑【pandas】
这一部分非常关键! 数据分析和建模方面的大量编程工作都是用在数据准备上的:加载.清理.转换以及重塑. 1.合并数据集 pandas对象中的数据可以通过 一些内置的方式进行合并: pandas.merg ...
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
数据分析和建模方面的大量编程工作都是用在数据准备上的:载入.清理.转换以及重塑.有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求.很多人都选择使用通用编程语言(如Python.Per ...
- 利用Python进行数据分析-Pandas(第五部分-数据规整:聚合、合并和重塑)
在许多应用中,数据可能分散在许多文件或数据库中,存储的形式也不利于分析.本部分关注可以聚合.合并.重塑数据的方法. 1.层次化索引 层次化索引(hierarchical indexing)是panda ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- 利用python进行数据分析之数据规整化
数据分析和建模大部分时间都用在数据准备上,数据的准备过程包括:加载,清理,转换与重塑. 合并数据集 pandas对象中的数据可以通过一些内置方法来进行合并: pandas.merge可根据一个或多个键 ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 第三章 python数据规整化
本章概要 1.去重 2.缺失值处理 3.清洗字符型数据的空格 4.字段抽取 去重 把数据结构中,行相同的数据只保留一行 函数语法: drop_duplicates() #导入pandas包中的read ...
随机推荐
- oracle 负载均衡连接方式常用SQL语句备忘录
1.---表中有重复记录用SQL语句查询出来 select * from Recharge where RechargeSerial in (select RechargeSerial from Re ...
- [Windows Azure] Building worker role B (email sender) for the Windows Azure Email Service application - 5 of 5.
Building worker role B (email sender) for the Windows Azure Email Service application - 5 of 5. This ...
- ny24 素数距离的问题 筛选法求素数
素数距离问题时间限制:3000 ms | 内存限制:65535 KB难度:2 描述 现在给出你一些数,要求你写出一个程序,输出这些整数相邻最近的素数,并输出其相距长度.如果左右有等距离长度素 ...
- Swiper.js的腾讯新闻演示
演示效果地址:https://www.swiper.com.cn/demo/indexsample/: 代码: <!DOCTYPE html> <html> <head& ...
- 如何从dll文件导出对应的lib文件?
[时间:2016-05] [状态:Open] 引言 近期由于不再使用vs生成lib,考虑使用windows下gcc生成一个动态库,供第三方调用,发现编译之后只有dll,lib如何处理? 好吧,这就是本 ...
- 11g等待事件之library cache: mutex X
11g等待事件之library cache: mutex X 作者: dbafree 日期: 2012 年 07 月 01 日发表评论 (0)查看评论 library cache: mutex X ...
- JAVA-JSP内置对象之exception对象用来处理错误异常
相关资料:<21天学通Java Web开发> exception对象1.exception对象用来处理错误异常.2.如果要使用exception对象,必须指定page中的isErrorPa ...
- 最美应用API接口分析
最美应用API接口分析html, body {overflow-x: initial !important;}.CodeMirror { height: auto; } .CodeMirror-scr ...
- html页面布局总结篇
1. 使用float布局 注意点:使用浮动布局要注意清除浮动.使用伪类清除 浮动层:给元素的float属性赋值后,就是脱离文档流,进行左右浮动,紧贴着父元素(默认为body文本区域)的左右边框. 而此 ...
- USB入门
简述 USB(Universal Serial Bus)全称通用串口总线,USB为解决即插即用需求而诞生,支持热插拔.USB协议版本有USB1.0.USB1.1.USB2.0.USB3.1等,USB2 ...