利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完
学习目标:Page218-249,共32页;目标6天学完(按每页20min、每天1小时/每天3页,需10天)
实际反馈:实际XXX学完,耗时X天,X小时,平均每页X分钟。
实际应用中,数据可能分散在许多文件或数据库中,存储的形式也不利于分析。本章关注可以聚合、合并、重塑数据的方法。
8.1 层次化索引
层次化索引(hierarchical indexing)是pandas的一项重要功能,它使得能在一个轴上拥有多个(两个以上)索引级别。抽象点说,它使得能以低维度形式处理高维度数据。
看以下例子,创建一个Series并用一个由列表或数组组成的列表作为索引:
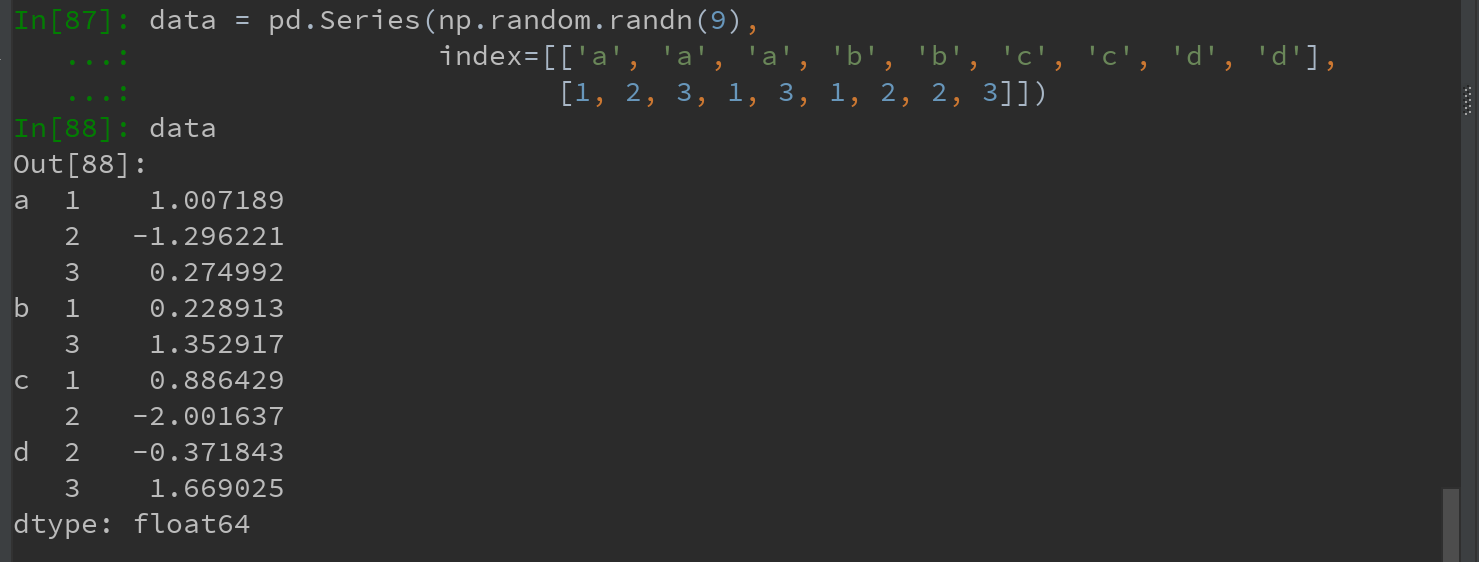
Ps:以上结果是经过美化的带有MultiIndex索引的Series的格式。

1)对于一个层次化索引的对象,可使用所谓的部分索引,使用它选取数据子集的操作更简单:
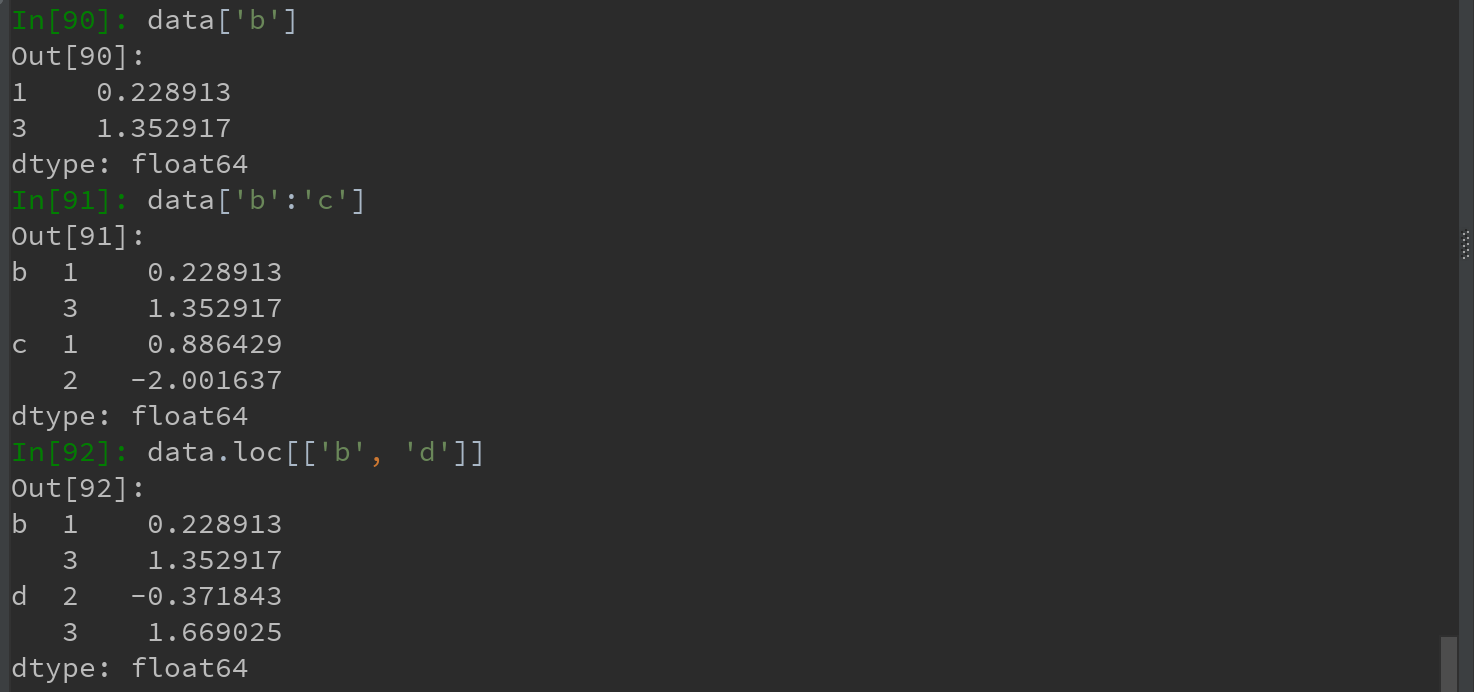
还可以在"内层"中进行选取:

2)层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要的角色。如,可通过unstack方法将这段数据重新安排到一个DataFrame中:

其中,unstack的逆运算时stack:

3)对于DataFrame,每条轴都可以有分层索引
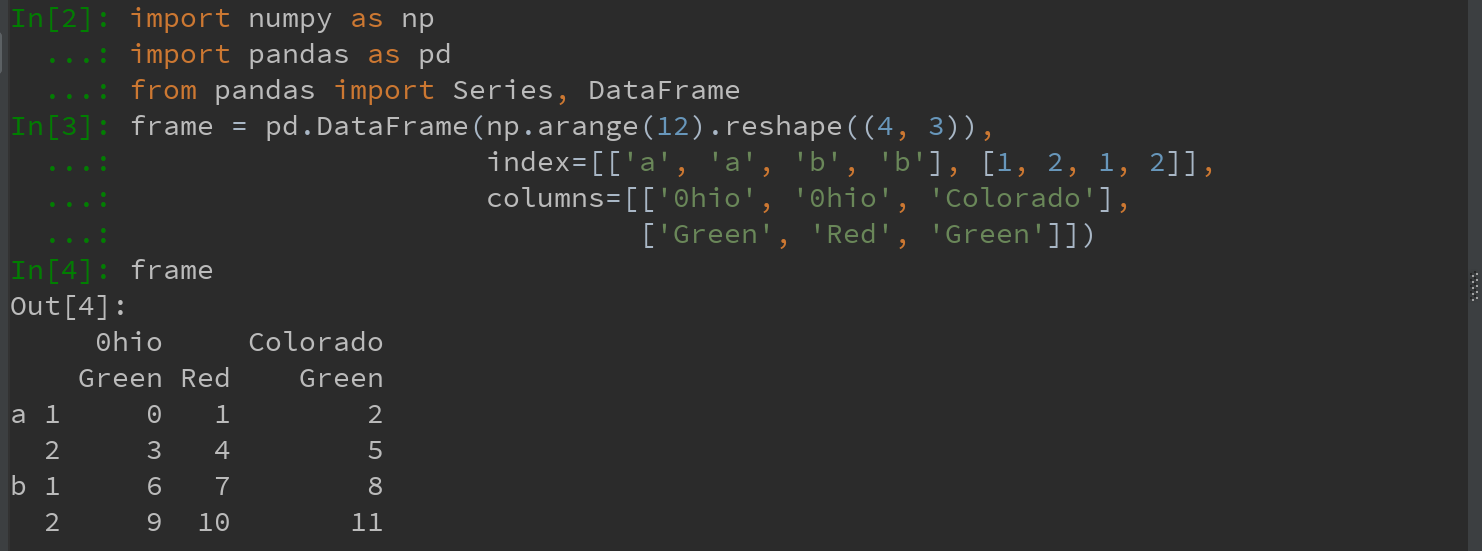
各层都可以有名字(可以是字符串,也可以是别的Python对象)。如果指定了名称,它们就会显示在控制台输出中:
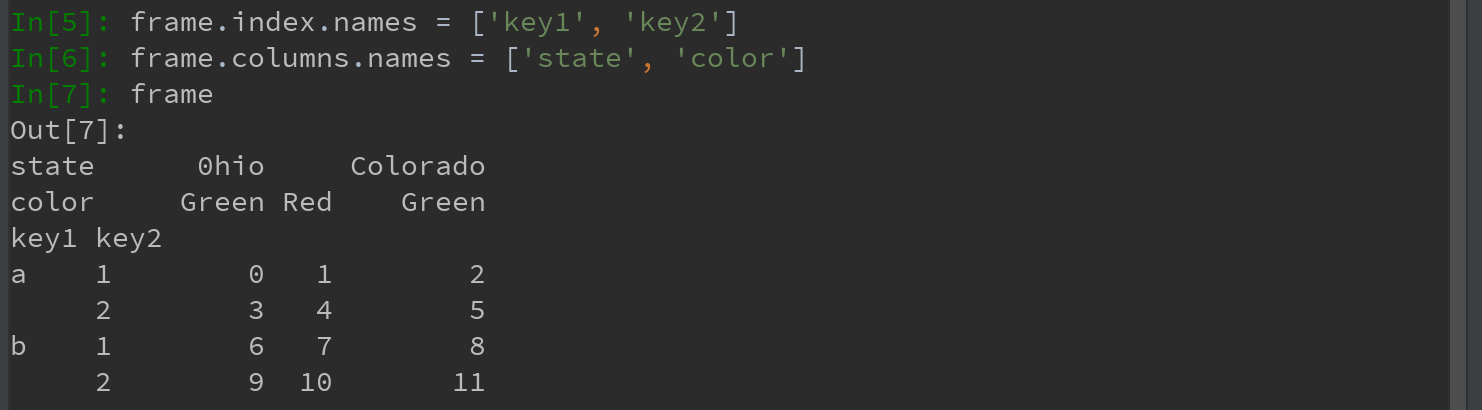
Ps:注意区分 索引名state、color与行标签
有了部分列索引,故可以轻松选取列分组:

8.1.1 重排与分级排序
1)swaplevel接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化)。比如,有时需要重新调整某条轴上各级别的顺序,或根据指定级别上的值对数进行排序。
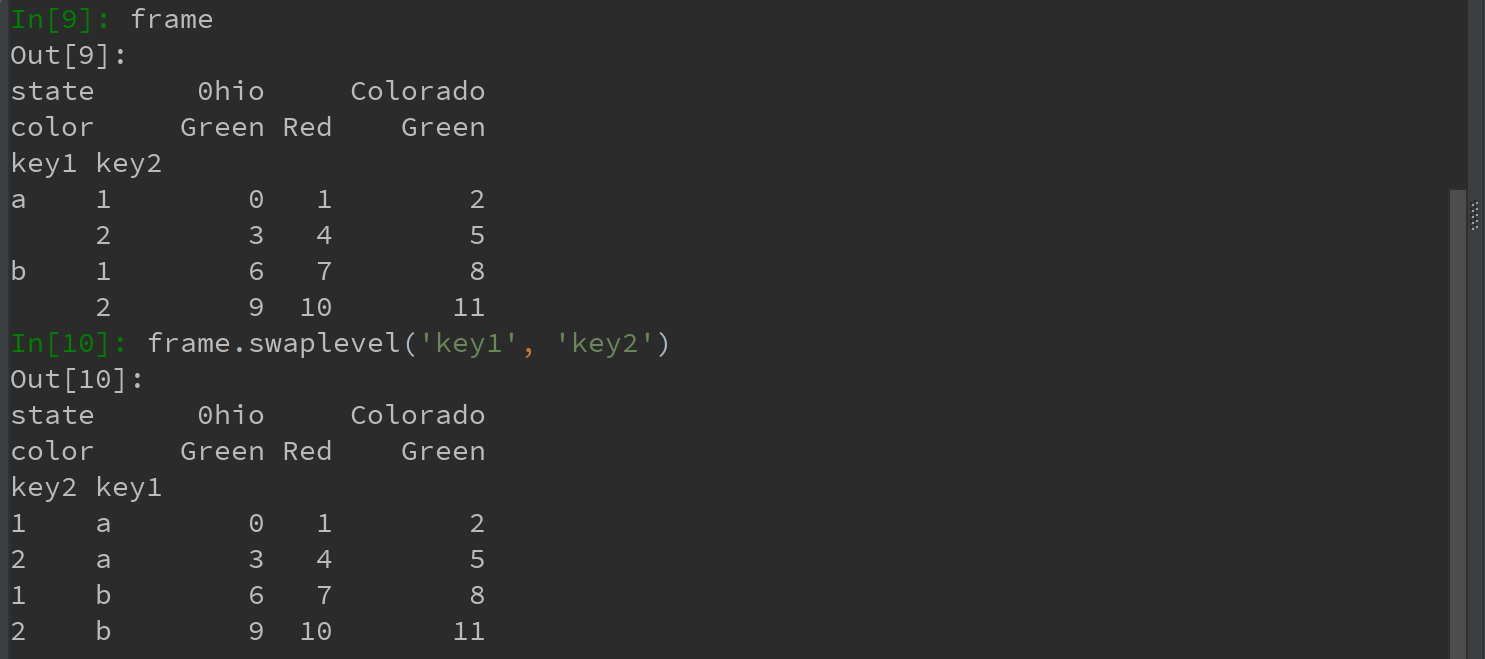
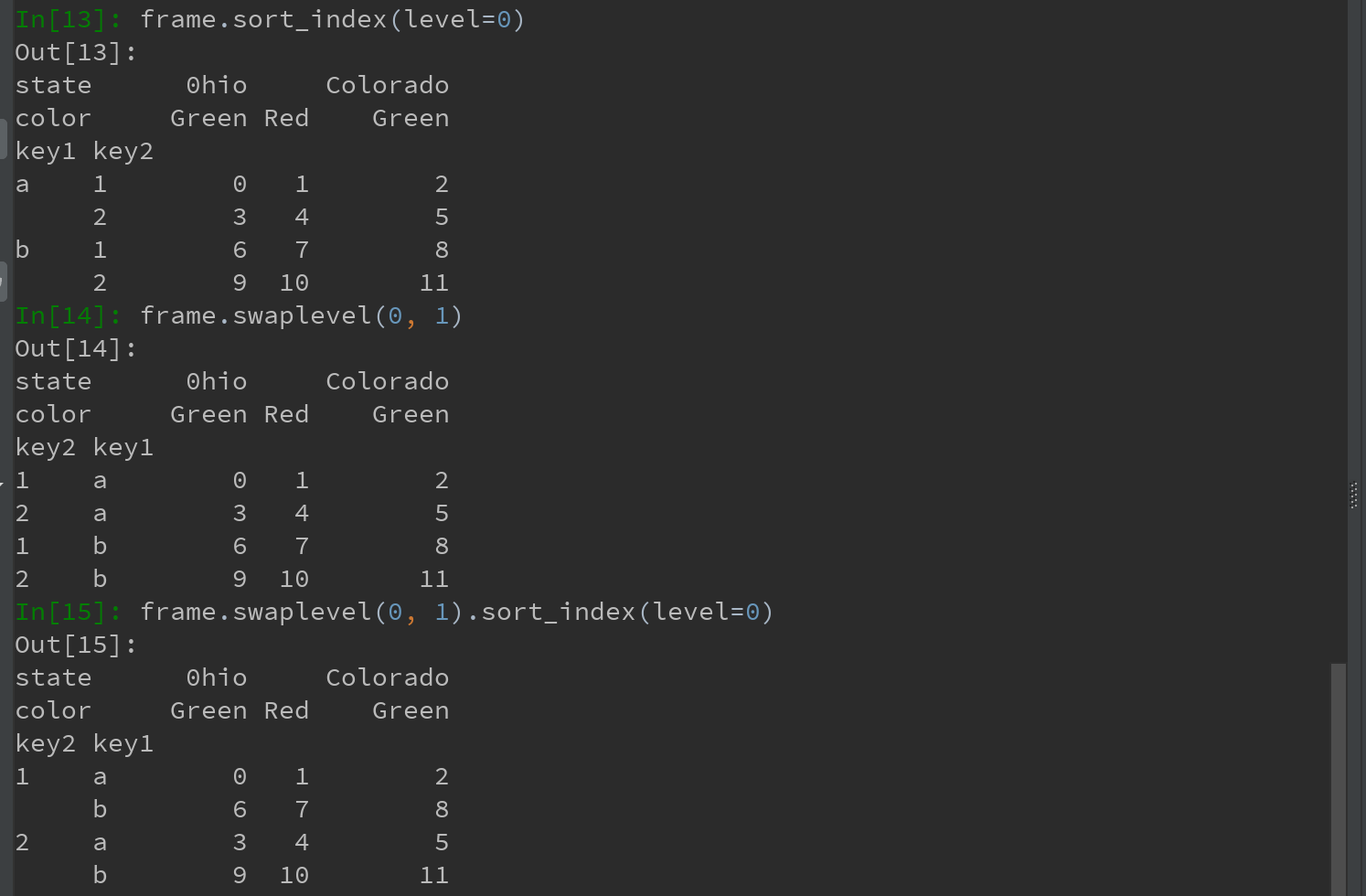
2)sort_index则根据单个级别中的值对数据进行排序。

Ps:交换级别时,也常会用到sort_index,这样最终结果就是按指定顺序进行字母排序了:
8.1.2 根据级别汇总统计
许多对DataFrame和Series的描述和汇总统计都有一个level选项,用于指定在某条轴上求和的级别。基于上面的DataFrame例子,根据行或列上的级别来分别进行求和:
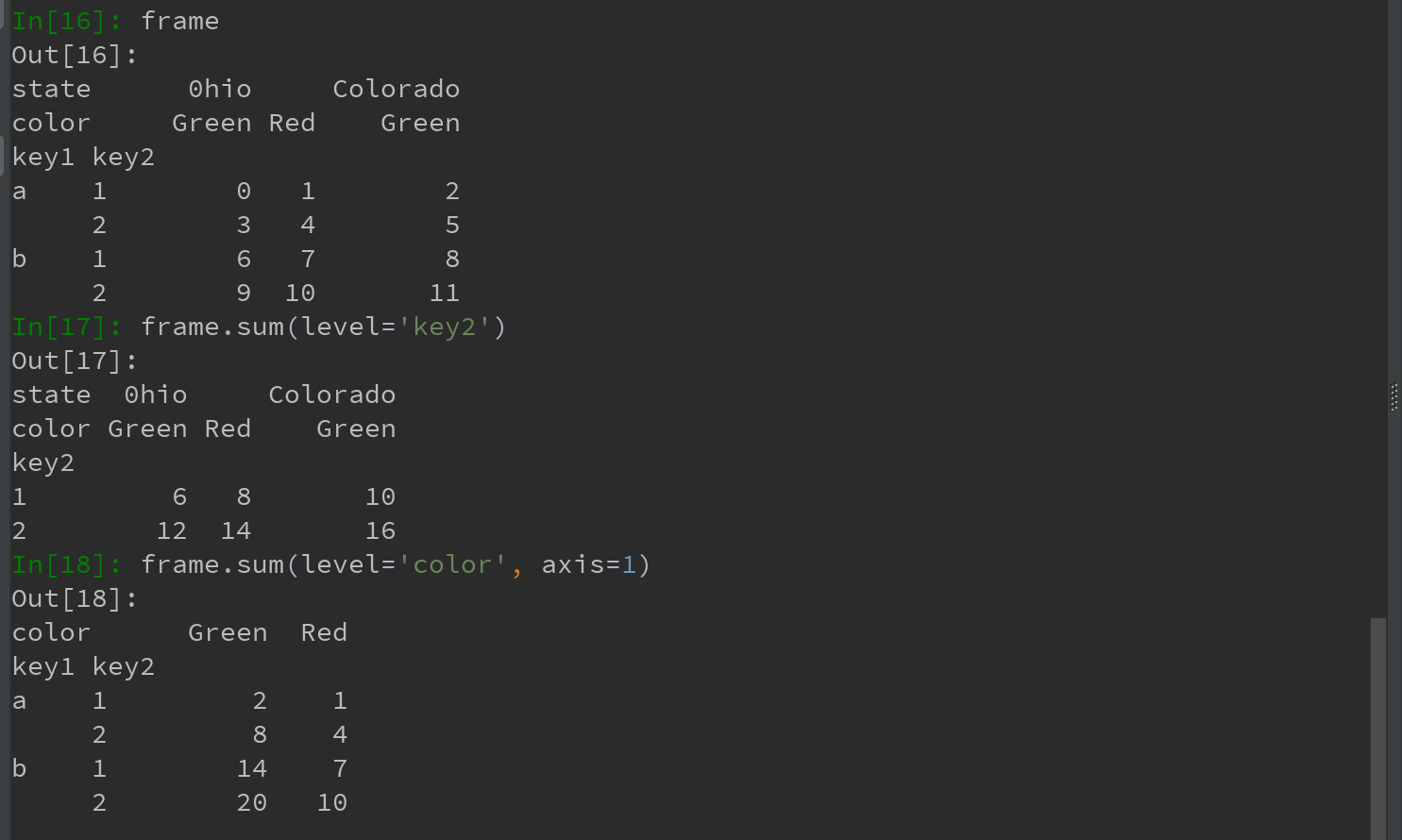
Ps:其实是利用pandas的groupby功能,后文详解
8.1.3 使用DataFrame的列进行索引
经常有需要将DataFrame的一个或多个列当作行索引用,或者可能希望将行索引变成DataFrame的列。
以下面的DataFrame为例:
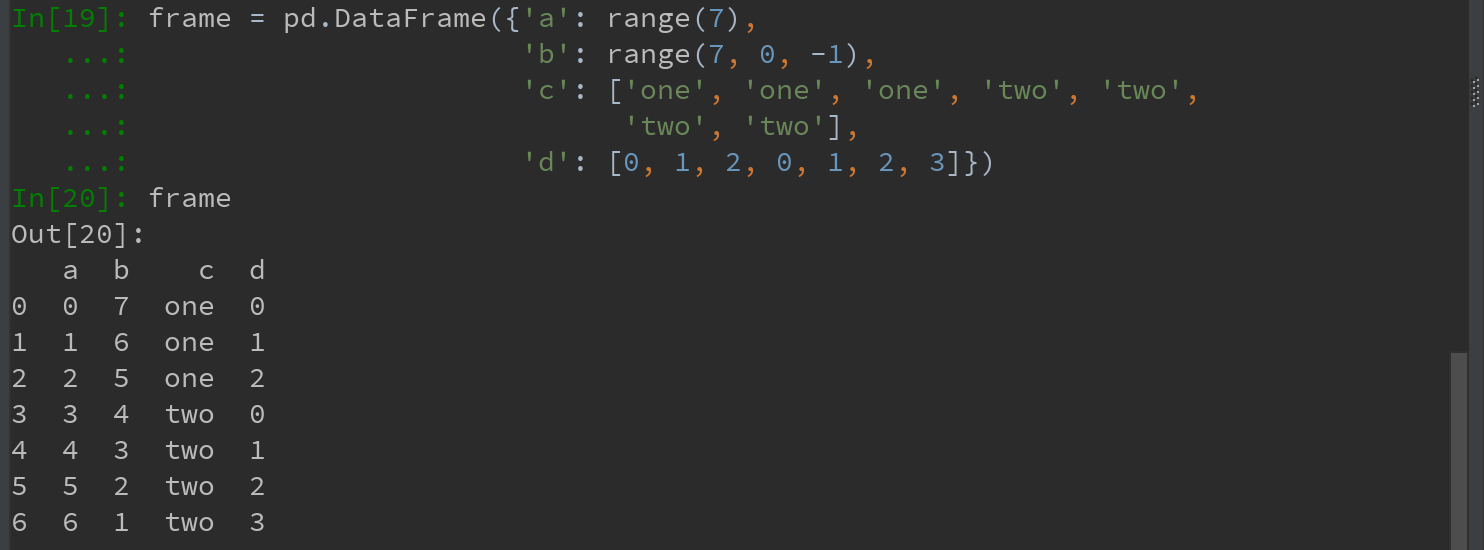
1)用DataFrame的set_index函数,可以将其一个或多个列转换为行索引,并创建一个新的DataFrame:

Ps:默认情况下,那些列会从DataFrame中移除,但也可以将其保留下来:

2)reset_index的功能跟set_index刚好相反,层次化索引的级别会被转移到列里面:

8.2 合并数据集
pandas对象中的数据可以通过一些方式进行合并:
- pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。SQL或其他关系型数据库的用户会对此较为数据,因为它实现的就是数据库的join操作。
- pandas.concat可以沿着一条轴将多个对象堆叠到一起。
- 实例方法combine_first可以将重复数据拼接在一起,用一个对象中的值填充另一个对象中的缺失值。
8.2.1 数据库风格的DataFrame合并
数据集的合并(merge)或连接(join)运算是通过一个或多个键将行连接起来的。这些运算时关系型数据库(基于SQL)的核心。pandas的merge函数是对数据应用这些算法的主要切入点。
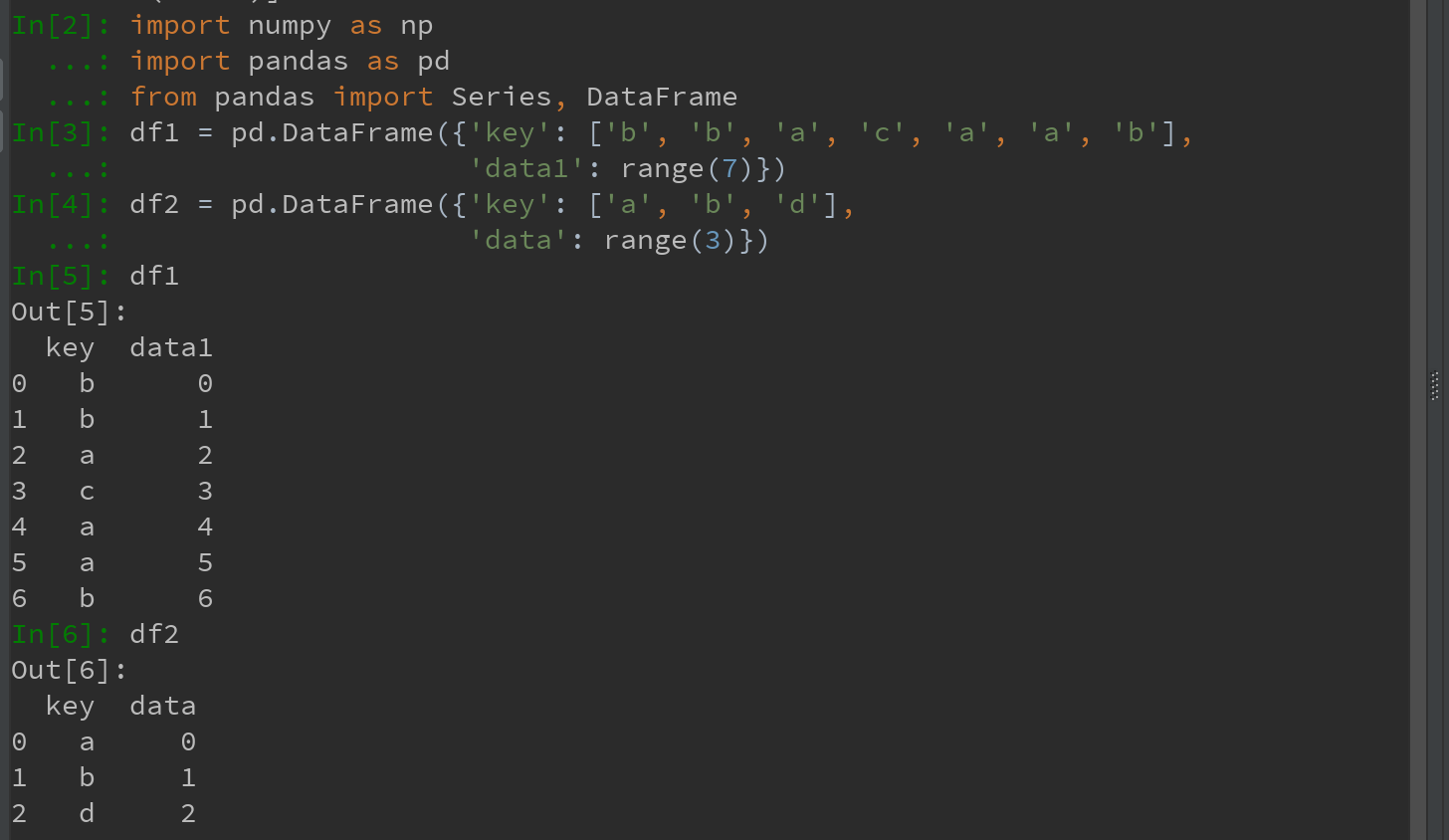
Ps:上图中例子是多对一的合并。df1中的数据有多个被标记为a和b的行,而df2中key列的每个值仅对应一行。
1)对df1和df2对象调用merge

Ps:此处并未指明用哪个列进行连接。若未指定,merge会自动将重叠列的列名当作键。
2)对df1和df2对象调用merge,同时指明进行连接的列

3)若两个对象的列名不同,则可以分别进行指定
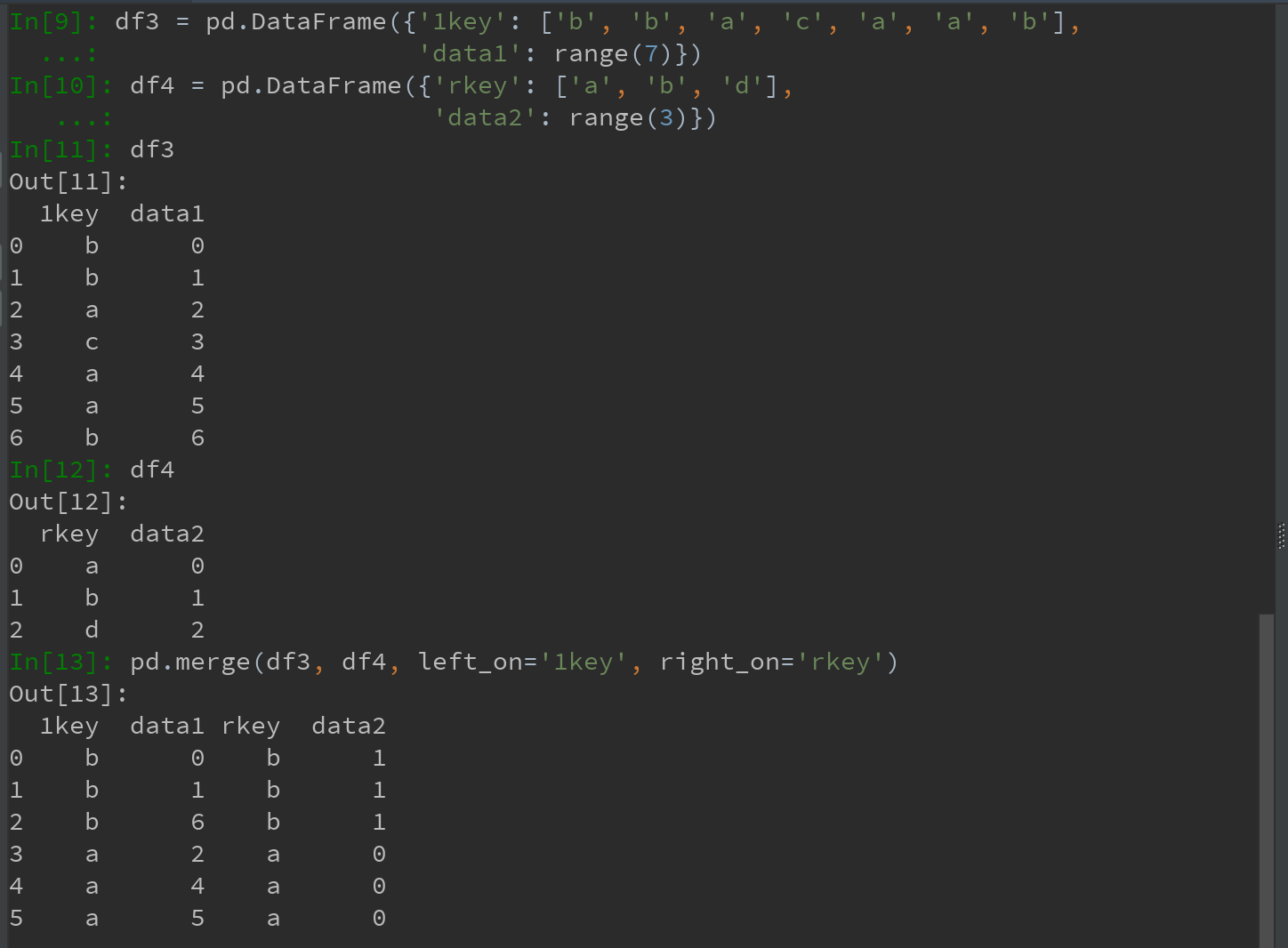
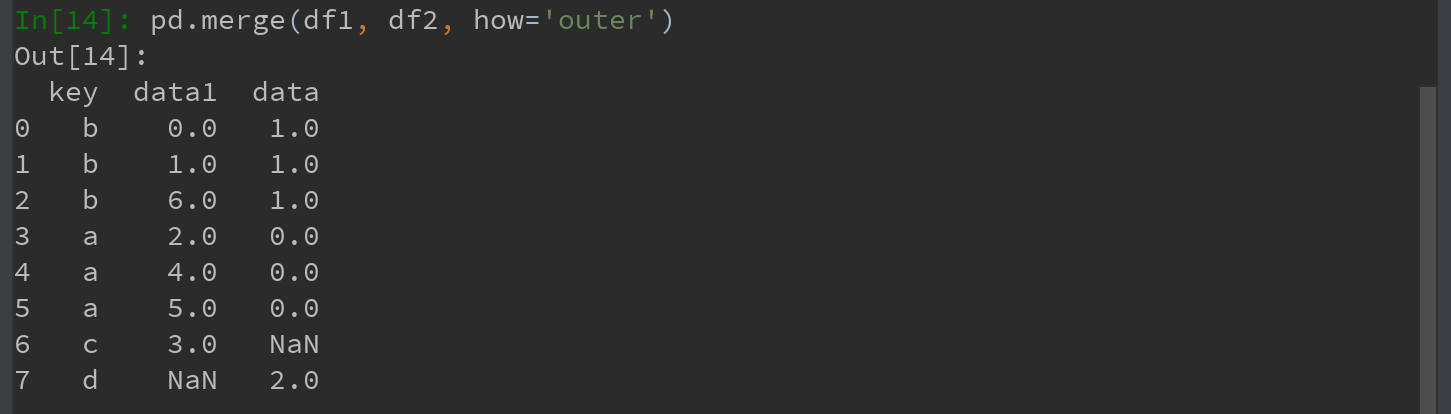
Ps:结果中无c和d以及与之相关的数据。默认情况下,merge做的是“内连接”-结果中的键是交集。外连接求取的是键的并集。如下图:

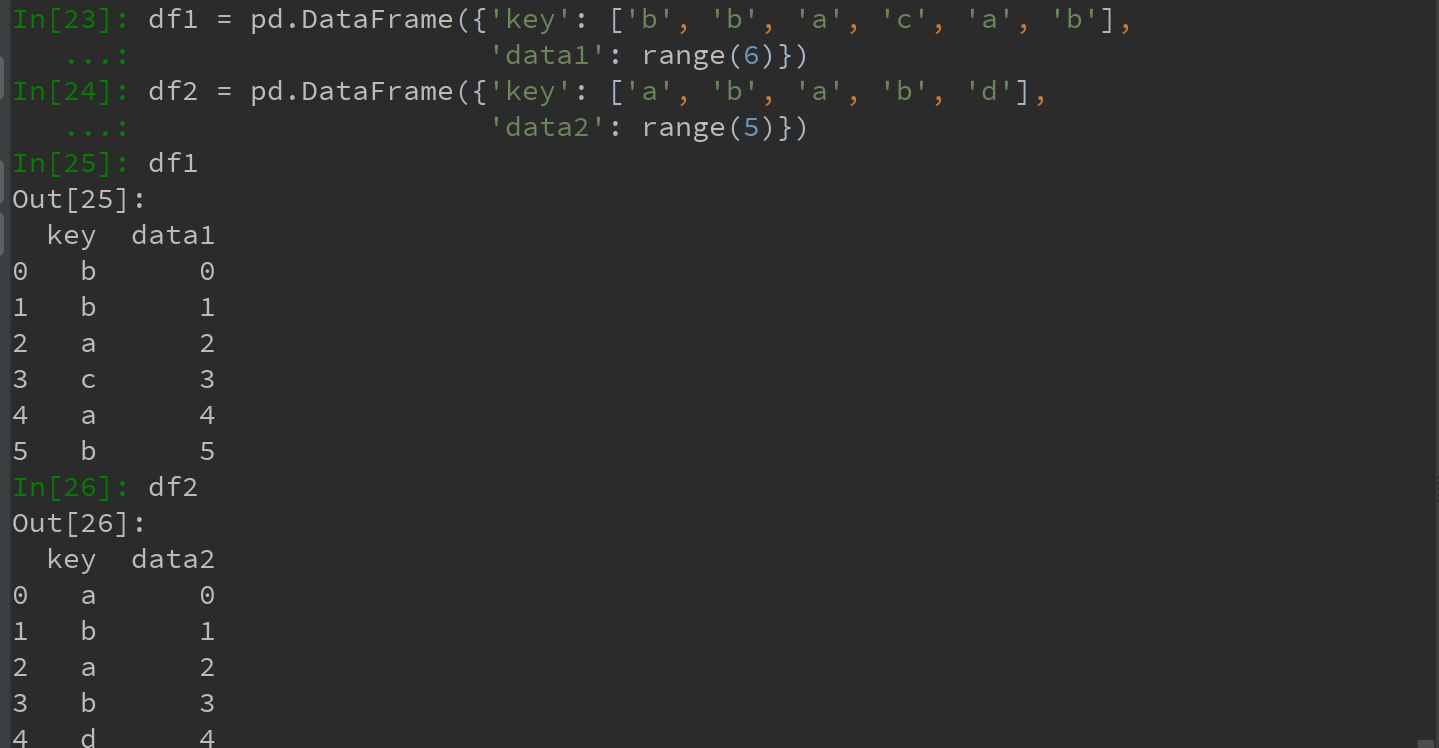
4)多对多的合并

8.2.2 索引上的合并
8.2.3 轴向连接
8.2.4 合并重叠数据
8.3 重塑和轴向旋转
8.3.1 重塑层次化索引
8.3.2 将"长格式"旋转为"宽格式"
8.3.3 将"宽格式"旋转为"长格式"
8.4 总结
至此,已经掌握了pandas数据导入、清洗、重塑,可进一步学习matplotlib数据可视化。稍后会回到pandas,学习更高级的分析。
利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md的更多相关文章
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 读取excel数据 import pandas as pd import ...
- 利用Python进行数据分析 第4章 IPython的安装与使用简述
本篇开始,结合前面所学的Python基础,开始进行实战学习.学习书目为<利用Python进行数据分析>韦斯-麦金尼 著. 之前跳过本书的前述基础部分(因为跟之前所学的<Python基 ...
- 利用Python进行数据分析 第7章 数据清洗和准备(2)
7.3 字符串操作 pandas加强了Python的字符串和文本处理功能,使得能够对整组数据应用字符串表达式和正则表达式,且能够处理烦人的缺失数据. 7.3.1 字符串对象方法 对于许多字符串处理和脚 ...
- 利用Python进行数据分析 第7章 数据清洗和准备(1)
学习时间:2019/10/25 周五晚上22点半开始. 学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完. 实际反馈:集中学习1.5小时,学习6页:集中学习 ...
- 利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数 通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数. 1)一元(unary)ufunc,如,sqrt和exp函数 2)二元(unary) ...
- 利用Python进行数据分析 第5章 pandas入门(2)
5.2 基本功能 (1)重新索引 - 方法reindex 方法reindex是pandas对象地一个重要方法,其作用是:创建一个新对象,它地数据符合新地索引. 如,对下面的Series数据按新索引进行 ...
- 利用Python进行数据分析 第5章 pandas入门(1)
pandas库,含有使数据清洗和分析工作变得更快更简单的数据结构和操作工具.pandas是基于NumPy数组构建. pandas常结合数值计算工具NumPy和SciPy.分析库statsmodels和 ...
随机推荐
- windows下使用xortools
xortool是一个多字节异或加密破解工具.作者只是适配了linux版,在Windows下使用会导致保存文件错误,因为Windows会把\n转成\r\n,加密和解密都乱了.而且命令还和readme不一 ...
- T-MAX-冲刺总结
T-MAX-冲刺总结 这个作业属于哪个课程 班级链接 这个作业要求在哪里 作业要求的链接 团队名称 T-MAX 这个作业的目标 冲刺总结 作业的正文 T-MAX-冲刺总结 其他参考文献 面向B站,百度 ...
- 深度学习面试题21:批量归一化(Batch Normalization,BN)
目录 BN的由来 BN的作用 BN的操作阶段 BN的操作流程 BN可以防止梯度消失吗 为什么归一化后还要放缩和平移 BN在GoogLeNet中的应用 参考资料 BN的由来 BN是由Google于201 ...
- html中a标签的常见用法
html中a标签的常见用法 一.总结 一句话总结: a.页面跳转 b.使用锚点定位 c.下载文件 二.html中<a>标签的用法 转自或参考:html中<a>标签的用法http ...
- Excel 如何自动调整列宽?
excel如何自动调整列宽 1.打开Excel表格,选中要调整的表格. 2.点击"格式",选择"自动调整列宽",右键点击"设置单元格格式" ...
- 011 client系列案例
一:Client系列 1.说明 clientWidth:不包括边框的可视区的宽 clientHeight:可视区的高,不包括边框 clientLeft:左边框的宽度 clientTop:上面框的宽度 ...
- MySQL TiDB PingCAP mydumper
MySQL备份之[mydumper 学习] - jyzhou - 博客园https://www.cnblogs.com/zhoujinyi/p/3423641.html maxbube/mydumpe ...
- Nessus更新到8.5.0
Nessus更新到8.5.0 此次更新,主要涉及以下变化: (1)Nessus的用户注册和激活流程进行简化.用户可以在Nessus软件中直接进行注册和激活. (2)Nessus报告生成功能得到加强 ...
- IDEA分配内存无效
idea改启动内存分配, 改 C:/Users/xxx/.IntelliJIdea2018.1/confing/idea64.exe.vmoptions 或 C:/Users/xxx/.Intelli ...
- python-learning-第二季-数据处理numpy
https://www.bjsxt.com/down/8468.html numpy-科学计算基础库 例子: import numpy as np #创建数组 a = np.arange() prin ...