hadoop rebalance
之前一直没做过rebalance,以为速度很快,结果大意了,等到磁盘达到90%的时候,才开始做rebalance。
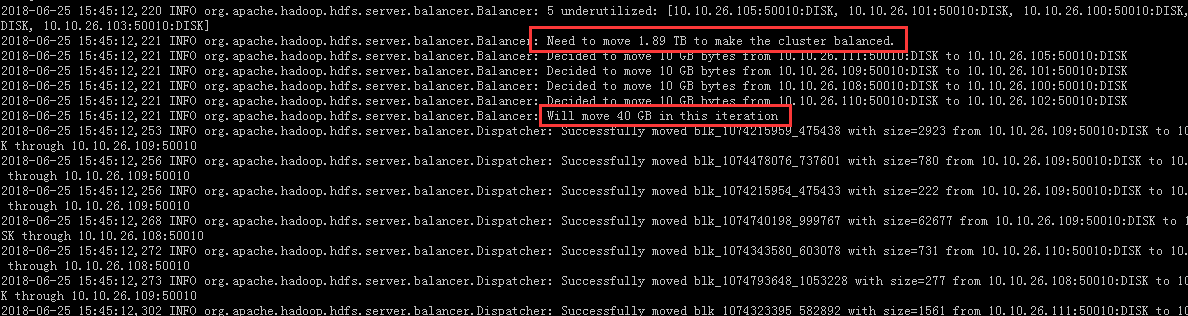
默认的从日志中可以看到总共需要迁移1.89T,但是每次只移动40G大小的量。
然后查看40G的数据量从15:45分到15:48分,所以结算结果为每分钟13G,每秒228M左右。(感觉这计算结果有问题)
hadoop有个balancerBandwidth可以通过设置带宽流量来增加数据移动的大小。
所以通过以下设置来增加每秒流量为500M.
hadoop dfsadmin -setBalancerBandwidth 524288000
start-balancer.sh -threshold 5
hadoop rebalance的更多相关文章
- 大数据组件原理总结-Hadoop、Hbase、Kafka、Zookeeper、Spark
Hadoop原理 分为HDFS与Yarn两个部分.HDFS有Namenode和Datanode两个部分.每个节点占用一个电脑.Datanode定时向Namenode发送心跳包,心跳包中包含Datano ...
- Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- 【转】HADOOP HDFS BALANCER介绍及经验总结
转自:http://www.aboutyun.com/thread-7354-1-1.html 集群平衡介绍 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加 ...
- 【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点.当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之 ...
- HBase rebalance 负载均衡源码角度解读使用姿势
关键词:hbase rebalance 负载均衡 参考源码版本:apache-hbase-1.1.2 什么是HBase Rebalance ? 随着数据写入越来越多以及不均衡,即使一开始每个Regio ...
- 【转载】Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- Hadoop生态圈-Kafka配置文件详解
Hadoop生态圈-Kafka配置文件详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.默认kafka配置文件内容([yinzhengjie@s101 ~]$ more /s ...
- hadoop kafka install (6)
reference: http://kafka.apache.org/quickstart http://dblab.xmu.edu.cn/blog/1096-2/ hadoop@iZuf68496 ...
- Kafka 0.8 Consumer Rebalance
1 Rebalance时机 0.10kafka的rebalance条件 条件1:有新的consumer加入 条件2:旧的consumer挂了 条件3:coordinator挂了,集群选举出新的coor ...
随机推荐
- Exception的妙用
实际工作中遇到的一个例子: 一.看这样一个方法: /** 传入以微秒(us)为单位的时间字符串,转换成可读的(年-月-日 时:分:秒)日期格式*/ public String getDateStrin ...
- 实现session(session数据)的共享,解决分布式session共享
为什么要实现共享? 首先我们应该明白,为什么要实现共享,如果你的网站是存放在一个机器上,那么是不存在这个问题的,因为会话数据就在这台机器,但是如果你使用了负载均衡把请求分发到不同的机器呢?这个时候会话 ...
- 关于 隐藏元素(样式为 display: none 的元素)及其子元素 获取不到高度的问题
IE 和 Edge 中都是这样,Chrome中好像还好. 方法就是换一个样式,还有一个控制显示隐藏的:visibility 相关文档:http://www.w3school.com.cn/cssref ...
- Atitit Loading 动画效果
Atitit Loading 动画效果 使用才场景,加载数据,以及显示警告灯.. 要有手动关闭按钮 <div class="spinner loading_part" sty ...
- 安装 xcode 5.1.1
https://developer.apple.com/downloads/ 切换路径xcode 路径.然并卵,不好用 http://cms.35g.tw/coding/xcode-select-%E ...
- 深入理解Linux内核-进程地址空间
给内核分配内存和给用户态进程分配内存是有区别的:1.内核的优先级最高,如果某个内核函数请求动态内存,不会被延时2.内核信任自己,不必保护措施3.用户态进程对动态内存的请求被认为不是紧迫的,总是被尽量推 ...
- 开发中遇到的一些mongoose的问题
save方法,这个方法可以用来创建新的文档,也可以用来修改已有文档 1,save创建新文档 var Tank = mongoose.model('Tank', yourSchema); 2 var s ...
- mongoose查询不到数据表中的数据的问题
在做分类管理的时候,在数据库中创建了一张category表,但使用下面这行代码始终查不到表里的数据,也没有任何报错. var Category = mongoose.model('Category', ...
- Erlang中一些错误或者异常的标识
erlang中错误大体分为四种: 1. 编译错误 2. 逻辑错误 3. 运行时错误 4. 用户代码生成的错误 编译错误,主要是编译器检测出的代码语法错误 逻辑错误,是指程序没有完成预 ...
- VirtualBox与VMWare网络冲突
VirtualBox安装一个XP后,发现老是上不到网,怎么折腾都不行, 后来发现设备管理器中 vmware accelerated amd pcnet adapter #2显示黄色感叹号 不对呀,这是 ...