Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行生产环境实现.
1. 原理
cost function

gradient descent
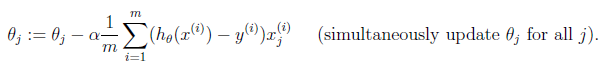
2. 原理实现
octave
cost function
function J = costFunction(X, Y, theta)
m = size(X, );
predictions = X * theta;
sqrErrors = (predictions - Y) .^ ;
J = / ( * m) * sum(sqrErrors);
Linear regression using gradient descent
function [final_theta, Js] = gradientDescent(X, Y, init_theta, learning_rate=0.01, max_times=)
convergence = ;
m = size(X, );
tmp_theta = init_theta;
Js = zeros(m, 1); for i=:max_times,
tmp = learning_rate / m * ((X * tmp_theta - Y)' * X)';
tmp_theta -= tmp;
Js(i) = costFunction(X, Y, tmp_theta);
end; final_theta = tmp_theta;
python
# -*- coding:utf8 -*-
import numpy as np
import matplotlib.pyplot as plt def cost_function(input_X, _y, theta):
"""
cost function
:param input_X: np.matrix input X
:param _y: np.array y
:param theta: np.matrix theta
:return: float
"""
rows, cols = input_X.shape
predictions = input_X * theta
sqrErrors = np.array(predictions - _y) ** 2
J = 1.0 / (2 * rows) * sqrErrors.sum() return J def gradient_descent(input_X, _y, theta, learning_rate=0.1,
iterate_times=3000):
"""
gradient descent
:param input_X: np.matrix input X
:param _y: np.array y
:param theta: np.matrix theta
:param learning_rate: float learning rate
:param iterate_times: int max iteration times
:return: tuple
"""
convergence = 0
rows, cols = input_X.shape
Js = [] for i in range(iterate_times):
errors = input_X * theta - _y
delta = 1.0 / rows * (errors.transpose() * input_X).transpose()
theta -= learning_rate * delta
Js.append(cost_function(input_X, _y, theta)) return theta, Js def generate_data():
"""
generate training data y = 2*x^2 + 4*x + 2
"""
x = np.linspace(0, 2, 50)
X = np.matrix([np.ones(50), x, x**2]).T
y = 2 * X[:, 0] - 4 * X[:, 1] + 2 * X[:, 2] + np.mat(np.random.randn(50)).T / 25
np.savetxt('linear_regression_using_gradient_descent.csv',
np.column_stack((X, y)), delimiter=',') def test():
"""
main
:return: None
"""
m = np.loadtxt('linear_regression_using_gradient_descent.csv', delimiter=',')
input_X, y = np.asmatrix(m[:, :-1]), np.asmatrix(m[:, -1]).T
# theta 的初始值必须是 float
theta = np.matrix([[0.0], [0.0], [0.0]])
final_theta, Js = gradient_descent(input_X, y, theta) t1, t2, t3 = np.array(final_theta).reshape(-1,).tolist()
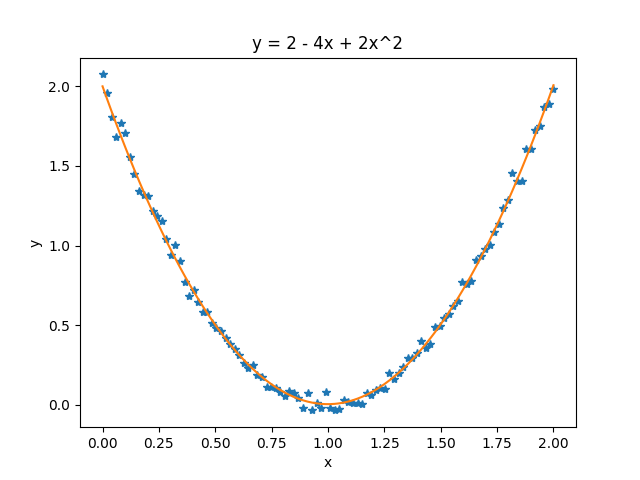
print('对测试数据 y = 2 - 4x + 2x^2 求得的参数为: %.3f, %.3f, %.3f\n' % (t1, t2, t3)) plt.figure('theta')
predictions = np.array(input_X * final_theta).reshape(-1,).tolist()
x1 = np.array(input_X[:, 1]).reshape(-1,).tolist()
y1 = np.array(y).reshape(-1,).tolist()
plt.plot(x1, y1, '*')
plt.plot(x1, predictions)
plt.xlabel('x')
plt.ylabel('y')
plt.title('y = 2 - 4x + 2x^2') plt.figure('cost')
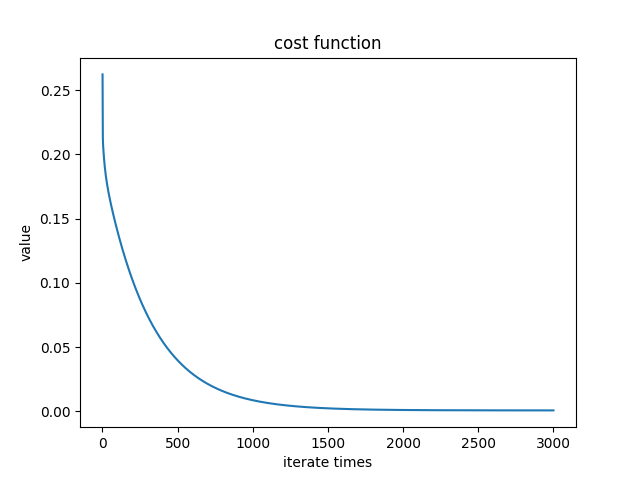
x2 = range(1, len(Js) + 1)
y2 = Js
plt.plot(x2, y2)
plt.xlabel('iterate times')
plt.ylabel('value')
plt.title('cost function') plt.show() if __name__ == '__main__':
test()
Python 中需要注意的是, numpy.array, numpy.matrix 和 list 等进行计算时, 有时会进行默认类型转换, 默认类型转换的结果, 往往不是期望的情况.
theta 的初始值必须是 float, 因为如果是 int, 则在更新 theta 时会报错.
测试数据:
Cost function:
c++
#include <iostream>
#include <vector>
#include <Eigen/Dense> using namespace Eigen;
using namespace std; double cost_function(MatrixXd &input_X, MatrixXd &_y, MatrixXd &theta) {
double rows = input_X.rows();
MatrixXd predictions = input_X * theta;
ArrayXd sqrErrors = (predictions - _y).array().square();
double J = 1.0 / ( * rows) * sqrErrors.sum(); return J;
} class Gradient_descent {
public:
Gradient_descent(MatrixXd &x, MatrixXd &y, MatrixXd &t,
double r=0.1, int m=): input_X(x), _y(y), theta(t),
learning_rate(r), iterate_times(m){}
MatrixXd theta;
vector<double> Js;
void run();
private:
MatrixXd input_X;
MatrixXd _y;
double rows;
double learning_rate;
int iterate_times;
}; void Gradient_descent::run() {
double rows = input_X.rows();
for(int i=; i < iterate_times; ++i) {
MatrixXd errors = input_X * theta - _y;
MatrixXd delta = 1.0 / rows * (errors.transpose() * input_X).transpose();
theta -= learning_rate * delta;
double J = cost_function(input_X, _y, theta);
Js.push_back(J);
}
} void generate_data(MatrixXd &input_X, MatrixXd &y) {
ArrayXd v = ArrayXd::LinSpaced(, , );
input_X.col() = VectorXd::Constant(, , );
input_X.col() = v.matrix();
input_X.col() = v.square().matrix();
y.col() = * input_X.col() - * input_X.col() + * input_X.col();
y.col() += VectorXd::Random() / ;
} int main() {
MatrixXd input_X(, ), y(, );
MatrixXd theta = MatrixXd::Zero(, );
generate_data(input_X, y);
Gradient_descent gd(input_X, y, theta);
gd.run();
cout << gd.theta << endl;
}
3. 生产环境
Python (Scikit-learn)
todo
Python (TensorFlow)
todo
C++ (dlib)
todo
Linear Regression Using Gradient Descent 代码实现的更多相关文章
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- Linear Regression and Gradient Descent
随着所学算法的增多,加之使用次数的增多,不时对之前所学的算法有新的理解.这篇博文是在2018年4月17日再次编辑,将之前的3篇博文合并为一篇. 1.Problem and Loss Function ...
- Linear Regression and Gradient Descent (English version)
1.Problem and Loss Function Linear Regression is a Supervised Learning Algorithm with input matrix ...
- Logistic Regression and Gradient Descent
Logistic Regression and Gradient Descent Logistic regression is an excellent tool to know for classi ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- flink 批量梯度下降算法线性回归参数求解(Linear Regression with BGD(batch gradient descent) )
1.线性回归 假设线性函数如下: 假设我们有10个样本x1,y1),(x2,y2).....(x10,y10),求解目标就是根据多个样本求解theta0和theta1的最优值. 什么样的θ最好的呢?最 ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
随机推荐
- python函数定义语法总结
见下面代码及注释: def calc(value): sum=0 for m in value: sum=sum+m return sum data=[1,2,3,4,5,6,7,8,9,10] pr ...
- sencha touch 2.3.1 list emptyText不显示
如图所示,有时候没有取到任何的数据. 那么我们就需要显示没有获取到内容这一类提示,显示内容通常通过emptyText这个属性来配置. 但是在sencha touch 2.3.1之中有可能会出问题,所以 ...
- Windows Server 2012设置WinDbg Kernel Debugging Local
网上主要提到了以下两点: 1.cmd窗口输入bcdedit /debug on,重新启动计算机. 2.下载对应版本Windows符号文件,并添加环境变量_NT_SYMBOL_PATH. 其实根据环境不 ...
- CentOS 6.4 php环境配置以及安装wordpress
1. nginx php-rpm 包升级 sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/i386/epel-release-6- ...
- jQuery:find()方法与children()方法的区别
1:children及find方法都用是用来获得element的子elements的,两者都不会返回 text node,就像大多数的jQuery方法一样. 2:children方法获得的仅仅是元素一 ...
- web自动化时,sendkeys输入长文本时浏览器响应慢或错误时处理
在做某个测试时,要在文本框中输入大量的文本,文件内容如下: "-----BEGIN CERTIFICATE-----\nMIIBozCCAQwCAQEwDQYJKoZIhvcNAQEFBQA ...
- intellij idea移动至方法块function()末尾的快捷键
intellij idea移动至方法块末尾的快捷键: 1. move caret to code block end ctrl+] 2. move caret to code block end wi ...
- iOS - 视频播放处理全屏/横屏时候遇见的坑
视频播放想要全屏,使用shouldAutorotate方法禁止主界面,tabbar控制器横屏,导致push进入播放页面不能横屏的问题... - (BOOL)shouldAutorotate { ret ...
- windows下java开发资料汇总
开发环境搭建: (1) java开发环境配置 (2) maven环境快速搭建 项目部署: (1) Eclipse中项目部署方法 (2) 使用Eclipse构建Maven ...
- Redis学习资料整理
Redis学习资料: (1)Redis设计与实现 (2)十五分钟介绍 Redis数据结构 (3)redis安装 (4)redis指令手册中文版 Hiredis学习资料: (1)hiredis安装及测试 ...