ElasticSearch:华为云搜索CSS 之POC操作记录
2019/03/06 09:00
ES文档官方:https://support.huaweicloud.com/usermanual-es/es_01_0024.html
华为云区域:华北北京1
ES集群控制台:地址:
ECS控制台:地址:
ps:操作环境:华为云服务器上命令操作,使用bulk API通过cURL命令导入数据文件,以JSON数据文件为例。
华为云ES集群内网ip:xx.xx.xx.xx:9200
★查询索引
curl 'http://xx.xx.xx.xx:9200/_cat/indices'
查询索引下的数据
curl -XGET 'http://xx.xx.xx.xx:9200/poc_index/_search?pretty'
删除索引
curl -XDELETE 'http://xx.xx.xx.xx:9200/ddddd_index'
查询某一个索引库中的数据
查询整个索引库:curl -XGET http://master:9200/bigdata_p/_search?pretty
在url后面加上一个pretty则会对返回结果进行格式化,
查询某一个type:curl -XGET http://master:9200/bigdata_p/product/_search?pretty
查询具体的一条记录:curl -XGET http://master:9200/bigdata_p/product/1?pretty
查询一条索引文档中的具体的字段:curl -XGET http://master:9200/bigdata_p/product/1?_source=name&pretty
如果要查询多个字段,使用","进行隔开。eg.
curl -XGET http://master:9200/bigdata_p/product/1?_source=name,author&pretty
获取source所有数据
curl -XGET http://master:9200/bigdata_p/product/1?_source&pretty
根据条件进行查询
curl -XGET http://master:9200/bigdata_p/product/_search?q=name:hbase,hive&pretty
删除索引下的数据
POST /poc_index/_delete_by_query
{
"query": {
"match_all": {
}
}
}
★创建索引:
curl -X PUT http://xx.xx.xx.xx:9200/my_store -d '
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"products": {
"properties": {
"productName": {
"type": "text"
},
"size": {
"type": "keyword"
}
}
}
}
}' -H 'Content-Type: application/json'
ps: 添加 -H 'Content-Type: application/json' ,否则报错不支持json格式。
★本地创建test.json文件。添加内容:
{"index": {"_index":"my_store","_type":"products"}} {"productName": "2019秋装新款文艺衬衫女装","size": "M"}
-------------------------------------------------------------------------------------
ps:一定要记得在数据最后,添加换行,否则导入数据报错。!!!
需要注意的是{"index":{"_id":"1"}}和文件末尾另起一行换行是不可少的
参见文章:https://www.cnblogs.com/tonglin0325/p/8446975.html
★上传test.json文件到服务器,路径下执行命令导入数据。使用time命令打印命令的执行过程消耗的时间:
命令:
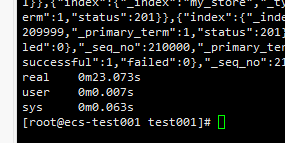
time curl -X PUT "http://xx.xx.xx.xx:9200/_bulk" -H 'Content-Type: application/json' --data-binary @test.json
以下为测试不同数量的数据导入结果:
1条:0.012s

1万条:3.013s

6万条:23.073s
=======================================================
使用springboot整合ES进行数据插入demo:
新建springboot项目:yml配置:
spring: #elasticsearch配置 data: elasticsearch: cluster-name: Es-23b6 cluster-nodes: 192.168.0.166:9300 repositories: enabled: true
ps:华为云ES控制台可以看到cluster-name和cluster-nodes,注意端口一定要改为9300,因为是集群的原因。否则异常:
org.elasticsearch.client.transport.NoNodeAvailableException: None of the configured nodes are available: [{#transport#-1}{S428skP0SrqzcOn8W7vhHg}{192.168.0.166}{192.168.0.166:9200}] at org.elasticsearch.client.transport.TransportClientNodesService.ensureNodesAreAvailable(TransportClientNodesService.java:349) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.elasticsearch.client.transport.TransportClientNodesService.execute(TransportClientNodesService.java:247) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.elasticsearch.client.transport.TransportProxyClient.execute(TransportProxyClient.java:60) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.elasticsearch.client.transport.TransportClient.doExecute(TransportClient.java:381) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.elasticsearch.client.support.AbstractClient.execute(AbstractClient.java:407) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.elasticsearch.client.support.AbstractClient.execute(AbstractClient.java:396) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.elasticsearch.action.ActionRequestBuilder.execute(ActionRequestBuilder.java:46) ~[elasticsearch-6.4.3.jar!/:6.4.3] at org.springframework.data.elasticsearch.core.ElasticsearchTemplate.index(ElasticsearchTemplate.java:577) ~[spring-data-elasticsearch-3.1.5.RELEASE.jar!/:3.1.5.RELEASE] at org.springframework.data.elasticsearch.repository.support.AbstractElasticsearchRepository.save(AbstractElasticsearchRepository.java:156) ~[spring
参见文章:https://blog.csdn.net/adsl624153/article/details/78935796
pom中引入依赖:
<!-- elasticsearch --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch </artifactId> <version>2.0.2.RELEASE</version> </dependency>
先对ES创建索引:【linux命令行执行】
创建索引
curl -X PUT http://192.168.0.166:9200/my_store -d '
{
"settings": {
"number_of_shards": 1
},
"mappings": {
"products": {
"properties": {
"id": {
"type": "long"
},
"productName": {
"type": "text"
},
"size": {
"type": "keyword"
}
}
}
}
}' -H 'Content-Type: application/json'
创建实体类:
package com.huawei.Bean;
import org.springframework.data.elasticsearch.annotations.Document;
import com.fasterxml.jackson.annotation.JsonProperty;
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor;
/**
* * @author :ayfei
* @createTime :2019年3月5日下午2:13:31
* @description : */
@Data
@AllArgsConstructor
@NoArgsConstructor //indexName代表索引 名 称 ,type代表表名称
@Document(indexName = "my_store", type = "products")
public class Notice {
//id
@JsonProperty("id")
private Long id; //
@JsonProperty("productName")
private String productName;
@JsonProperty("size")
private String size;
}
创建Dao层接口:
package com.huawei.Dao;
/**
* * @author :ayfei
* @createTime :2019年3月5日下午2:15:26
* @description :
*/
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Component;
import com.huawei.Bean.Notice;
@Component public interface NoticeDao extends ElasticsearchRepository<Notice, Long> {
}
controller层部分代码,直接调用ES的相关API:
@RequestMapping(value = "/saveOne", method = RequestMethod.POST)
public String saveOne(@RequestBody @Valid Notice article){
long start = System.currentTimeMillis();
log.info("=====start System.currentTimeMillis()====="+start);
noticeDao.save(article);
long end = System.currentTimeMillis();
log.info("=====end System.currentTimeMillis()====="+end);
long timeRes = end-start;
log.info("存储一条数据到ES的执行时间"+ timeRes + "ms");
stringRedisTemplate.opsForValue().set("timeOneToES", timeRes+"ms");
return "存储一条数据到ES的执行时间"+ timeRes + "ms";
}
ElasticSearch:华为云搜索CSS 之POC操作记录的更多相关文章
- 华为云kafka POC 踩坑记录
2019/03/08 18:29 最近在进行华为云相关POC验证,个人主要负责华为云DMS kafka相关.大致数据流程是,从DIS取出数据,进行解析处理,然后放入kafka,再从kafka中取出数据 ...
- 大型情感剧集Selenium:6_selenium中的免密登陆与cookie操作 #华为云·寻找黑马程序员#
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),输入关键字"加群",加入华为云线上技术讨论群:输入关键字"最新活动",获取华 ...
- 华为云提供针对Nuget包管理器的缓存加速服务
在Visual Studio 2013.2015.2017中,使用的是Nuget包管理器对第三方组件进行管理升级的.而且 Nuget 是我们使用.NET Core的一项基础设施,.NET的软件包管理器 ...
- 云搜索服务在APP搜索场景的应用
搜索无处不在,尤其是在移动互联的今天.无论是社交,电商,还是视频等APP中,搜索都已经在其中扮演了重要的角色.作为信息的入口,搜索能帮用户从海量信息中找到想要的信息.在APP搜索的典型场景如下: ● ...
- CentOS 7.4 下搭建 Elasticsearch 6.3 搜索群集
上个月 13 号,Elasticsearch 6.3 如约而至,该版本和以往版本相比,新增了很多新功能,其中最令人瞩目的莫过于集成了 X-Pack 模块.而在最新的 X-Pack 中 Elastics ...
- 这个七夕节,用Python为女友绘制一张爱心照片墙吧!【华为云技术分享】
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),输入关键字“加群”,加入华为云线上技术讨论群:输入关键字“最新活动”,获取华为云最新特惠促销.华为云诸多技术大咖.特 ...
- 华为云·寻找黑马程序员#海量数据的分页怎么破?【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- 使用Python开发小说下载器,不再为下载小说而发愁 #华为云·寻找黑马程序员#
需求分析 免费的小说网比较多,我看的比较多的是笔趣阁.这个网站基本收费的章节刚更新,它就能同步更新,简直不要太叼.既然要批量下载小说,肯定要分析这个网站了- 在搜索栏输入地址后,发送post请求获取数 ...
- 爬虫新宠requests_html 带你甄别2019虚假大学 #华为云·寻找黑马程序员#
python模块学习建议 学习python模块,给大家个我自己不专业的建议: 养成习惯,遇到一个模块,先去github上看看开发者们关于它的说明,而不是直接百度看别人写了什么东西.也许后者可以让你很快 ...
随机推荐
- VMware里Ubuntu-16.04-desktop的VMware Tools安装图文详解
不多说,直接上干货! 总的来说,根据分为三个步骤. 步骤一: 点击 :虚拟机—–>安装VM tools 然后发现桌面会跳出如下问题: 客户机操作系统已将 CD-ROM 门锁定,并且可能正在使用 ...
- Java视频播放器的制作
----------------siwuxie095 使用 Java Swing 框架制作一个简单的视频播放器: 首先到 Vid ...
- RStudio 断点调试 进入for循环语句调试
参考: http://www.rstudio.com/ide/docs/debugging/overview 1.进入调试模式 全选代码,点击source即可进入调试模式. 2.进入for 调试 在F ...
- 解决因为终端打印造成的java程序假死
问题状态: java 程序 日志采用 log4j 运行时由另一个管理进程拉起,程序在后台运行. 现象: 程序后台运行时,运行一段时间后假死 分析原因: 尝试打印输出,定位假死的具体位置,发现出现假死的 ...
- 19.Imagetragick 命令执行漏洞(CVE-2016–3714)
Imagetragick 命令执行漏洞(CVE-2016–3714) 漏洞简介: Imagetragick 命令执行漏洞在16年爆出来以后,wooyun上面也爆出了数个被该漏洞影响的大厂商,像腾讯, ...
- idea中,使用facets添加完web后,项目已变为web项目,但web.xml中内容经常变为红色,并报错,如何解决?
这中错误经常是由于配置facets并添加完web后,没有进一步配置web.xml文件,导致web.xml是使用系统默认的. 如图:需要进一步配置web.xml文件,使用我们src/main/webap ...
- IIS中使用子目录文件作为默认文档(Default Document)替代重定向
以前一直以为IIS应用程序的默认文档只能设置根目录下的文件,像index.html,default.aspx等,后来经同事指点,原来子目录或者子应用程序下的文件也可以添加到根应用程序的默认文档列表中. ...
- ALSA声音编程
1. ALSA设备驱动将ALSA设备描述分为四层,从上到下为: default default:0 plughw:0,0 hw:0,0 不同的层次,对设备的控制权限不同,比如hardware para ...
- Jmeter-返回值乱码处理
Jmeter安装目录/bin/jmeter.properties中sampleresult.default.encoding默认为ISO-8859-1,将参数修改为 sampleresult.defa ...
- I/O重定向和管道
一:I/O设备 I/O(Input/Output),即输入/输出,通常指数据在内部存储器和外部存储器或其他周边设备之间的输入和输出. 标准输入(STDIN):0 默认接受来自键盘的输入 标准输出(ST ...