墨天轮国产数据库沙龙 | 张晓庆:GoldenDB分布式数据库的自动安装与备份恢复
在共同推进国产化生态发展的进程下,墨天轮正式推出“墨天轮国产数据库沙龙”系列直播活动,将定期邀请各国产数据库产品专家、掌门人,共同探讨如何达成技术“自主可控”的使命。
本文为中兴通讯GoldenDB资深DBA——张晓庆在“墨天轮国产数据库沙龙”中分享的内容整理而成。重点讲解GoldenDB分布式数据库的自动安装与备份恢复。
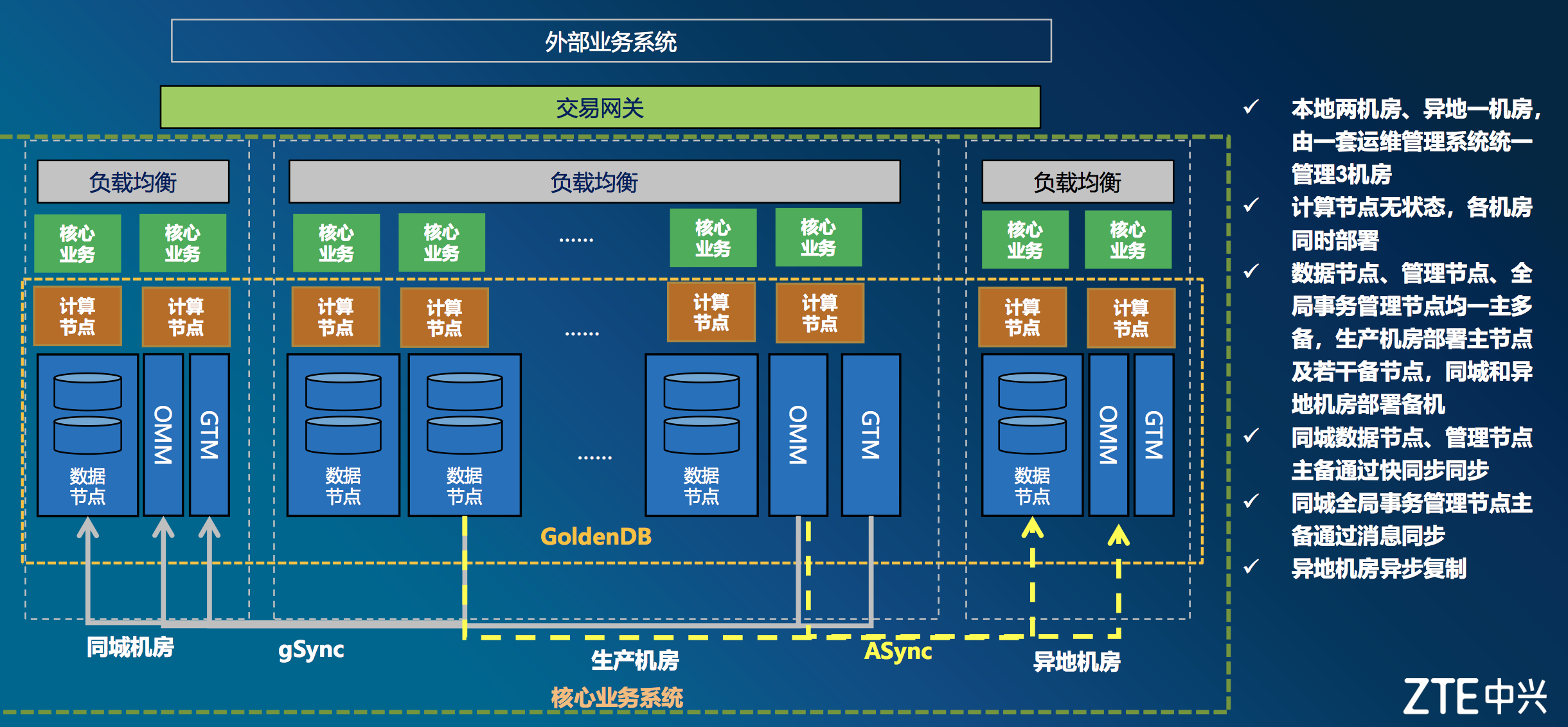 图为GoldenDB 两地三中心典型部署图
图为GoldenDB 两地三中心典型部署图
GoldenDB 一键部署
在部署中,仅需要三个步骤:安装前准备、编辑安装配置文件、运行安装程序即可实现一键部署。  图为GoldenDB一键部署步骤
图为GoldenDB一键部署步骤
GoldenDB 备份恢复
全局一致的备份恢复
分布式数据库恢复到全局一致的数据才是可用的。下图为备份恢复的基本框架。
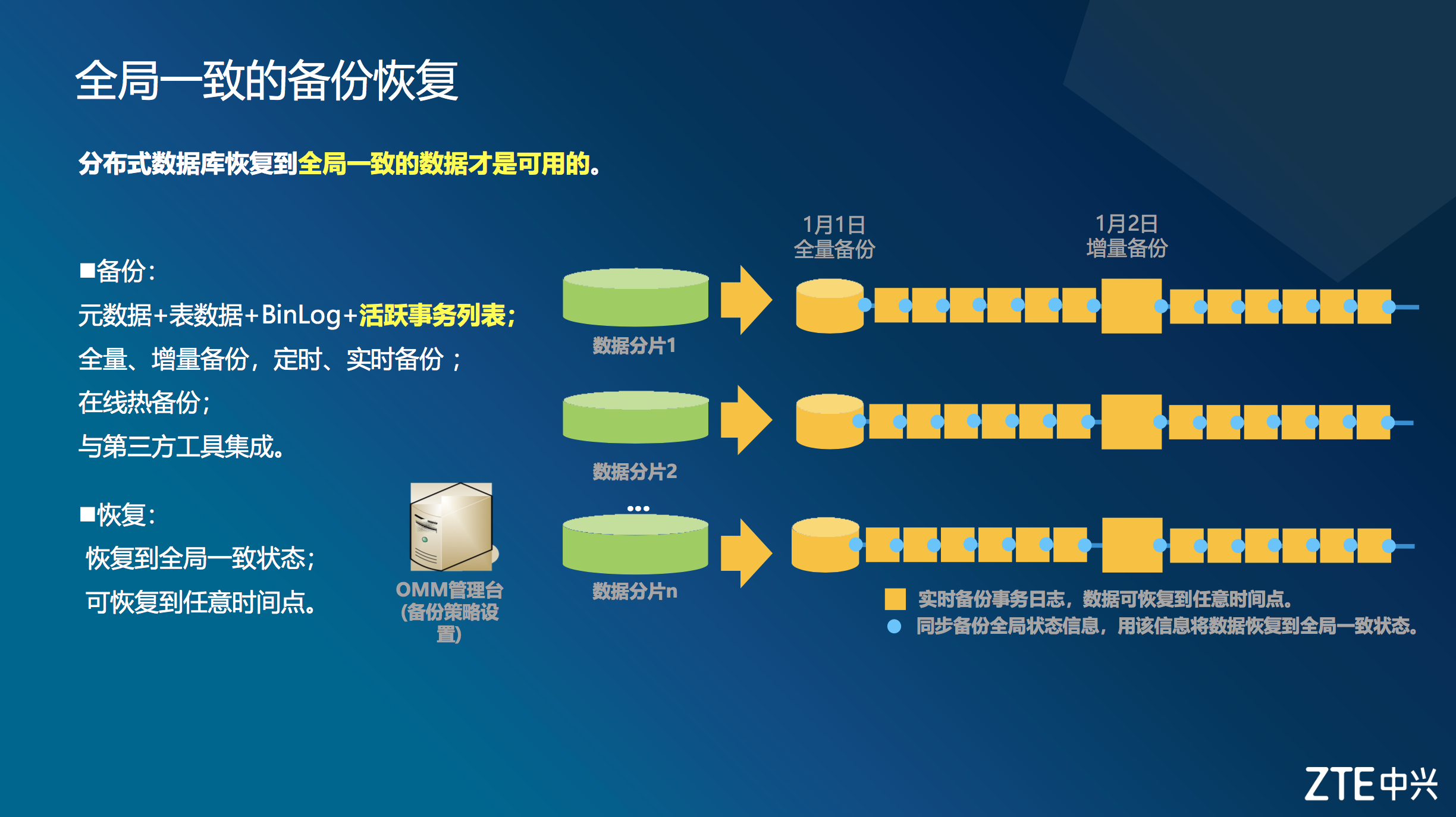
备份恢复的基本原理
基本原理一:备份分类
- data数据备份:又分为全量备份与增量备份
- binlog日志备份:备份存储节点下的binlog二进制文件,恢复操作中用于数据一致性处理
- 活跃事务列表备份:活跃事务列表,可用于保证全局节点恢复数据一致性
基本原理二:备份策略_数据备份
- 定时备份: 周日备份全量备份,其他时间分别在周日全量备份的基础上做一次增量备份。同时备份策略也可调整:选择不备份、全量备份和增量备份。
- 实时备份: 用户可以在操作运维页面上手动发起备份,从而满足特定场景下的实时备份需求。
基本原理三:备份策略_binlog、活跃事务列表
- binlog日志备份: 每个DB节点定时备份binlog日志
- 活跃事务列表备份
基本原理四:备份目录结构
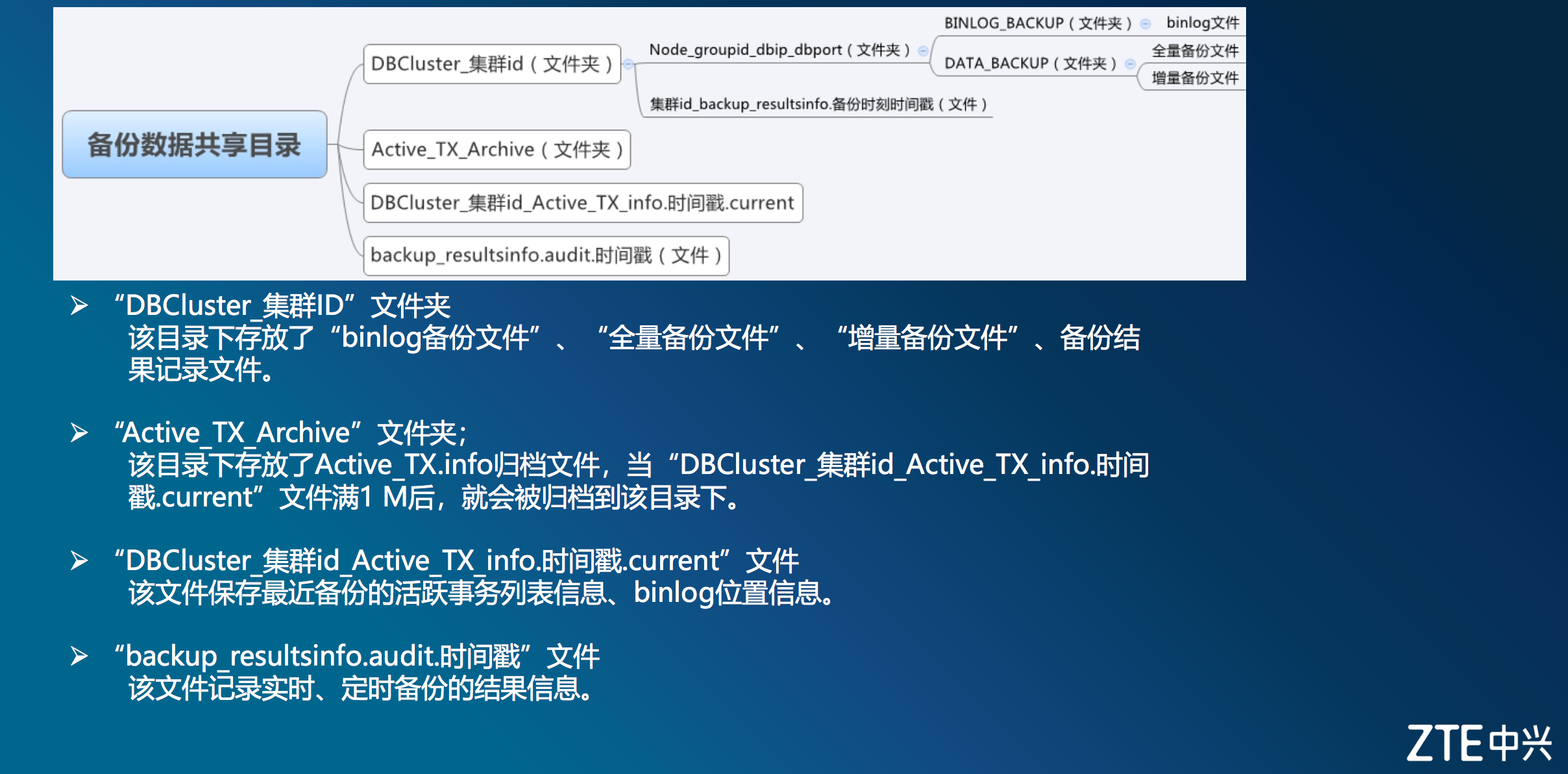 图为备份目录结构分类及示意
图为备份目录结构分类及示意
备份操作
备份操作也分为三个步骤:data数据备份_定时、data数据备份_实时、data数据备份成功。
data数据备份_定时
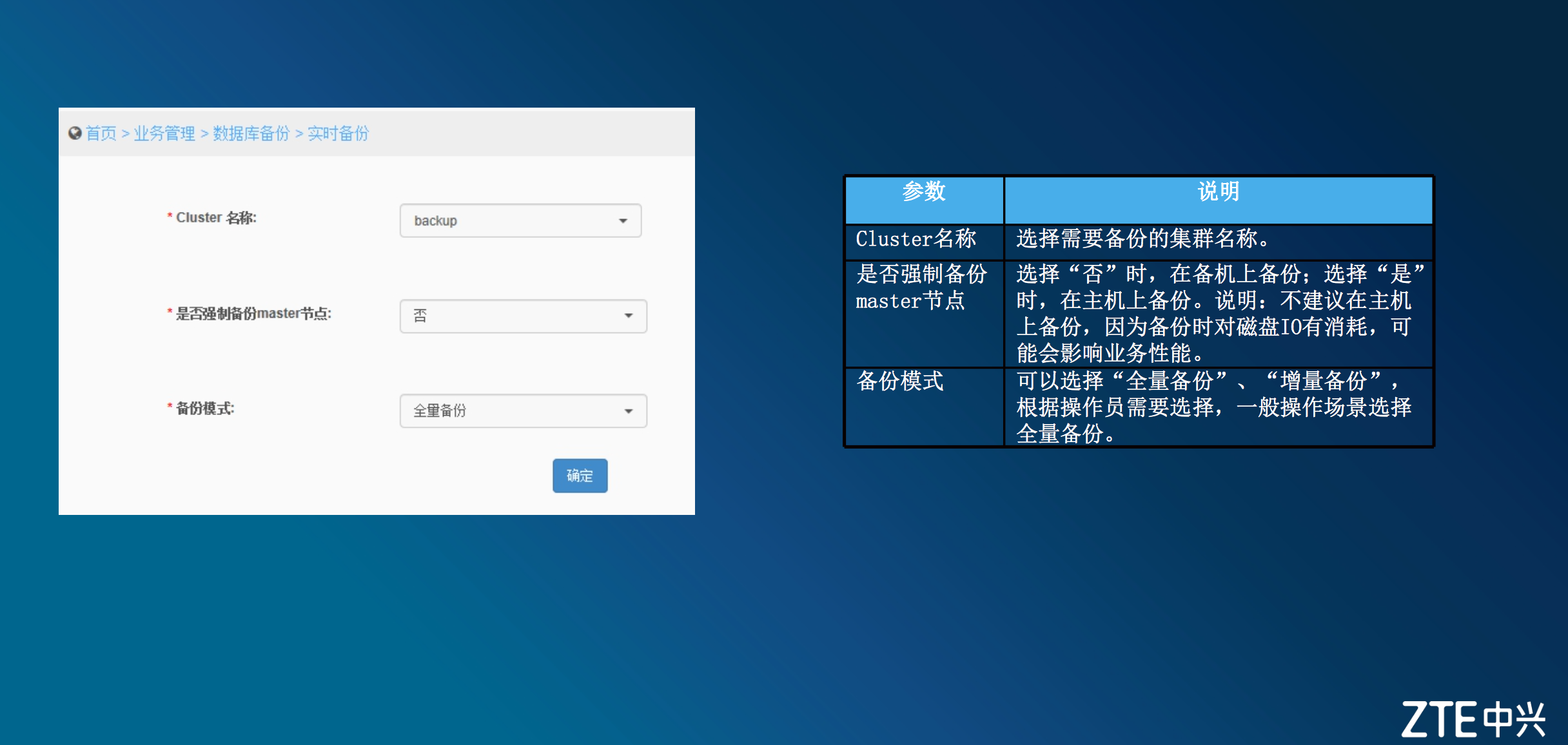
在下图中显示,左侧的运维页面图,就可以制定对应的备份策略。 比如备份的集群、备份开始的时间、是否强制备份等等...
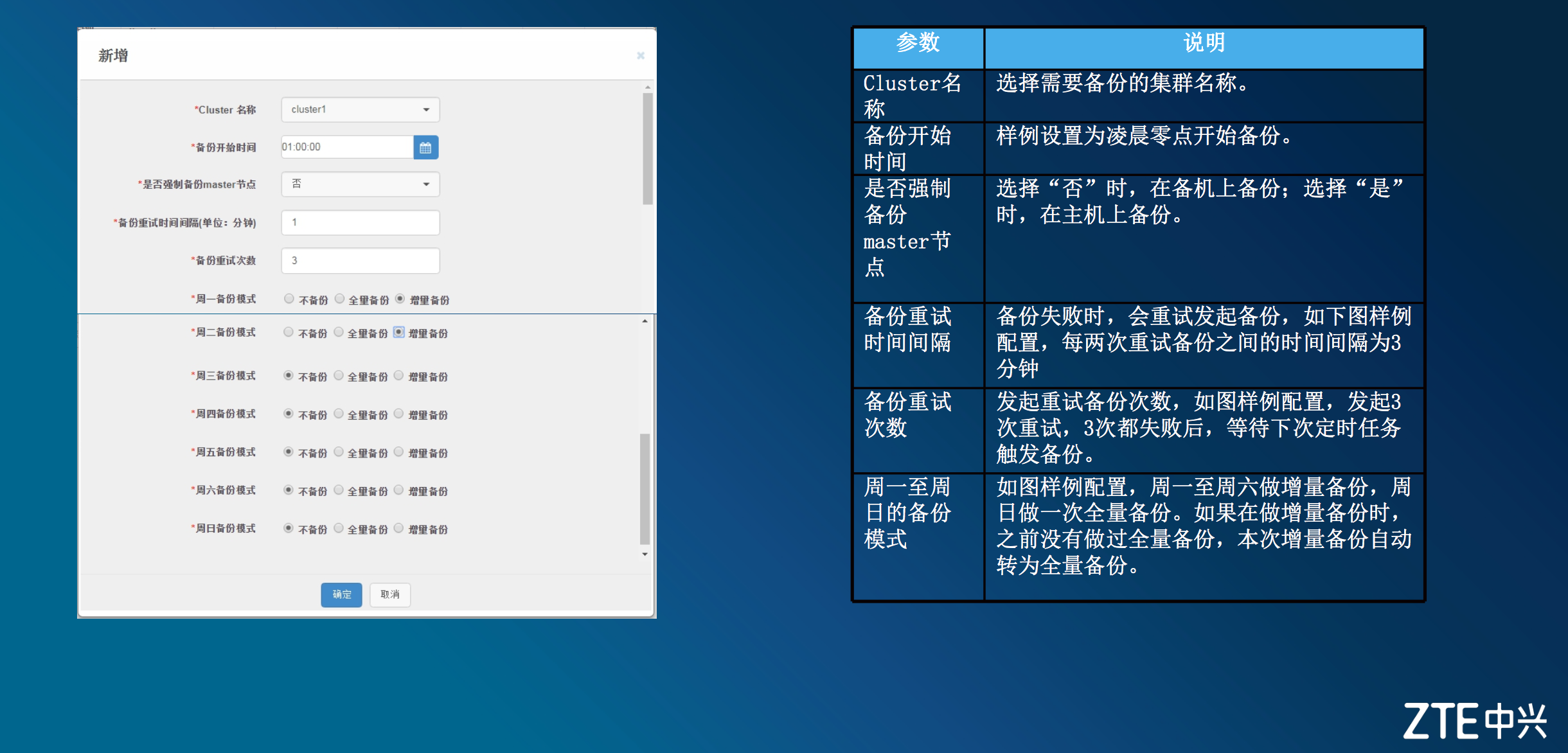
data数据备份_实时
与data数据备份_定时相同,在运维页面就可以发起对应的备份操作和模式
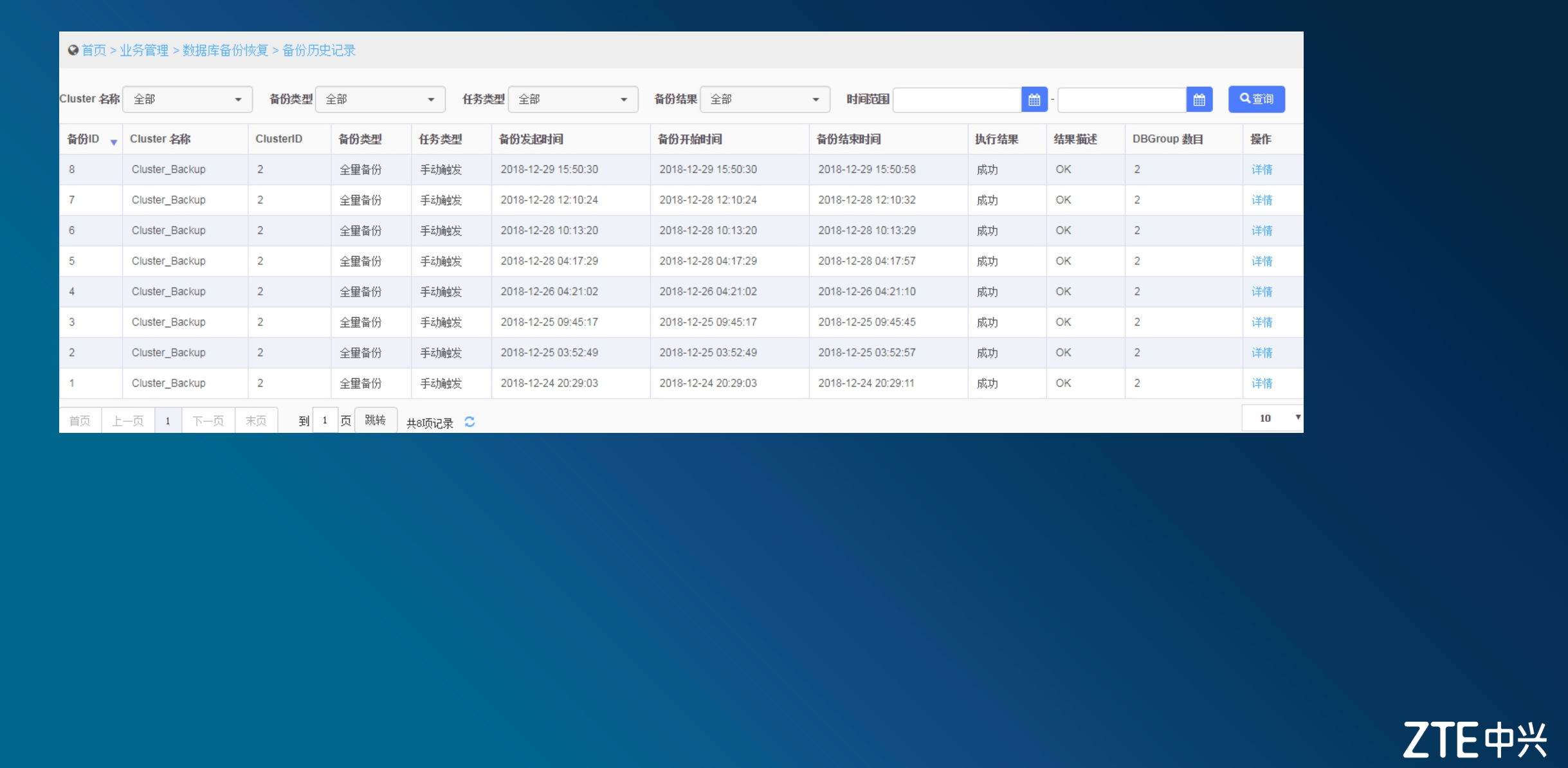
data数据备份成功
备份成功后,即可在运维页面上看到对应的数据:集群名称、备份发起时间、备份开始与结束时间等。
恢复操作
如果在生产中遇到误操作导致数据丢失,就需要对数据进行恢复。可以通过两种方式实现恢复,分别是自动恢复和手动恢复。
如果环境没有安装NFS服务、那么就需要人为拷贝数据到恢复的DB上;当数据拷贝完成后,通过OMM页面完成对需要恢复DB的恢复操作。
最后张晓庆老师还分享了某股份制银行商业备份工具支持的案例,大家可以观看视频回放了解更多精彩内容!
视频回放:https://www.modb.pro/video/5455 会议资料:https://www.modb.pro/doc/48522
墨天轮,围绕数据人的学习成长提供一站式的全面服务,打造集新闻资讯、在线问答、活动直播、在线课程、文档阅览、资源下载、知识分享及在线运维为一体的统一平台,持续促进数据领域的知识传播和技术创新。
关注官方公众号: 墨天轮、 墨天轮平台、墨天轮成长营、数据库国产化 、数据库资讯
墨天轮国产数据库沙龙 | 张晓庆:GoldenDB分布式数据库的自动安装与备份恢复的更多相关文章
- 【DB宝46】NoSQL数据库之CouchBase简介、集群搭建、XDCR同步及备份恢复
目录 一. CouchBase概述 1.1.简述 1.2.CouchDB和CouchBase比对 1.2.1.CouchDB和CouchBase的相同之处 1.2.2.CouchDB和CouchBas ...
- 【巨杉数据库SequoiaDB】省级农信国产分布式数据库应用实践
本文转载自<金融电子化> 原文链接:https://mp.weixin.qq.com/s/WGG91Rv9QTBHPsNVPG8Z5g 随着移动互联网的迅猛发展,分布式架构在互联网IT技术 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 分布式数据库千亿级超大表优化实践
01 引言 随着用户的增长.业务的发展,大型企业用户的业务系统的数据量越来越大,超大数据表的性能问题成为阻碍业务功能实现的一大障碍.其中,流水表作为最常见的一类超大表,是企业级用户经常碰到的性能瓶颈. ...
- 【巨杉数据库Sequoiadb】点燃深秋,巨杉数据库亮相DTC数据技术嘉年华大会
2019年11月15日,第九届数据技术嘉年华大会在北京隆重召开,本次大会以 “开源 • 智能 • 云数据 - 自主驱动发展 创新引领未来” 为主题,探索数据价值,共论智能未来.SequoiaDB 巨 ...
- DTCC 2020 | 阿里云李飞飞:云原生分布式数据库与数据仓库系统点亮数据上云之路
简介: 数据库将面临怎样的变革?云原生数据库与数据仓库有哪些独特优势?在日前的 DTCC 2020大会上,阿里巴巴集团副总裁.阿里云数据库产品事业部总裁.ACM杰出科学家李飞飞就<云原生分布式数 ...
- Amoeba:开源的分布式数据库Porxy解决方案
http://www.biaodianfu.com/amoeba.html 什么是Amoeba? Amoeba(变形虫)项目,该开源框架于2008年 开始发布一款 Amoeba for Mysql软件 ...
- ThinkPHP 数据库操作(五) : 存储过程、数据集、分布式数据库
存储过程 5.0支持存储过程,如果我们定义了一个数据库存储过程 sp_query ,可以使用下面的方式调用: $result = Db::query('call sp_query(8)'); 返回的是 ...
- Redis_NoSql分布式数据库CAP原理
前文简单介绍了NoSql数据库的四大分类以及常用的数据库技术,本文简单介绍分布式数据库CAP原理. 一.传统的CAID是什么 1. A(Atomicity)原子性:事务里的所有操作要么全部做完,要么都 ...
- thinkphp 分布式数据库支持
ThinkPHP内置了分布式数据库的支持,包括主从式数据库的读写分离,但是分布式数据库必须是相同的数据库类型. 配置DB_DEPLOY_TYPE 为1 可以采用分布式数据库支持.如果采用分布式数据库, ...
- 巨杉Talk | 拒绝数据碎片化,原生分布式数据库灵活应对数据管理需求
2019年7月19-20日,以“运筹帷幄,数揽未来”为主题的DAMS中国数据智能管理峰会在上海青浦区成功举办.在DAMS峰会上,巨杉数据库为大家带来了题为“云架构下的分布式数据库设计与实践”的主题分享 ...
随机推荐
- Linux 有趣命令
代码雨 1.上传软件包 Linux 获取 wget https://jaist.dl.sourceforge.net/project/cmatrix/cmatrix/1.2a/cmatrix-1.2a ...
- Jmeter函数助手22-V
V函数用于执行变量名.嵌套函数.类似eval函数 Name of variable (may include variable and function references):必填,填入变量名称或者 ...
- 【Vue】单元格合并,与动态校验
效果要求 先看需求效果: 多个数据授权项,配置的时候,业务名称大多数都是一样的,需要合并单元格处理 在elementUI组件文档中有说明[合并列行]: https://element.eleme.io ...
- 【JS】03 BOM 浏览器对象模型
BOM :Broswer Object Model 浏览器对象模型 核心对象是window对象,window对象又可以操作以下的常见对象: - frames[] 窗口对象数组? 浏览器可以打开多个窗口 ...
- 【Shiro】03 ini认证实现
[基本概念] 1.身份验证 即在应用中谁能证明他就是他本人. 一般提供如他们的身份ID 一些标识信息来表明他就是他本人,如提供身份证,用户名/密码来证明. 在 shiro 中,用户需要提供princi ...
- Dolphinscheduler Docker部署全攻略
作者| 陈逸飞 Docker部署的目的是在容器中快速启动部署Apache Dolphinscheduler服务. 先决条件 docker-compose docker 使用容器单机部署Dolphins ...
- Error in v-on handler: "TypeError: Cannot read property 'value' of undefined"
Error in v-on handler: "TypeError: Cannot read property 'value' of undefined" 报错如下所示,即 在运行 ...
- UCX84X笔记
1. 管脚定义 COMP: 误差放大器补偿引脚.将外部补偿元件连接到此引脚,以修改误差放大器输出.误差放大器内部有电流限制,因此用户可以通过外部强制COMP接地来命令零占空比. UCx84x系列中的误 ...
- 2.3 Exception model
2.3.1 异常状态 2.3.1 异常类型
- Camera | 4.瑞芯微平台MIPI摄像头应用程序编写
前面3篇我们讲解了camera的基础概念,MIPI协议,CSI2,常用命令等,本文带领大家入门,如何用c语言编写应用程序来操作摄像头. Linux下摄像头驱动都是基于v4l2架构,要基于该架构编写摄像 ...