YOLOv10添加输出各类别训练过程指标
昨天有群友,在交流群【群号:392784757】里提到了这个需求,进行实现一下
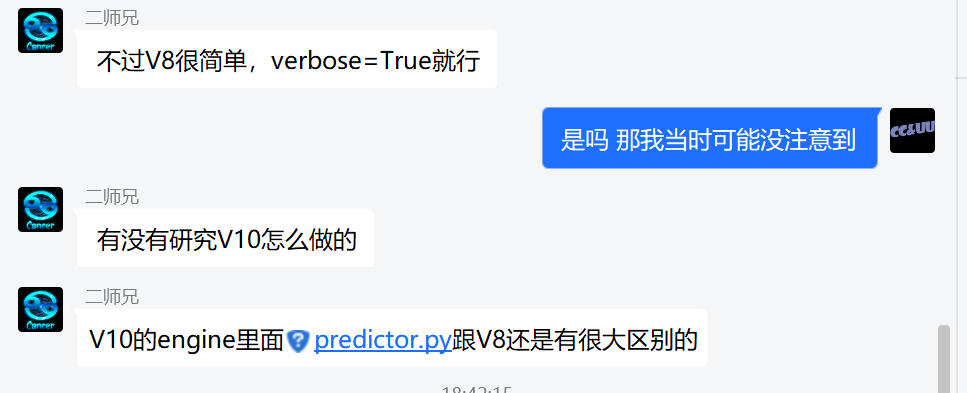
V10 官方代码结构相较于 V8 稍微复杂一些
yolov10 是基于 v8 的代码完成开发,yolov10 进行了继承来简化代码开发
因此 V10 的代码修改 基本和 V8 这篇一致
https://blog.csdn.net/csy1021/article/details/134406419
但存在一些不同,会在下面提到
版本环境
YOLOv10 2024.07.01 版本
修改
trainer.py
1 添加 save_metrics_per_class()
在 save_metrics 函数后面,添加下面的 save_metrics_per_class 函数
def save_metrics_per_class(self, box):
"""Saves training metrics per class to a CSV file."""
# ap ap50 p r 提示作用
keys = ['ap', 'ap50', 'p', 'r']
n = 4 + 1 # number of cols
for i in box.ap_class_index:
cur_class = self.model.names[box.ap_class_index[i]]
save_path = self.save_dir.joinpath("result_" + cur_class + ".csv")
vals = [box.ap[i], box.ap50[i], box.p[i], box.r[i]]
s = '' if save_path.exists() else (('%23s,' * n % tuple(['epoch'] + keys)).rstrip(',') + '\n') # header
with open(save_path, 'a') as f:
f.write(s + ('%23.5g,' * n % tuple([self.epoch] + vals)).rstrip(',') + '\n')
2 validate() 修改
def validate(self):
"""
Runs validation on test set using self.validator.
The returned dict is expected to contain "fitness" key.
"""
# metrics = self.validator(self)
metrics,box = self.validator(self)
fitness = metrics.pop("fitness", -self.loss.detach().cpu().numpy()) # use loss as fitness measure if not found
if not self.best_fitness or self.best_fitness < fitness:
self.best_fitness = fitness
# return metrics, fitness
return metrics, fitness,box
找到【这里比 v8 的判断要多】
if (self.args.val and (((epoch+1) % self.args.val_period == 0) or (self.epochs - epoch) <= 10)) \
or final_epoch or self.stopper.possible_stop or self.stop:
self.metrics, self.fitness = self.validate()
修改为
if (self.args.val and (((epoch+1) % self.args.val_period == 0) or (self.epochs - epoch) <= 10)) \
or final_epoch or self.stopper.possible_stop or self.stop:
# self.metrics, self.fitness = self.validate()
self.metrics, self.fitness,box = self.validate()
3 找到 self.save_metrics
在
self.save_metrics(metrics={**self.label_loss_items(self.tloss), **self.metrics, **self.lr})
后面添加调用
self.save_metrics_per_class(box)
validator.py
找到 stats = self.get_stats()
改为 stats,box = self.get_stats()
找到 return {k: round(float(v), 5) for k, v in results.items()}
改为 return {k: round(float(v), 5) for k, v in results.items()}, box
val.py
get_stats() 【注意与 v8 不同】
def get_stats(self):
"""Returns metrics statistics and results dictionary."""
stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # to numpy
# if len(stats) and stats["tp"].any():
# if len(stats) and stats[0].any():
if len(stats) :
self.metrics.process(**stats)
self.nt_per_class = np.bincount(
stats["target_cls"].astype(int), minlength=self.nc
) # number of targets per class
# return self.metrics.results_dict
return self.metrics.results_dict,self.metrics.box
save_metrics_per_class() 函数 【注意与 v8 不同】
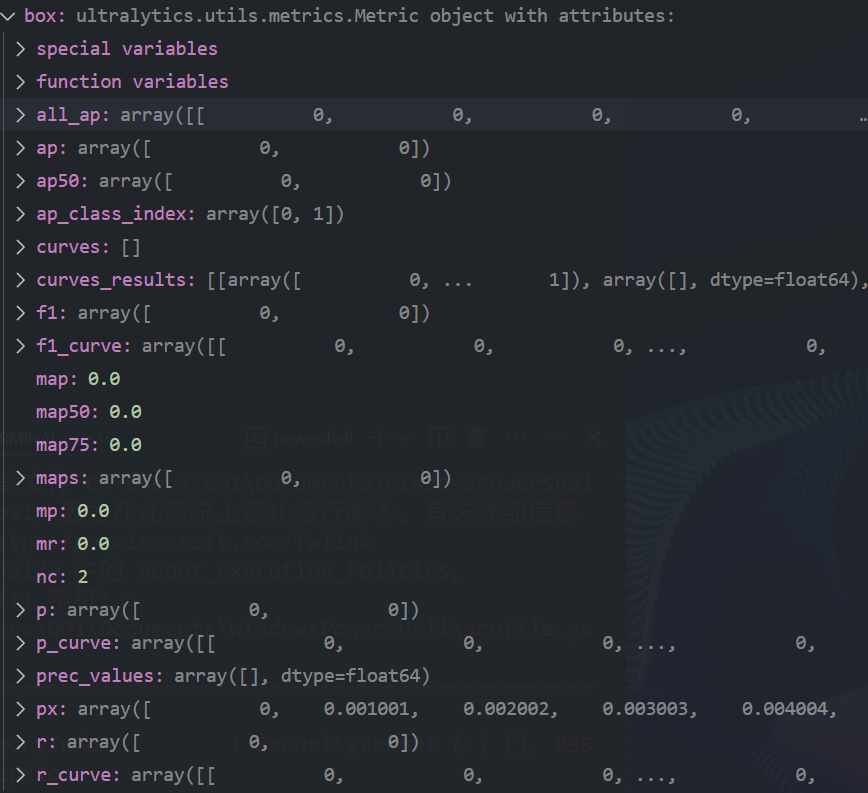
可以看到支持的指标有 all_ap (可用来计算其他ap指标),map,map50,f1,p ap,r mr ...
我在函数中使用的是 ap,ap50,p,r,需要其他的可以再添加
==注意:添加指标,使用的是 . 而不是 ["xxxx"] 如 box.ap[i] 而不是 box['ap'][i]==
def save_metrics_per_class(self, box):
"""Saves training metrics per class to a CSV file."""
# ap ap50 p r 提示作用
keys = ['ap', 'ap50', 'p', 'r']
n = 4 + 1 # number of cols
for i in box.ap_class_index:
cur_class = self.model.names[box.ap_class_index[i]]
save_path = self.save_dir.joinpath("result_" + cur_class + ".csv")
vals = [box.ap[i], box.ap50[i], box.p[i], box.r[i]]
s = '' if save_path.exists() else (('%23s,' * n % tuple(['epoch'] + keys)).rstrip(',') + '\n') # header
with open(save_path, 'a') as f:
f.write(s + ('%23.5g,' * n % tuple([self.epoch] + vals)).rstrip(',') + '\n')
注意!不同点
def get_stats(self):
"""Returns metrics statistics and results dictionary."""
stats = {k: torch.cat(v, 0).cpu().numpy() for k, v in self.stats.items()} # to numpy
# if len(stats) and stats["tp"].any(): # v10
# if len(stats) and stats[0].any(): # v8
if len(stats) : # 修改后
self.metrics.process(**stats)
self.nt_per_class = np.bincount(
stats["target_cls"].astype(int), minlength=self.nc
) # number of targets per class
# return self.metrics.results_dict
return self.metrics.results_dict,self.metrics.box
v10

v8

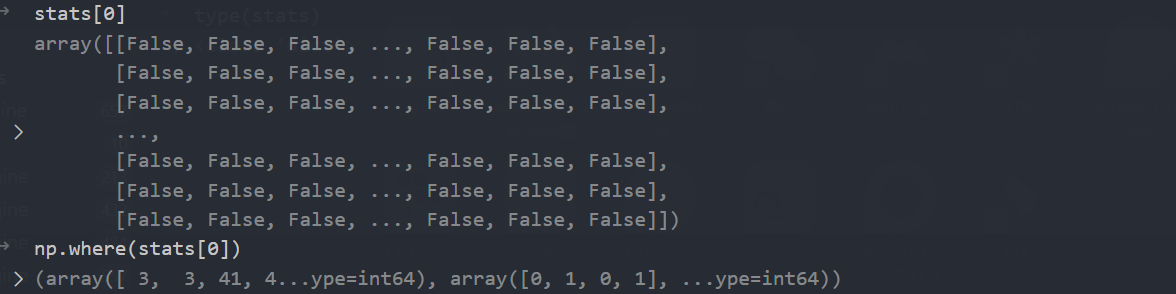
如果不修改 这个判断条件
if len(stats) and stats["tp"].any(): # v10
# if len(stats) and stats[0].any(): # v8 仅作对比
if len(stats) : # 修改后
可能会出现 前几次 epoch 数据不记录的问题 【这里也可能是和我的数据集有关,我测试了几次,增加 batch-size 发现仍然 stats["tp"] 仍然全为 false 过不了,后面 epoch 会正常 】这里大家可以自行测试后决定,如果正常,就不需要改
其他
增加训练过程各类指标打印(可选,默认开启是有条件的)
val.py 找到 print_results() 函数 在
LOGGER.info(pf % ('all', self.seen, self.nt_per_class.sum(), *self.metrics.mean_results())) 后面
添加
for i, c in enumerate(self.metrics.ap_class_index):
LOGGER.info(pf % (self.names[c], self.seen, self.nt_per_class[c], *self.metrics.class_result(i)))
有问题,欢迎留言、进群讨论或私聊:【群号:392784757】
YOLOv10添加输出各类别训练过程指标的更多相关文章
- (转)理解YOLOv2训练过程中输出参数含义
最近有人问起在YOLOv2训练过程中输出在终端的不同的参数分别代表什么含义,如何去理解这些参数?本篇文章中我将尝试着去回答这个有趣的问题. 刚好现在我正在训练一个YOLOv2模型,拿这个真实的例子来讨 ...
- 理解YOLOv2训练过程中输出参数含义
原英文地址: https://timebutt.github.io/static/understanding-yolov2-training-output/ 最近有人问起在YOLOv2训练过程中输出在 ...
- TensorFlow从1到2(七)线性回归模型预测汽车油耗以及训练过程优化
线性回归模型 "回归"这个词,既是Regression算法的名称,也代表了不同的计算结果.当然结果也是由算法决定的. 不同于前面讲过的多个分类算法或者逻辑回归,线性回归模型的结果是 ...
- 深度学习笔记之关于基本思想、浅层学习、Neural Network和训练过程(三)
不多说,直接上干货! 五.Deep Learning的基本思想 假设我们有一个系统S,它有n层(S1,…Sn),它的输入是I,输出是O,形象地表示为: I =>S1=>S2=>….. ...
- 交叉熵代价函数——当我们用sigmoid函数作为神经元的激活函数时,最好使用交叉熵代价函数来替代方差代价函数,以避免训练过程太慢
交叉熵代价函数 machine learning算法中用得很多的交叉熵代价函数. 1.从方差代价函数说起 代价函数经常用方差代价函数(即采用均方误差MSE),比如对于一个神经元(单输入单输出,sigm ...
- 吴裕雄 python 神经网络——TensorFlow 训练过程的可视化 TensorBoard的应用
#训练过程的可视化 ,TensorBoard的应用 #导入模块并下载数据集 import tensorflow as tf from tensorflow.examples.tutorials.mni ...
- DL4J实战之六:图形化展示训练过程
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本篇是<DL4J实战>系列的第六 ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- 从零搭建Pytorch模型教程(四)编写训练过程--参数解析
前言 训练过程主要是指编写train.py文件,其中包括参数的解析.训练日志的配置.设置随机数种子.classdataset的初始化.网络的初始化.学习率的设置.损失函数的设置.优化方式的设置. ...
- (原)torch的训练过程
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6221622.html 参考网址: http://ju.outofmemory.cn/entry/284 ...
随机推荐
- LLM推理 - Nvidia TensorRT-LLM 与 Triton Inference Server
1. LLM部署-TensorRT-LLM与Triton 随着LLM越来越热门,LLM的推理服务也得到越来越多的关注与探索.在推理框架方面,tensorrt-llm是非常主流的开源框架,在Nvidia ...
- python3 安装pyodbc失败 pip3 install pyodbc
python3 安装pyodbc失败 报错1: 关键报错信息: fatal error: sql.h: No such file or directory [root@centfos python3 ...
- tp5 为什么使用单例模式
首先我们要知道明确单例模式这个概念,那么什么是单例模式呢?单例模式顾名思义,就是只有一个实例.作为对象的创建模式,单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例, 这个类我们 ...
- 火山引擎ByteHouse发布高性能全文检索引擎
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群. 随着数字时代的发展,数据的来源和生成方式越来越广泛,数据形态也愈加丰富. 以某电商平台的数据情况举例.该电 ...
- [oeasy]python0022_ python虚拟机_反编译_cpu架构_二进制字节码_汇编语言
程序本质 回忆上次内容 python3 的程序是一个 5.3M 的可执行文件 我们通过which命令找到这个python3.8的位置 将这个python3.8复制到我们的用户目录下 这个文件 ...
- 前端太卷了,不玩了,写写node.js全栈涨工资,赶紧学起来吧!!!!!
首先聊下node.js的优缺点和应用场景 Node.js的优点和应用场景 Node.js作为后端开发的选择具有许多优点,以下是其中一些: 高性能: Node.js采用了事件驱动.非阻塞I/O模型,使得 ...
- AX网相关图片(原创)
官网:AXA6.COM | The future is come. Copyright 2020 – 2023| AX网 Axa6.Com | All Rights Reserved
- Vue 在父(子)组件引用其子(父)组件方法和属性
Vue 在父(子)组件引用其子(父)组件方法和属性 by:授客 QQ:1033553122 开发环境 Win 10 element-ui "2.8.2" Vue 2. ...
- LeetCode455.分发饼干
LeetCode题目链接:https://leetcode.cn/problems/assign-cookies/description/ 题目叙述 假设你是一位很棒的家长,想要给你的孩子们一些小饼干 ...
- 解决Sqoop导入导出MySQL数据错位问题
添加--columns "columns,columns,columns" \可以在hive导入mysql时防止数据错位: