kafka 工作流程及文件存储机制

1、kafka的数据存储
文件存储格式: .log 和 .index
Kafka 中消息是以 topic 进行分类的, 生产者生产消息,消费者消费消息,都是面向 topic的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。
Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。 消费者组中的每个消费者, 都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
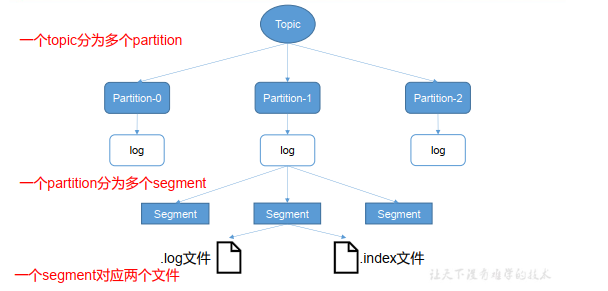
如图:由于生产者生产的消息会不断追加到 log 文件末尾, 为防止 log 文件过大导致数据定位效率低下, Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。
每个 segment对应两个文件——“.index”文件和“.log”文件。 这些文件位于一个文件夹下, 该文件夹的命名规则为: topic 名称+分区序号。例如, first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。


“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
文件根据大小拆分成多个分片,.index存储offset、数据位置; .log存储数据;通过index的offet和数据位置 找到在log中数据
比如:要查找绝对offset为7的Message:
- 首先是用2分查找肯定它是在哪一个LogSegment中,自然是在第1个Segment中。
- 打开这个Segment的index文件,也是用2分查找找到offset小于或等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映照到内存中,所以查找的速度还是很快的。
1句话,Kafka的Message存储采取了分区(partition),分段(LogSegment)和稀疏索引这几个手段来到达了高效性。
kafka 工作流程及文件存储机制的更多相关文章
- Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程: 每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性. Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的 ...
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
随机推荐
- Git - 关联远程仓库以及同时使用Lab和Hub
更新一下,感觉有更简单的方式 就比如你git config 的 全局的name和email是lab的 那就clone github上的项目然后设置局部的name和email就行了 ********** ...
- 从零开始配置vim(25)——关于 c++ python 的配置
从9月份到国庆这段时间,因为得了女儿,于是回老家帮忙料理家事以及陪伴老婆和女儿.一时之间无暇顾及该系列教程的更新.等我回来的时候发现很多小伙伴私信我催更.在这里向支持本人这一拙劣教程的各位小伙伴表示真 ...
- gRPC学习小札
gRPC 前言 为什么使用gRPC 传输协议 传输效率 性能消耗 gRPC入门 gRPC流 证书认证 使用根证书 gRPC实现token认证 和Web服务共存 验证器 REST接口 grpcurl工具 ...
- PHP的数据对象PDO
PHP的数据对象PDO 一.什么是PDO 手册说:PHP 数据对象 (PHP Data Object) 扩展为PHP访问数据库定义了一个轻量级的一致接口.实现 PDO 接口的每个数据库驱动可以公开具体 ...
- Qt processEvents - 解决线程中事件阻塞(如槽函数被阻塞)
百度了一会,发现没太有文字讲这件事情,因此整理成文字记录一下. processEvents介绍 长时间运行的操作可以调用processEvents() 保持应用程序响应能力. void QCoreAp ...
- NC20960 迪拜的超市
题目链接 题目 题目描述 forever97家住迪拜一环,因此有很多大大小小的商场. 迪拜一环有n个超市,分别在坐标轴[1,n]位置,forever97家在0这个位置. 由于日常开销巨大,所以Trot ...
- STC8H8K64U 的 USB 功能测试(续)
对 STC8H8K64U 的USB测试昨天没搞定, 判断可能是供电的问题, 直接用5V不行, 从USB2TTL上采电3.3V时存在一个问题, 就是 D-/D+ 在上电前就已经连接了, 不符合 USB ...
- spring事务的传播
目录 事务的传播行为类型 注意事项 关于事务的传播,我们先确定一个场景:方法A调用方法B,方法A可能存在事务,也可能不存在事务,我们这里重点关注方法B上定义的事务传播行为,以及方法B中出现异常时,方法 ...
- 启动HDFS伪分布式环境时报权限错误
问题描述 操作系统:Ubuntu18.04 LTS HDFS版本:hadoop-3.2.3 普通用户登录,参照官方文档在单机上安装伪分布式环境时,启动HDFS报权限错误. 具体报错信息如下: $ ./ ...
- 2021-10-11 vue的第三方组件二次封装
原理 v-bind="$attrs"继承所有属性和props. v-on="$listeners"继承所有的方法. <template> <d ...