kafka 工作流程及文件存储机制

1、kafka的数据存储
文件存储格式: .log 和 .index
Kafka 中消息是以 topic 进行分类的, 生产者生产消息,消费者消费消息,都是面向 topic的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。
Producer 生产的数据会被不断追加到该log 文件末端,且每条数据都有自己的 offset。 消费者组中的每个消费者, 都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
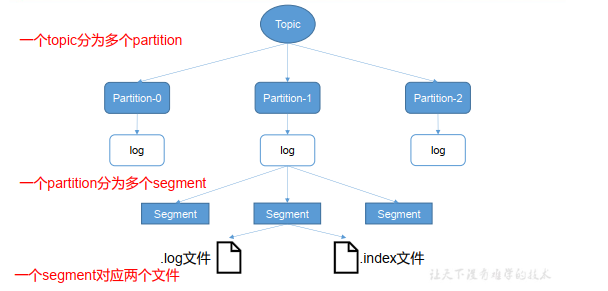
如图:由于生产者生产的消息会不断追加到 log 文件末尾, 为防止 log 文件过大导致数据定位效率低下, Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。
每个 segment对应两个文件——“.index”文件和“.log”文件。 这些文件位于一个文件夹下, 该文件夹的命名规则为: topic 名称+分区序号。例如, first 这个 topic 有三个分区,则其对应的文件夹为 first-0,first-1,first-2。


“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
文件根据大小拆分成多个分片,.index存储offset、数据位置; .log存储数据;通过index的offet和数据位置 找到在log中数据
比如:要查找绝对offset为7的Message:
- 首先是用2分查找肯定它是在哪一个LogSegment中,自然是在第1个Segment中。
- 打开这个Segment的index文件,也是用2分查找找到offset小于或等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
这套机制是建立在offset是有序的。索引文件被映照到内存中,所以查找的速度还是很快的。
1句话,Kafka的Message存储采取了分区(partition),分段(LogSegment)和稀疏索引这几个手段来到达了高效性。
kafka 工作流程及文件存储机制的更多相关文章
- Kafka架构深入:Kafka 工作流程及文件存储机制
kafka工作流程: 每个分区都有一个offset消费偏移量,kafka并不能保证全局有序性. Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的 ...
- 深入了解Kafka【二】工作流程及文件存储机制
1.Kafka工作流程 Kafka中的消息以Topic进行分类,生产者与消费者都是面向Topic处理数据. Topic是逻辑上的概念,而Partition是物理上的概念,每个Partition分为多个 ...
- Kafka与RocketMq文件存储机制对比
一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一. 开头问题 kafka文件结构和rocketMQ文件结构是什么样子?特点是什么? 一.目录结构 Kafk ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
- kafka学习之-文件存储机制
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- 转】 Kafka文件存储机制那些事
原博文出自于:http://tech.meituan.com/kafka-fs-design-theory.html 感谢! Kafka是什么 Kafka是最初由Linkedin公司开发,是一个 ...
随机推荐
- C# 通过VMI接口获取硬件ID
使用C#语言实现通过VMI(虚拟机监控器)接口来获取硬件ID的过程.VMI是一种用于虚拟化环境的接口,用于管理虚拟机和宿主机之间的通信和资源共享.具体实现中,需要通过添加System.Manageme ...
- MVC和WebAPI如何从Filter向Action中传递数据
http://www.itfanr.cc/2016/04/17/transfer-data-from-filter-to-action/ MVC和WebAPI如何从Filter向Action中传递数据 ...
- 关于 vant 移动端的 rem 适配方案
一.使用 lib-flexible 动态设置 rem 基准值 (html 标签的字体大小) (1) 安装依赖: npm i amfe-flexible -D (2) 在main.js 中引入 impo ...
- .NET Core开发实战(第27课:定义Entity:区分领域模型的内在逻辑和外在行为)--学习笔记
27 | 定义Entity:区分领域模型的内在逻辑和外在行为 上一节讲到领域模型分为两层 一层是抽象层,定义了公共的接口和类 另一层就是领域模型的定义层 先看一下抽象层的定义 1.实体接口 IEnti ...
- Asp-Net-Core学习笔记:3.使用SignalR实时通信框架开发聊天室
SignalR牛刀小试 在MVP杨老师的博客里看到这么个东西,我还以为是NetCore3才推出的新玩意,原来是已经有很多年的历史了,那看来还是比较成熟的一个技术了. 简介 SignalR是一个.NET ...
- C语言程序设计之字符串处理
C语言程序设计-字符串处理 第一题:回文数判断 问题描述] 回文是正读和倒读都一样的句子.读入一个最大长度不超过50个字符的句子,判断其是否是回文. [输入形式] 输入一个最大长度不超过50个字符的句 ...
- wxPython 笔记
安装 Win7 / Win10 直接通过 pip install wxpython 安装 Ubuntu18.04 / Ubuntu 20.04 在Linux下的安装会稍微麻烦, 可以参考官网上的说明 ...
- 【Unity3D】程序纹理简单应用
1 几何纹理应用 本文所有案例的完整资源详见→Unity3D程序纹理简单应用. 1.1 边框 1)边框子图 Border.shadersubgraph 说明:Any 节点用于判断输入向 ...
- Oracle 高水位(HWM: High Water Mark) 说明
一. 准备知识:ORACLE的逻辑存储管理. ORACLE在逻辑存储上分4个粒度: 表空间, 段, 区 和 块. 1.1 块: 是粒度最小的存储单位,现在标准的块大小是8K,ORACLE每一次I/O操 ...
- oracle sqlplus命令详解(官方示例)
以为内容选自Oracle官方文档,只讲command-line: 规范:<变量名> , {举例} , a | b 枚举可选值,(XX)描述 ------------------------ ...