Hadoop环境安装与配置
1.基础操作系统环境安装(略)
2.JDK的安装与配置
当前各大数据软件如Hadoop等,仍然停留在Java 8上,在本实验选用的是Java 8。在自己的Linux系统中,jdk可以使用如下命令进行一键安装(需具备sudo权限)。
sudo yum install java-1.8.0-openjdk sudo yum install java-1.8.0-openjdk-devel
执行完命令后直接选择y
待安装完成后,需通过如下命令,检查java(jdk)是否安装成功
java -version javac -version
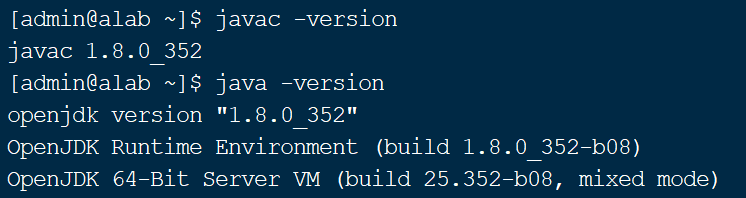
以下为检测情况:
3.Hadoop编译版本的下载,解压,并放置到相应目录中
注意:在接下来的操作中需将用户切换至Hadoop用户下
添加Hadoop专用的用户
在进行Hadoop配置前是需先添加一个Hadoop专用的用户,操作Hadoop系统(含安装、配置,提交计算任务等),一般给该用户配置sudo权限,以便于配置过程中执行一些高权限的操作。以下设置该用户名为hadoop,可以进行如下操作:
sudo useradd -s /bin/bash -m hadoop sudo passwd hadoop sudo usermod -aG wheel hadoop
按照提示输入即可(注意虽然密码长度不足8位,会出现警告,但是仍然可以设置)

上图操作命令分别对应添加Hadoop用户、设置密码和给予sudo权限。
生成SSH密钥、配置SSH免密登录
无论单节点的伪分布式部署,还是3节点的完全分布式部署,均需要配置SSH免密登录。配置免密登录需进行以下两步:
2.1.生成当前用户的密钥
ssh-keygen -t rsa
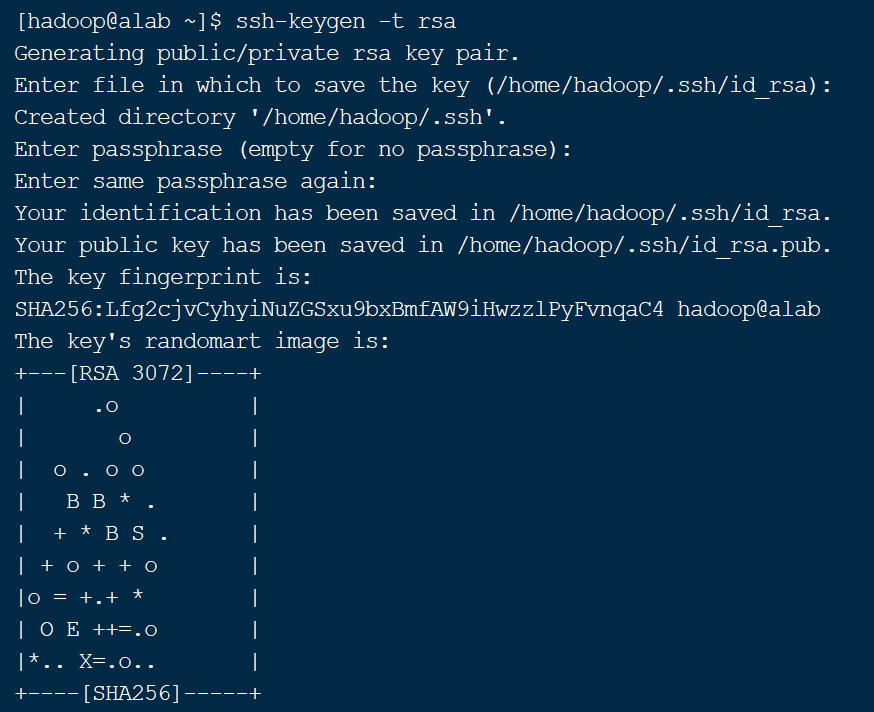
上图中所有步骤均直接按回车即可。
将生成的公钥安装到目标服务器上
ssh-copy-id 用户名@目标服务器的IP,按照提示输入密码等
例如,安装到本机当前用户(hadoop)
ssh-copy-id hadoop@localhost
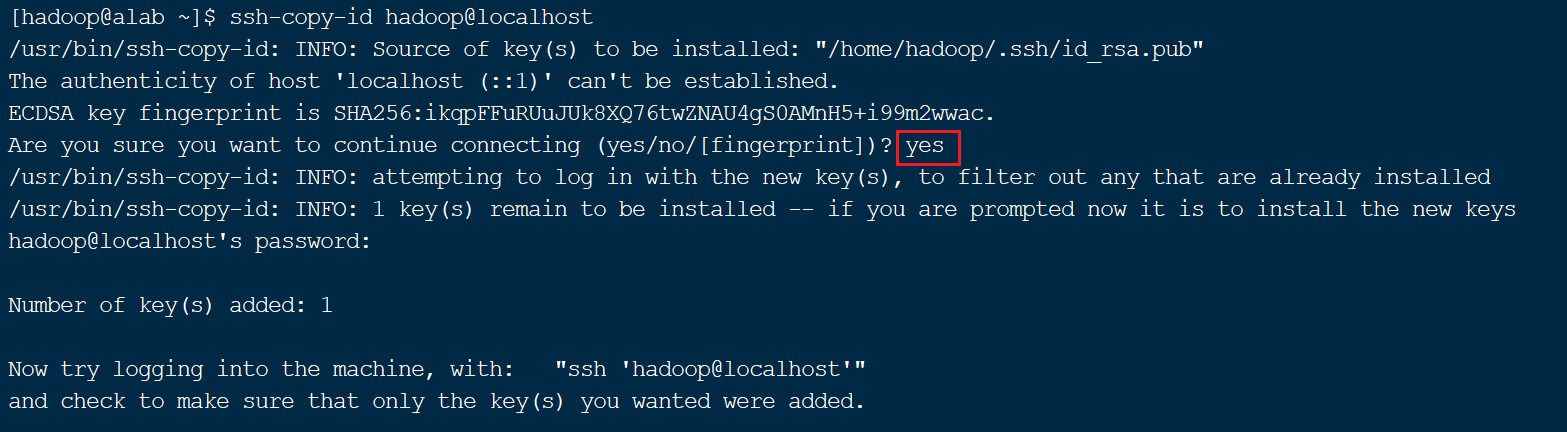
图中红框部分输入yes,其余按提示完成即可。
安装wget工具(Linux系统下的下载工具)
具体操作命令如下:
sudo yum install wget
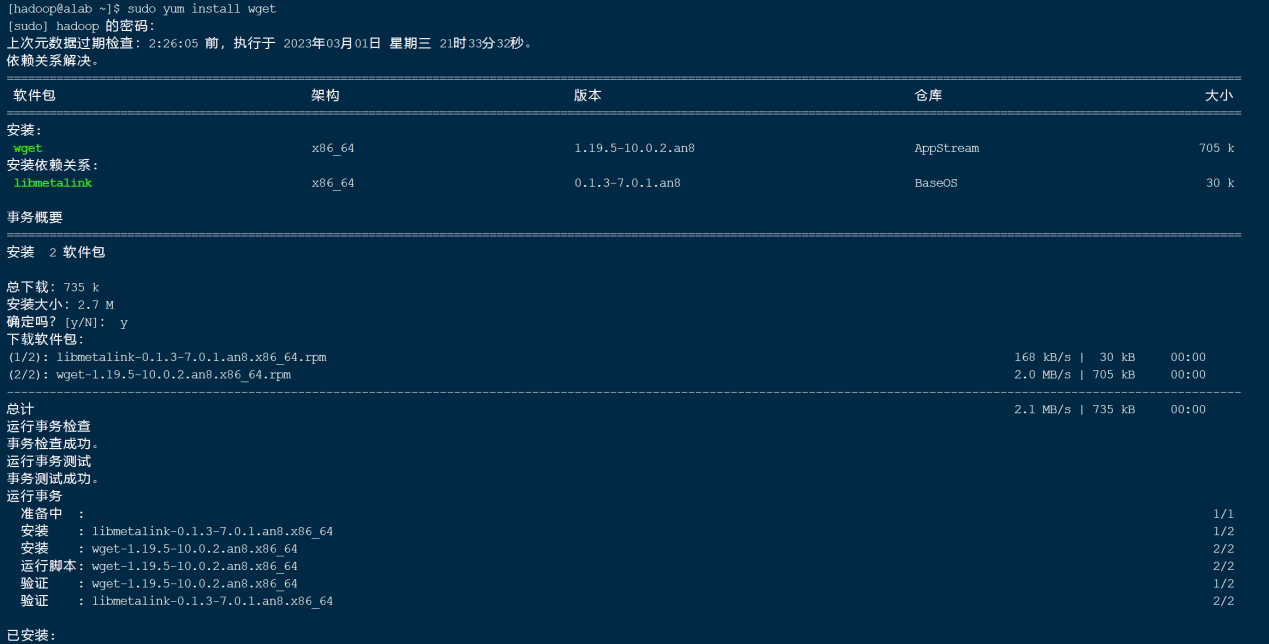
这里直接选择y即可。
Hadoop伪分布式安装
(1)下载安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz

这里直接根据命令下载即可。
(2) 解压文件并放置到适当的位置
一般将用户自己安装的程序放在/usr/local/目录下,为了便于管理,我们统一创建/usr/local/bda/目录,并将此目录(及其子目录)的所有者改为hadoop
sudo mkdir /usr/local/bda
sudo chown -R hadoop:hadoop /usr/local/bda
cd ~ # 切换回hadoop用户的home目录
tar xzvf hadoop-2.10.1.tar.gz
注意:如果提示找不到 tar 命令,则需要先安装,如下面命令所示:
sudo yum install tar

将解压后的文件夹移动到/usr/local/bda/目录下,并改名为hadoop
mv ~/hadoop-2.10.1 /usr/local/bda/hadoop
4.Hadoop环境的配置
Hadoop 2.x主要由HDFS、yarn、MapReduce三部分组成,因此总共有5个文件需要进行配置,分别是:
(1) hadoop-env.sh: Hadoop运行环境
(2) core-site.xml: 集群全局参数
(3) hdfs-site.xml: HDFS的配置
(4) yarn-site.xml: 集群资源管理系统参数
(5) mapred-site.xml:MapReduce的参数
需要说明的是:在执行完本节(4.3)的配置后,实际上完成的是整个Hadoop的配置(含MapReduce、YARN)而不仅仅是HDFS的配置。
- 建立Hadoop所需的目录
因为HDFS、MapReduce正常工作,需要一些专用的目录的辅助。因此在开始配置之前,需要建立相应的文件夹,操作如下:
mkdir /usr/local/bda/hadoop/tmp
mkdir /usr/local/bda/hadoop/var
mkdir /usr/local/bda/hadoop/dfs
mkdir /usr/local/bda/hadoop/dfs/name
mkdir /usr/local/bda/hadoop/dfs/data
- 配置hadoop-env.sh
Hadoop系统环境,只需要配置一个环境变量:JAVA_HOME,也就是告诉Hadoop系统,java的安装位置,使用如下命令打开配置文件:
vim /usr/local/bda/hadoop/etc/hadoop/hadoop-env.sh

进行如下修改,然后保存、退出(:wq)。
- 配置core-site.xml
vim /usr/local/bda/hadoop/etc/hadoop/core-site.xml
添加到core-site.xml文件configuration中的内容如下:
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/bda/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
说明:此处进行了两项配置,(1)配置了hadoop的临时目录;(2)配置了文件系统缺省的主机和端口。因为是伪分布式系统,所以此处的主机名是localhost
- 配置hdfs-site.xml
vim /usr/local/bda/hadoop/etc/hadoop/hdfs-site.xml
进行如下图的配置,各项的说明见下图中的红字,保存,退出

- 配置mapred-site.xml
首先,将mapred-site.xml的配置模板文件mapred-site.xml.template复制一份,并命名为mapred-site.xml

然后用vim打开进行编辑
vim /usr/local/bda/hadoop/etc/hadoop/mapred-site.xml
配置内容如下图所示,保存、退出

- 配置yarn-site.xml
vim /usr/local/bda/hadoop/etc/hadoop/yarn-site.xml
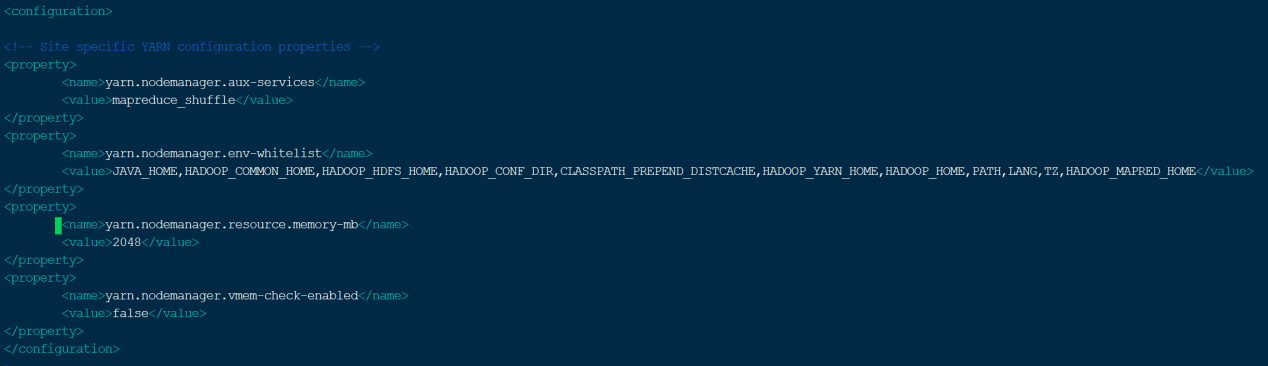
配置内容如下图所示,保存、退出
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5.Hadoop环境的验证
5.1.HDFS文件系统格式化及服务启动、关闭
5.1.1. HDFS文件系统格式化
如同其它的文件系统一样,HDFS在使用之前也要先进行格式化操作,使用如下的命令进行:
/usr/local/bda/hadoop/bin/hdfs namenode -format
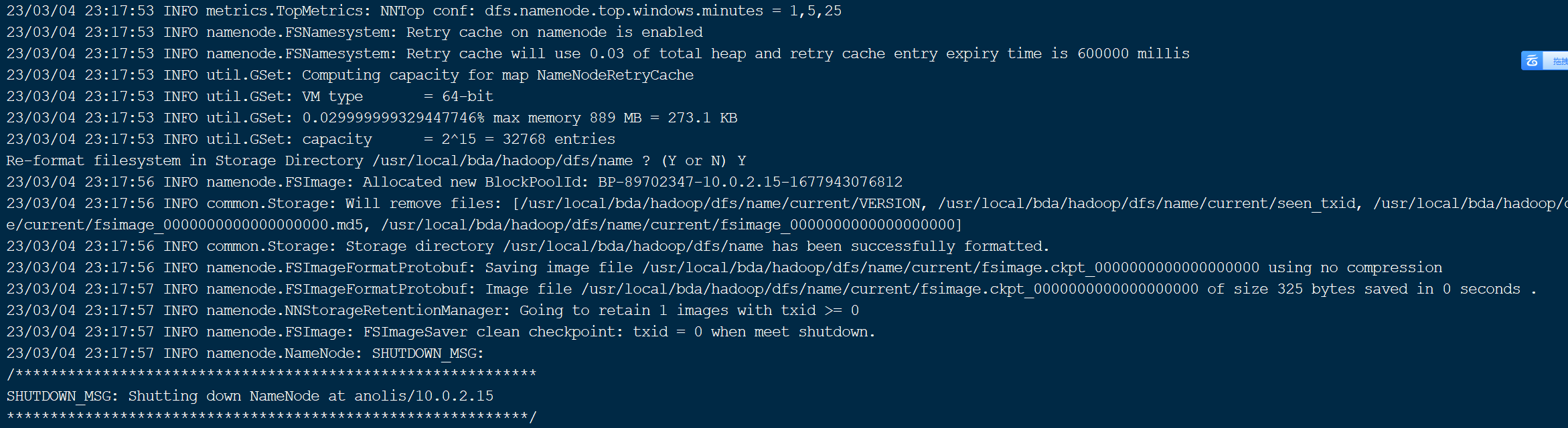
执行HDFS文件系统格式化命令后,会有较大的输出信息,可以检查是否有ERROR信息。
5.1.2. 启动HDFS服务及验证
(1) 输入如下命令,启动dfs服务
/usr/local/bda/hadoop/sbin/start-dfs.sh

需要注意的是首次启动时,需要输入yes。其后再次启动则无需输入。
(2)输入 jps 命令,查看相关进程是否正常
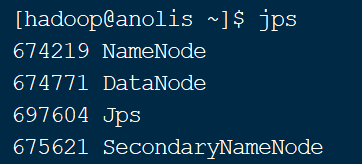
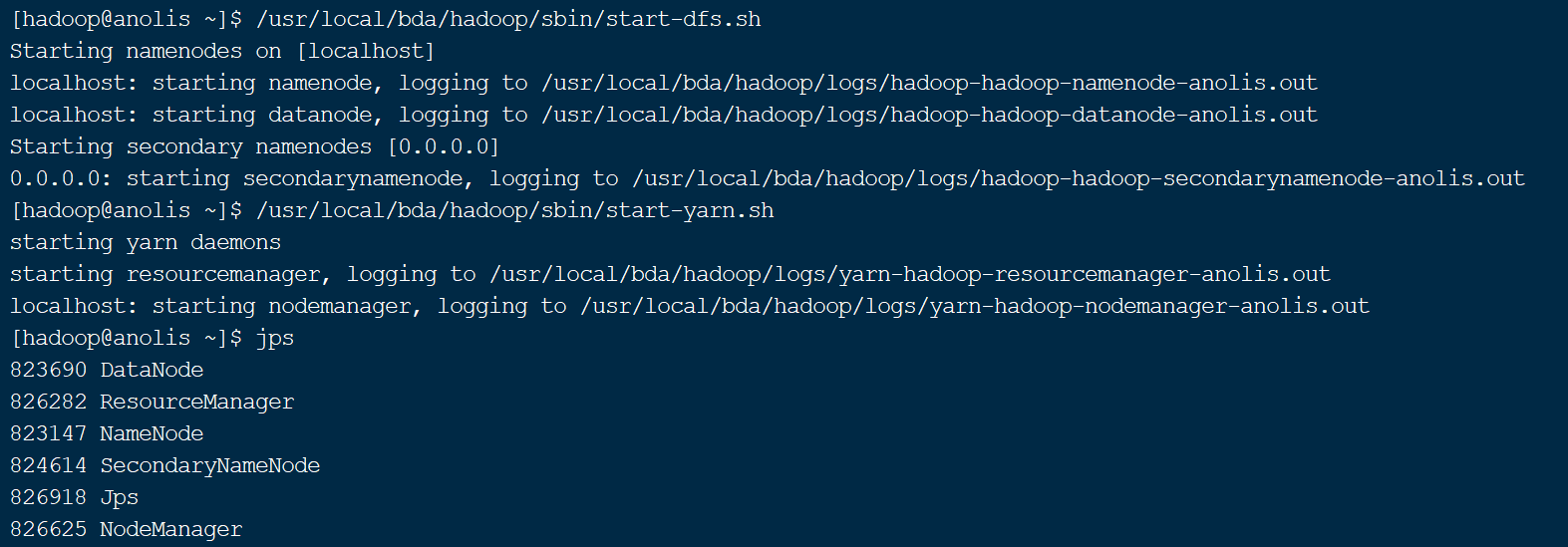
jps命令的作用是查看当前系统中正在运行的java进程。如图15所示,执行完start-dfs.sh脚本后正常情况下有3个HDFS的进程,一个是NameNode进程,一个是DataNode进程,还有一个是SecondaryNameNode进程。除此之外还有jps进程自己。
(3)访问hdfs的http服务端口
HDFS提供了http服务端口,可以通过浏览器访问,但是需要注意的是,为了访问该端口,需要在防火墙上打开该端口,或者直接关闭防火墙。
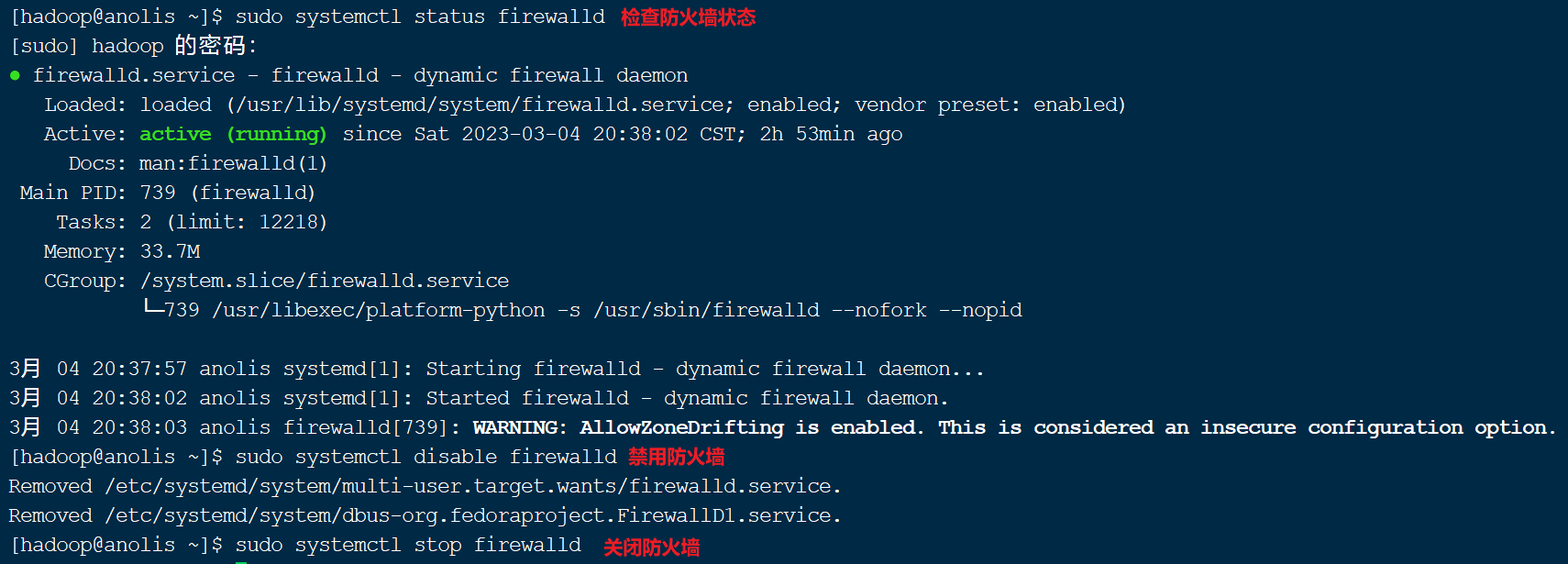
检查防火墙状态
sudo systemctl status firewalld
禁用防火墙
sudo systemctl status firewalld
关闭防火墙
sudo systemctl stop firewalld
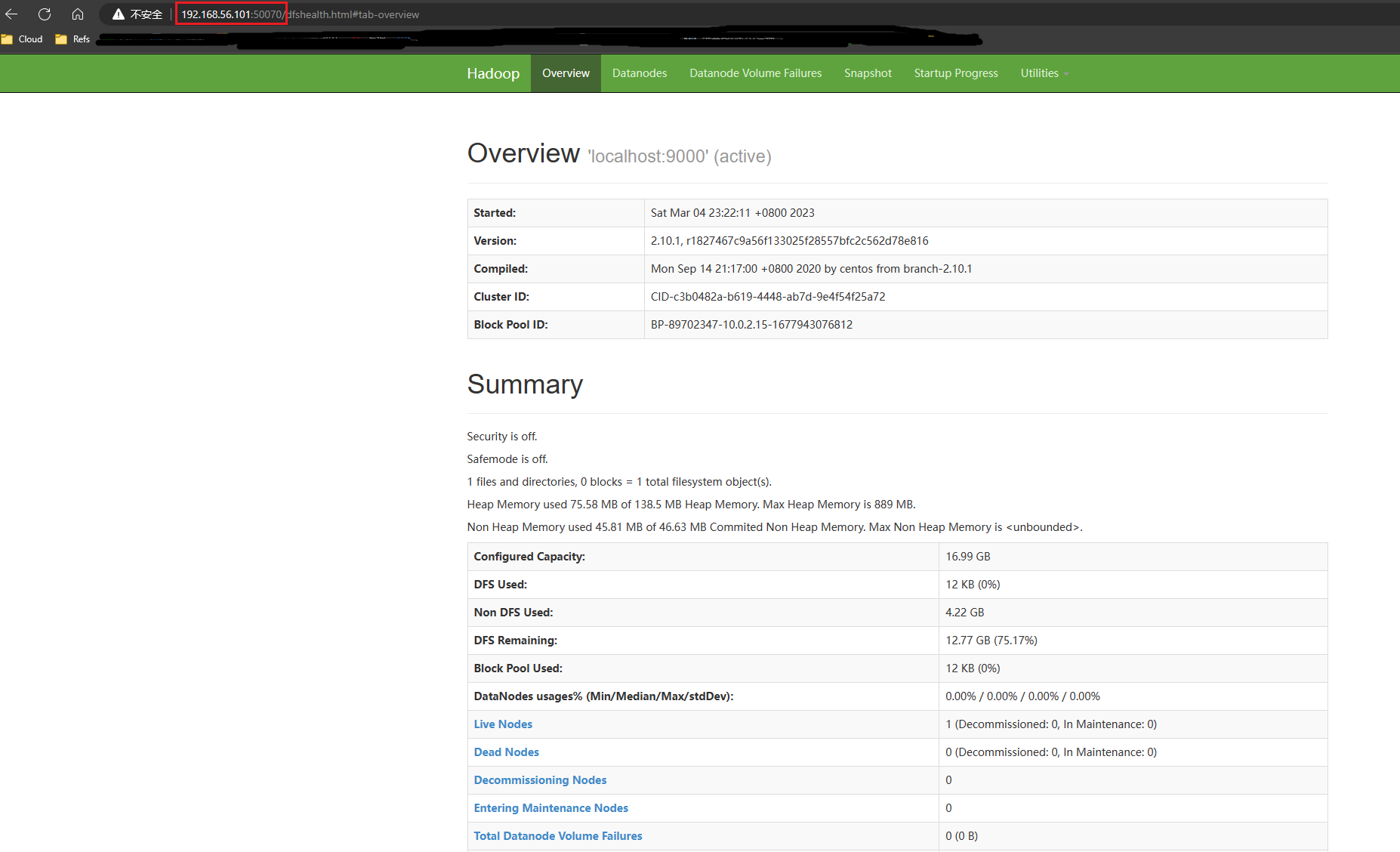
关闭防火墙端口后,就可以在windows系统打开浏览器,地址栏中输入虚拟机的“小网IP”及HDFS的http服务端口(2.x版本是50070)
5.1.3. 停止HDFS服务
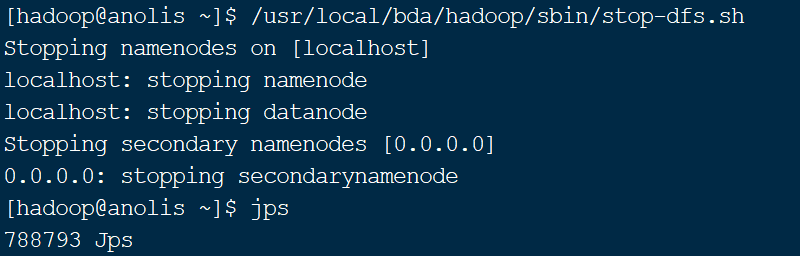
注意:在关闭服务器之前,一定要先使用stop-dfs.sh命令停止HDFS文件系统,如果不执行该命令,直接进行服务器的关机操作,则HDFS系统很容易受到损坏。
5.2.YARN服务启动及关闭
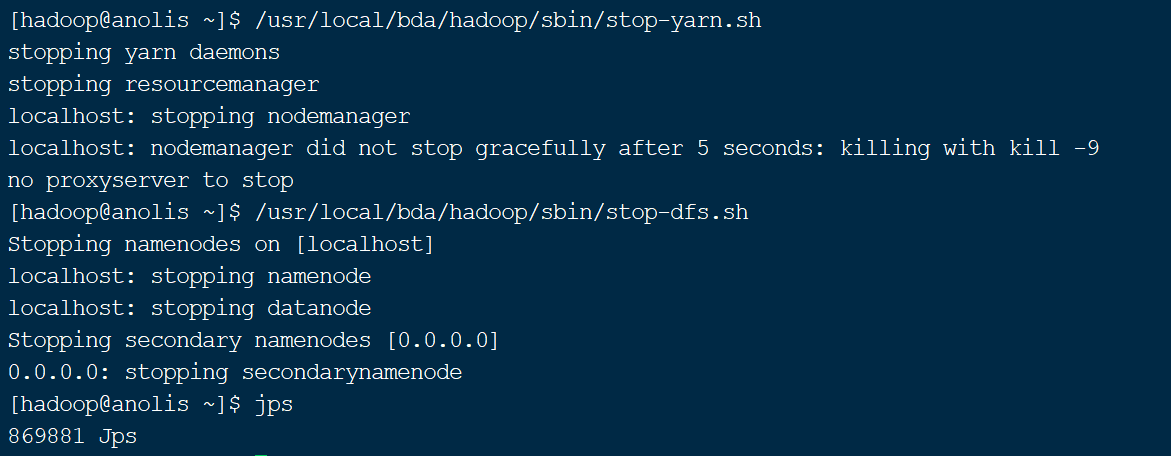
与HDFS类似,Hadoop提供了YARN服务的启动(start-yarn.sh)和关闭(stop-yarn.sh)命令。需要注意的是,YARN服务一般在HDFS服务启动后启动,并在HDFS服务关闭之前关闭。其执行顺序一般是:
start-dfs.sh →start-yarn.sh →stop-yarn.sh →stop-dfs.sh
与HDFS类似,也可以通过浏览器输入服务器的小网IP+8088端口,访问YARN的http服务,查看在执行的计算任务及系统资源情况(需要打开防火墙端口,或者关闭防火墙)
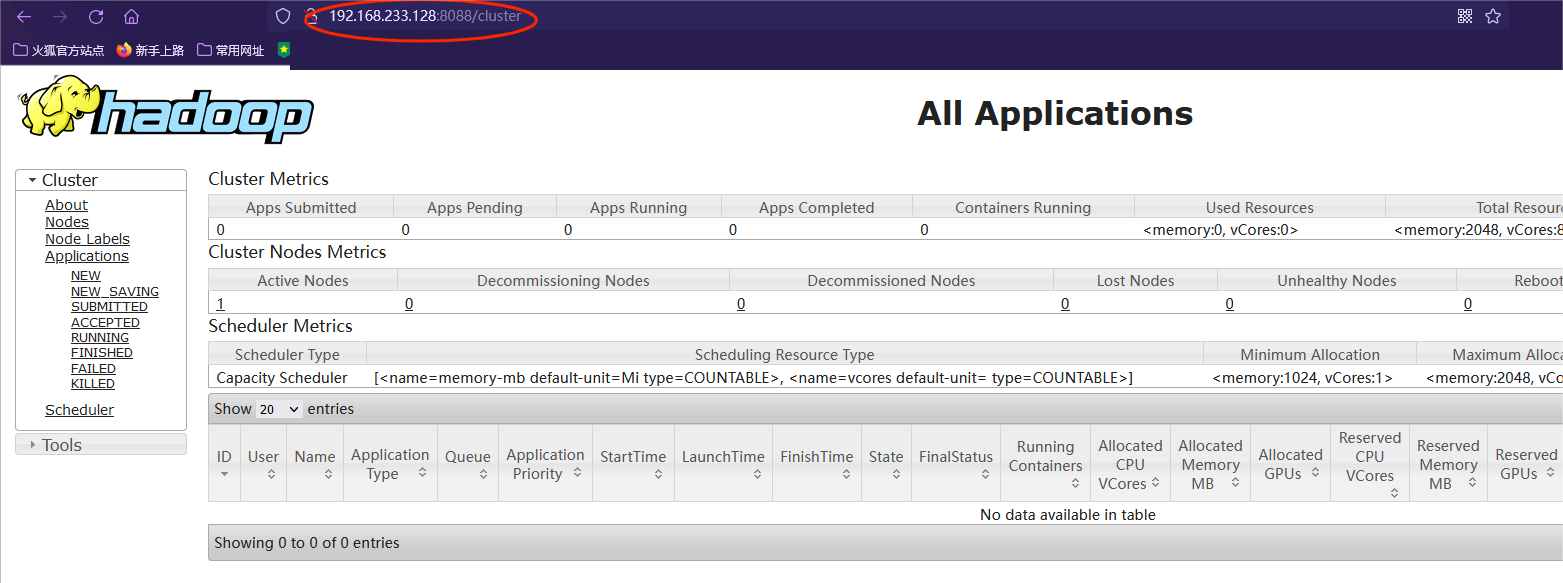
(注:请各位大佬手下留情,有不足的地方请指出!!)
Hadoop环境安装与配置的更多相关文章
- hadoop环境安装及简单Map-Reduce示例
说明:这篇博客来自我的csdn博客,http://blog.csdn.net/lxxgreat/article/details/7753511 一.参考书:<hadoop权威指南--第二版(中文 ...
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- Ubuntu下伪分布式模式Hadoop的安装及配置
1.Hadoop运行模式Hadoop有三种运行模式,分别如下:单机(非分布式)模式伪分布式(用不同进程模仿分布式运行中的各类节点)模式完全分布式模式注:前两种可以在单机运行,最后一种用于真实的集群环境 ...
- Hadoop(2)-CentOS下的jdk和hadoop的安装与配置
准备工作 下载jdk8和hadoop2.7.2 使用sftp的方式传到hadoop100上的/opt/software目录中 配置环境 如果安装虚拟机时选择了open java,请先卸载 rpm -q ...
- Linux中Hadoop的安装与配置
一.准备 1,配通网络 ping www.baidu.com 之前安装虚拟机时配过 2,关闭防火墙 systemctl stop firewalld systemctl disable firewal ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- 【Cloud Computing】Hadoop环境安装、基本命令及MapReduce字数统计程序
[Cloud Computing]Hadoop环境安装.基本命令及MapReduce字数统计程序 1.虚拟机准备 1.1 模板机器配置 1.1.1 主机配置 IP地址:在学校校园网Wifi下连接下 V ...
- 第1章 开发环境安装和配置(二)安装JDK、SDK、NDK
原文 第1章 开发环境安装和配置(二)安装JDK.SDK.NDK 无论是用C#和VS2015开发Androd App还是用Java和Eclipse开发Androd App,都需要先安装JDK和Andr ...
- Nginx+Python+uwsgi+Django的web开发环境安装及配置
Nginx+Python+uwsgi+Django的web开发环境安装及配置 nginx安装 nginx的安装这里就略过了... python安装 通常系统已经自带了,这里也略过 uwsgi安装 官网 ...
- RabbitMQ消息队列之一:RabbitMQ的环境安装及配置
RabbitMQ简介: MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们 ...
随机推荐
- SICP:惰性求值、流和尾递归(Python实现)
求值器完整实现代码我已经上传到了GitHub仓库:TinySCM,感兴趣的童鞋可以前往查看.这里顺便强烈推荐UC Berkeley的同名课程CS 61A. 即使在变化中,它也丝毫未变. --赫拉克利特 ...
- HNU2019 Summer Training 3 E. Blurred Pictures
E. Blurred Pictures time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- INFINI Labs 产品更新 | Console 新增数据比对、新增数据看板表格组件及支持下钻功能等
INFINI Labs 产品更新啦~,本次产品版本更新包括 Gateway v1.14.0.Console v1.2.0.Easysearch v1.1.1 等,其中 Console 在上一版基础上做 ...
- 代码随想录算法训练营Day53 动态规划
代码随想录算法训练营 代码随想录算法训练营Day53 动态规划|● 1143.最长公共子序列 1035.不相交的线 53. 最大子序和 动态规划 1143.最长公共子序列 题目链接:1143.最长公 ...
- Unity框架与.NET, Mono框架的关系
什么是C# C#是一种面向对象的编程语言. 什么是.NET .NET是一个开发框架,它遵循并采用CIL(Common Intermediate Language)和CLR(Common Languag ...
- VLAN——提高网络性能、安全性和灵活性的利器
前言 VLAN是Virtual Local Area Network的缩写,它是一种通过网络交换机虚拟划分局域网的技术.VLAN可以将一个物理局域网划分成多个逻辑上的虚拟局域网,各个虚拟局域网之间相互 ...
- StencilJs学习之事件
其实并没有所谓的 stencil Event,相反 stencil 鼓励使用 DOM event.然而,Stencil 提供了一个 API 来指定组件可以触发的事件,以及组件监听的事件. 这是通过 E ...
- 前端vue自定义简单实用下拉筛选 下拉菜单
前端vue自定义简单实用下拉筛选 下拉菜单, 下载完整代码请访问: https://ext.dcloud.net.cn/plugin?id=13020 效果图如下: #### 使用方法 ``` ...
- 通信原理知识点总结(XDU网信通原)
因为感觉第2章和第7章内容特别乱,当时老师讲的时候好像也没有按照一个正确的顺序来讲,所以我就把这两部分的内容按照结构顺序整理了一下,这样更便于理解和记忆 第2章 无线信道传输特性 显示不全点链接看完整 ...
- 从逻辑门到 CPU
目的,造一个很简单的,概念上的 CPU,虽然简单,但是是五脏俱全的 CPU 从最基础的逻辑门开始造,零基础可以看 制造基本武器:与门.非门.或门 现在计算机都是二进制,那二进制是一开始就能想到的吗?显 ...