详解MRS HBase全局二级索引
本文分享自华为云社区《MRS HBase全局二级索引原理与使用场景》,作者:学习一下大数据 。
一、HBase二级索引背景介绍
HBase是基于Key-Value的分布式存储数据库,对表中的数据按照rowkey的字典进行排序;当已知要查询的数据rowkey或其范围,可以快速查找到需要读取的数据;HBase提供Filter功能来查询具有特定列值的数据,当无法确定rowkey范围时,条件查询会劣化为全表查询,表数据量较大的场景下,查询容易超时,无法满足查询时延要求。
与结构化数据库(例如MySQL)相似,HBase二级索引就是为了提升此类条件查询场景性能:查询条件无法精确/模糊匹配rowkey(类似于DB主键),同时严格要求查询时延。
二、MRS HBase二级索引原理
用户可以将定义经常查询的列定义为索引列,通过冗余存储索引列数据以达到加速查询的效果,将时间不可控的全表条件查询转换为区间条件查询,从而做到查询低时延。
MRS提供两种HBase二级索引:本地索引(HIndex)和 全局索引(GSI);两者的区别是:
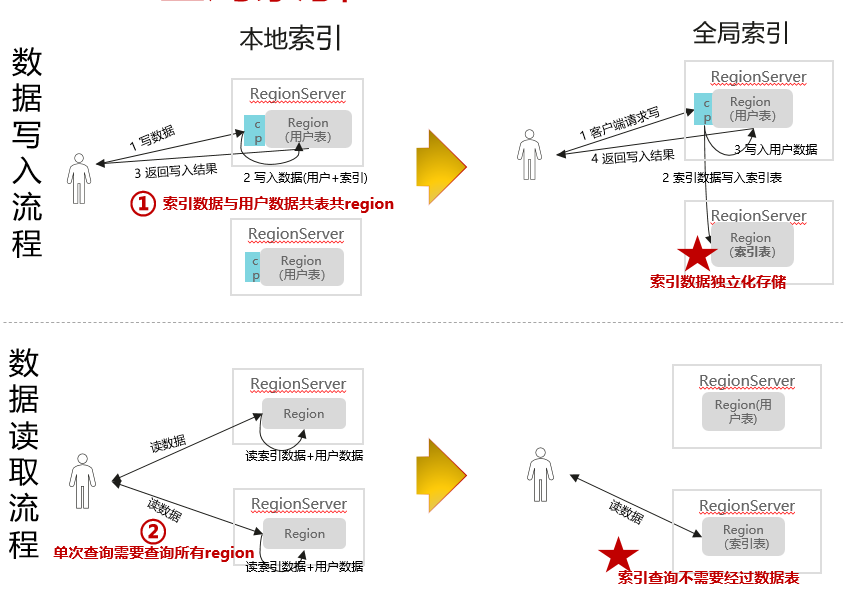

- 索引数据存储方式:本地索引存储索引数据到用户表的一个单独的列族中,全局索引存储到一个索引表中(索引数据独立存储)。
- 写入流程:本地索引一次性写入用户数据和索引数据,全局索引需要先后写入索引表和数据表。
- 读取流程:本地索引需要读取所有region的索引+用户数据,全局索引读取索引表(覆盖查询列场景下,不经过数据表)或索引表+数据表。
MRS 3.x版本提供了HBase全局索引能力,相较于本地索引,具有的优势有:
- 索引数据独立存储,解耦用户数据,稳定性更优。
- 索引查询链路优化,支持覆盖列(支持全覆盖),可以将经常查询的非索引列冗余存储到索引表,避免从原表获取数据,同时减少了查询过程中内部的RPC操作,在大规模数据场景下,查询性能更优。
此外,全局索引还提供以下工具,用于索引的维护:
- 索引创建/删除/状态修改工具
- 索引数据批量构建工具
- 索引数据一致性校验工具
三、MRS 全局二级索引使用场景
全局二级索引适用于以下场景:
- 经常使用固定条件(非rowkey)查询
- 查询时延有严格要求
- 用户表的数据量较大(region数量较多)
- 读多写少,对写入时延无严格要求(为保障索引数据一致性,全局索引采用分阶段式写入的方式,写入时延会有一定上升)
全局二级索引同时需要考虑,预留足够存储空间给索引表,索引数量/覆盖列/索引列越多,需要的空间越大,极限场景(全覆盖)下,与数据表大小相当。
四、MRS HBase全局二级设计与实战
基于HBase全局二级索引查询时,并非所有查询都能命中索引进行加速(HBase全局二级索引的使用规范详见用户手册),想要利用好索引功能,必须根据查询条件设计好索引。
以下实例展示了城市地点人流量统计功能实现,包括索引设计、查询条件等。
数据表定义
create 'city','cf',{SPLITS=>['0','1','2','3','4','5']}
rowkey定义:数据id(随机数字id,用于离散数据)

索引定义
索引名:idx_vn_time
索引字段:cf:visitors_nums+cf:time
覆盖列:全覆盖
该索引用于筛选人流量较大的地区信息
数据表查询对比
预置数据:10MB,预分区11个region,HBase集群节点3个
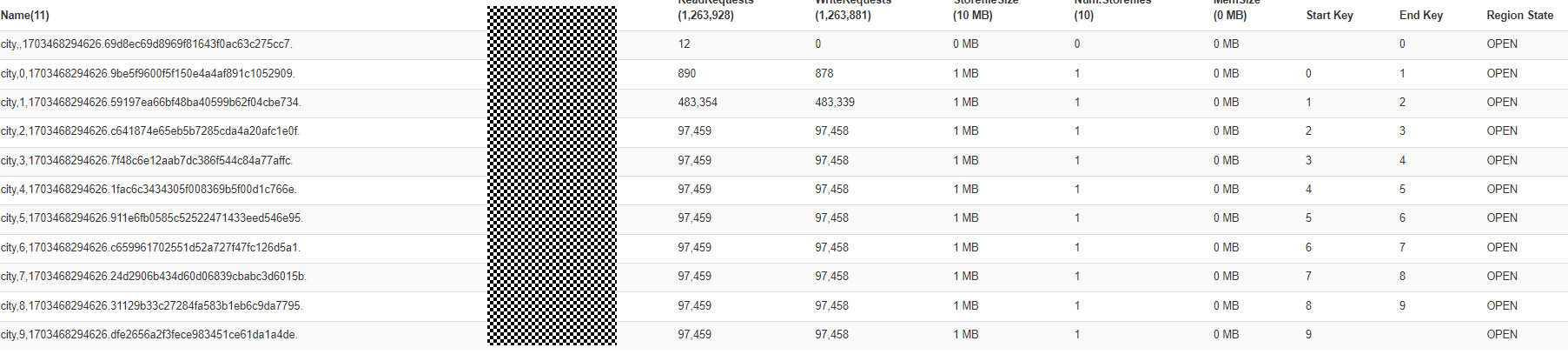
查询条件1:查询人流量大于9000的地区信息
scan 'city',{COLUMN=>'cf', FILTER=>"SingleColumnValueFilter('cf','visitors_nums',>=,'binary:9000')"}
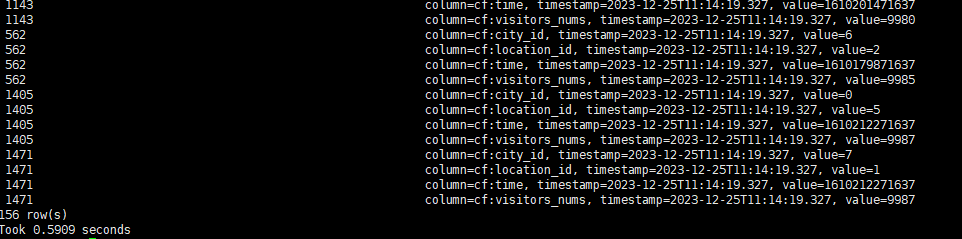
禁用索引后再次查询
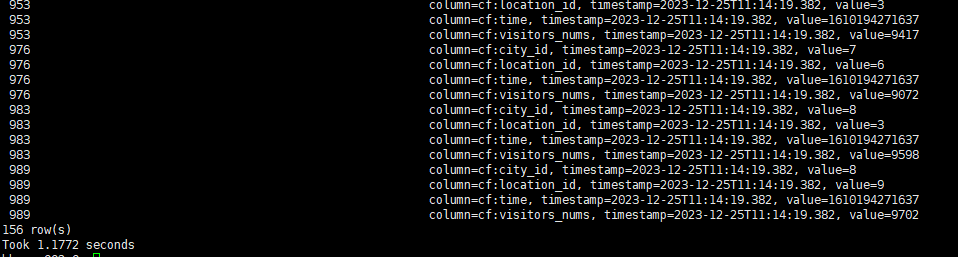
查询条件2:查询2021-01-10 0点-12点,人流量大于9000的地区信息
scan 'city',{COLUMN=>'cf', FILTER=>"SingleColumnValueFilter('cf','visitors_nums',>=,'binary:9000') AND SingleColumnValueFilter('cf','time',>=,'binary:1610208000000') AND SingleColumnValueFilter('cf','time',<,'binary:1610251200000')"}
禁用索引后再次查询
可以看到,命中索引时,查询效率提升十分明显,即使在小表上,也能获得数倍的性能提升。
注:命中索引后的查询结果按索引定义排序
详解MRS HBase全局二级索引的更多相关文章
- HBase详解(05) - HBase优化 整合Phoenix 集成Hive
HBase详解(05) - HBase优化 整合Phoenix 集成Hive HBase优化 预分区 每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维 ...
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- 085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来 1.举例 有A列与B列,分别是年龄与姓名. 如果想通过年龄查询姓名. 正常的检索是通过rowkey进行检索. 根据年龄查询rowkey,然后根据rowkey进行查找姓名. 这样的效率不高 ...
- HBase建立二级索引的一些解决方式
HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索. 假设我们相对hbase里面列族的列列进行一些组合查询.就须要採用HBase的二级索引方案来进行多条件的查询. 常见的二级索引 ...
- HBase详解(04) - HBase Java API使用
HBase详解(04) - HBase Java API使用 环境准备 新建Maven项目,在pom.xml中添加依赖 <dependency> <groupId>org.ap ...
- 大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)
1. ZK的监控机制 1.1 监听数据的变化 (1)监听一次 public class ChangeDataWacher { public static void main(String[] arg ...
- 基于Solr实现HBase的二级索引
文章来源:http://www.open-open.com/lib/view/open1421501717312.html 实现目的: 由于hbase基于行健有序存储,在查询时使用行健十分高效,然后想 ...
- hbase coprocessor 二级索引
Coprocessor方式二级索引 1. Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据.通常我们使用get或者scan来从Hbase中获取数 ...
- elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
一.快速入门 1. 查看集群的健康状况 http://localhost:9200/_cat http://localhost:9200/_cat/health?v 说明:v是用来要求在结果中返回表头 ...
- [How to] MapReduce on HBase ----- 简单二级索引的实现
1.简介 MapReduce计算框架是二代hadoop的YARN一部分,能够提供大数据量的平行批处理.MR只提供了基本的计算方法,之所以能够使用在不用的数据格式上包括HBase表上是因为特定格式上的数 ...
随机推荐
- MySQL快速导入千万条数据(1)
目录 一.命令行导入方式 二.LOAD DATA导入方式 对于传统的关系数据库如oracle,在大量数据导入方面的效率,我们一般有一个大概的认知,即1分钟以内可以导入千万条数据,而对于MySQL数据库 ...
- 实现脚本自动部署docker
前言: 使用场景是 我这边的一个单体项目需要多一个多副本的部署方式,一直输入重复命令我实在是嫌烦了,使用写了一个脚本来一键更新部署上去.jar包都是我手动上传的,没有把包传入公网库里. 之所以记录就是 ...
- CF1526C2
与简单版的思路完全一致,只需要改一下范围. 可以去看我简单版本的博客. 题目简化和分析: 给您一个数组,在其中选择若干个数使得: 任意前缀和 \(\ge 0\) 数量尽可能的大 我们可以使用贪心策略, ...
- Util应用框架Web Api开发快速入门
本文是使用Util应用框架开发 Web Api 项目快速入门教程. 前面已经详细介绍了环境搭建,如果你还未准备好,请参考前文. 开发流程概述 创建代码生成专用数据库. Util应用框架需要专门用来生成 ...
- centos7安装node-v18版本真是难呢
背景 背景就是上一篇文章提到的,部署gitbook这个文档中心的话,是需要先安装node,然后,如果你的node版本过高的话,一般会报错,此时,网上很多文章就是降node版本解决,但其实用高版本也是有 ...
- 拒绝恶意IP登录服务器
拒绝恶意IP登录服务器,并加入防火墙黑名单 #!/bin/bash #2020-03-20 16:39 #auto refuse ip dlu #By Precious ############### ...
- 实战攻防演练-Linux写入ssh密钥,利用密钥登录
前言 密钥形式登录的原理是利用密钥生成器制作一对密钥,一只公钥和一只私钥.将公钥添加到服务器的某个账户上,然后在客户端利用私钥即可完成认证并登录.这样一来,没有私钥,任何人都无法通过 SSH 暴力破解 ...
- CSS 也能实现 if 判断?实现动态高度下的不同样式展现
最近在群里,有个小伙伴问了这么一道很有趣的问题: CSS 能否实现,容器再某个高度下是某种表现,一旦超出某个高度,则额外展示另外一些内容 为了简化实际效果,我们看这么一张示意效果图: 可以看到,当容器 ...
- JAVA中的函数接口,你都用过吗
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 在这篇文章中,我们将通过示例来学习 Java 函数式接口. 函数式接口的特点 只包含一个抽象方法的接口称为函数式接口. 它 ...
- 文心一言 VS 讯飞星火 VS chatgpt (140)-- 算法导论11.4 5题
五.用go语言,考虑一个装载因子为a的开放寻址散列表.找出一个非零的a值,使得一次不成功查找的探查期望数是一次成功查找的探查期望数的 2 倍.这两个探查期望数可以使用定理11.6 和定理 11.8 中 ...