MRS离线数据分析:通过Flink作业处理OBS数据
摘要:MRS支持在大数据存储容量大、计算资源需要弹性扩展的场景下,用户将数据存储在OBS服务中,使用MRS集群仅做数据计算处理的存算分离模式。
本文分享自华为云社区《【云小课】EI第47课 MRS离线数据分析-通过Flink作业处理OBS数据》,作者:Hello EI 。
MRS支持在大数据存储容量大、计算资源需要弹性扩展的场景下,用户将数据存储在OBS服务中,使用MRS集群仅做数据计算处理的存算分离模式。
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。
本文将向您介绍如何在MRS集群中运行Flink作业来处理OBS中存储的数据。

Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级,且兼具可靠性。

在本示例中,我们使用MRS集群内置的Flink WordCount作业程序,来分析OBS文件系统中保存的源数据,以统计源数据中的单词出现次数。
当然您也可以获取MRS服务样例代码工程,参考Flink开发指南开发其他Flink流作业程序。
本案例基本操作流程如下所示:
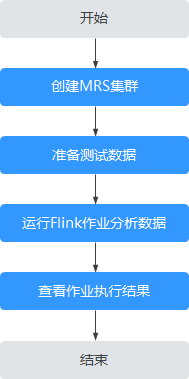
创建MRS集群
创建并购买一个包含有Flink组件的MRS集群,详情请参见购买自定义集群。
本文以购买MRS 3.1.0版本的集群为例,集群未开启Kerberos认证。
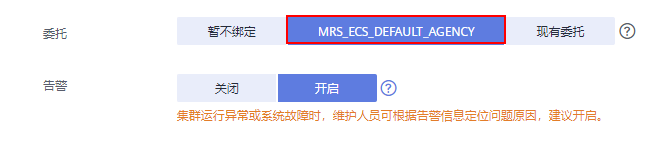
在本示例中,由于我们要分析处理OBS文件系统中的数据,因此在集群的高级配置参数中要为MRS集群绑定IAM权限委托,使得集群内组件能够对接OBS并具有对应文件系统目录的操作权限。
您可以直接选择系统默认的“MRS_ECS_DEFAULT_AGENCY”,也可以自行创建其他具有OBS文件系统操作权限的自定义委托。
集群购买成功后,在MRS集群的任一节点内,使用omm用户安装集群客户端,具体操作可参考安装并使用集群客户端。
例如客户端安装目录为“/opt/client”。
准备测试数据
在创建Flink作业进行数据分析前,我们需要在提前准备待分析的测试数据,并将该数据上传至OBS文件系统中。
1、本地创建一个“mrs_flink_test.txt”文件,例如文件内容如下:
This is a test demo for MRS Flink. Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing.
2、在云服务列表中选择“存储 > 对象存储服务”,登录OBS管理控制台。
3、单击“并行文件系统”,创建一个并行文件系统,并上传测试数据文件。

例如创建的文件系统名称为“mrs-demo-data”,单击系统名称,在“文件”页面中,新建一个文件夹“flink”,上传测试数据至该目录中。
则本示例的测试数据完整路径为“obs://mrs-demo-data/flink/mrs_flink_test.txt”。

4、上传数据分析应用程序。
使用管理台界面直接提交作业时,将已开发好的Flink应用程序jar文件也可以上传至OBS文件系统中,或者MRS集群内的HDFS文件系统中。
本示例中我们使用MRS集群内置的Flink WordCount样例程序,可从MRS集群的客户端安装目录中获取,即“/opt/client/Flink/flink/examples/batch/WordCount.jar”。
将“WordCount.jar”上传至“mrs-demo-data/program”目录下。
创建并运行Flink作业
方式1:在控制台界面在线提交作业。
- 登录MRS管理控制台,单击MRS集群名称,进入集群详情页面。
- 在集群详情页的“概览”页签,单击“IAM用户同步”右侧的“单击同步”进行IAM用户同步。
- 单击“作业管理”,进入“作业管理”页签。
- 单击“添加”,添加一个Flink作业。
- 作业类型:Flink
- 作业名称:自定义,例如flink_obs_test。
- 执行程序路径:本示例使用Flink客户端的WordCount程序为例。
- 运行程序参数:使用默认值。
- 执行程序参数:设置应用程序的输入参数,“input”为待分析的测试数据,“output”为结果输出文件。
例如本示例中,我们设置为“--input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo-data/flink/output”。
- 服务配置参数:使用默认值即可,如需手动配置作业相关参数,可参考运行Flink作业。
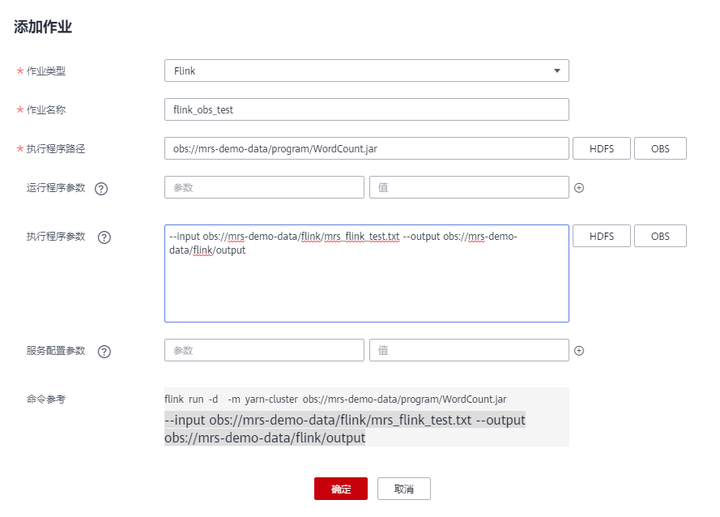
5.确认作业配置信息后,单击“确定”,完成作业的新增,并等待运行完成。

方式2:通过集群客户端提交作业。
1、使用root用户登录集群客户端节点,进入客户端安装目录。
su - omm
cd /opt/client
source bigdata_env
2、执行以下命令验证集群是否可以访问OBS。
hdfs dfs -ls obs://mrs-demo-data/flink
3、提交Flink作业,指定源文件数据进行消费。
flink run -m yarn-cluster /opt/client/Flink/flink/examples/batch/WordCount.jar --input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo/data/flink/output2
执行后结果类似如下:
...
Cluster started: Yarn cluster with application id application_1654672374562_0011
Job has been submitted with JobID a89b561de5d0298cb2ba01fbc30338bc
Program execution finished
Job with JobID a89b561de5d0298cb2ba01fbc30338bc has finished.
Job Runtime: 1200 ms
查看作业执行结果
- 作业提交成功后,登录MRS集群的FusionInsight Manager界面,选择“集群 > 服务 > Yarn”。
- 单击“ResourceManager WebUI”后的链接进入Yarn Web UI界面,在Applications页面查看当前Yarn作业的详细运行情况及运行日志。

3.等待作业运行完成后,在OBS文件系统中指定的结果输出文件中可查看数据分析输出的结果。

下载“output”文件到本地并打开,可查看输出的分析结果。
a 3
and 2
batch 1
both 1
computing 2
data 2
demo 1
distribution 1
engine 1
flink 2
for 1
framework 1
is 2
it 1
mrs 1
parallel 1
processing 3
provides 1
stream 2
supports 2
test 1
that 2
this 1
unified 1
使用集群客户端命令行提交作业时,若不指定输出目录,在作业运行界面也可直接查看数据分析结果。
Job with JobID xxx has finished.
Job Runtime: xxx ms
Accumulator Results:
- e6209f96ffa423974f8c7043821814e9 (java.util.ArrayList) [31 elements] (a,3)
(and,2)
(batch,1)
(both,1)
(computing,2)
(data,2)
(demo,1)
(distribution,1)
(engine,1)
(flink,2)
(for,1)
(framework,1)
(is,2)
(it,1)
(mrs,1)
(parallel,1)
(processing,3)
(provides,1)
(stream,2)
(supports,2)
(test,1)
(that,2)
(this,1)
(unified,1)
MRS离线数据分析:通过Flink作业处理OBS数据的更多相关文章
- 基于EMR离线数据分析-反馈有礼
"云上漫步"第三期-反馈有礼 参与体验产品,提交反馈,就有机会获得定制背包,T恤,超萌虎年鼠标垫,以及5到100元阿里云通用代金券~ 反馈地址: https://developer ...
- ETL项目2:大数据清洗,处理:使用MapReduce进行离线数据分析并报表显示完整项目
ETL项目2:大数据清洗,处理:使用MapReduce进行离线数据分析并报表显示完整项目 思路同我之前的博客的思路 https://www.cnblogs.com/symkmk123/p/101974 ...
- ETL项目1:大数据采集,清洗,处理:使用MapReduce进行离线数据分析完整项目
ETL项目1:大数据采集,清洗,处理:使用MapReduce进行离线数据分析完整项目 思路分析: 1.1 log日志生成 用curl模拟请求,nginx反向代理80端口来生成日志. #! /bin/b ...
- Flink消费Kafka数据并把实时计算的结果导入到Redis
1. 完成的场景 在很多大数据场景下,要求数据形成数据流的形式进行计算和存储.上篇博客介绍了Flink消费Kafka数据实现Wordcount计算,这篇博客需要完成的是将实时计算的结果写到redis. ...
- 使用Flink实现索引数据到Elasticsearch
使用Flink实现索引数据到Elasticsearch 2018-07-28 23:16:36 Yanjun 使用Flink处理数据时,可以基于Flink提供的批式处理(Batch Proce ...
- R语言数据分析利器data.table包—数据框结构处理精讲
R语言数据分析利器data.table包-数据框结构处理精讲 R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代 ...
- flink 处理实时数据的三重保障
flink 处理实时数据的三重保障 window+watermark 来处理乱序数据对于 TumblingEventTimeWindows window 的元数据startTime,endTime 和 ...
- [数据分析与可视化] Python绘制数据地图2-GeoPandas地图可视化
本文主要介绍GeoPandas结合matplotlib实现地图的基础可视化.GeoPandas是一个Python开源项目,旨在提供丰富而简单的地理空间数据处理接口.GeoPandas扩展了Pandas ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 【Python数据分析】从Web收集数据小实例
最近在看<鲜活的数据:数据可视化指南>,学习一些数据可视化与数据分析的技术,本例是该书第一章的一个例子衍伸而来. 实例内容:从www.wunderground.com收集美国纽约州布法罗市 ...
随机推荐
- Python 环境迁移
平时用python环境会装一堆依赖,也包括自己的模块,要迁移到陌生环境,得好好处理才行. 下面介绍个方法,实践过还可以: 总结下步骤: miniconda或conda安装一个python环境,pyth ...
- Godot引擎的一些踩坑记录(不断更新中)
版本号 Godot 3.1.2 文件夹名称使用小写.编译\导出时有的tscn文件的引用路径, 有可能会变成小写路径(怀疑是bug),导致启动失败. ttc字体(文泉驿微米黑)导出时需要手动设置包含*. ...
- 🎊OpenTiny Vue 3.11.0 发布:增加富文本、ColorPicker等4个新组件,迎来了贡献者大爆发!
你好,我是 Kagol. 非常高兴跟大家宣布,2023年10月24日,OpenTiny Vue 发布了 v3.11.0 . OpenTiny 每次大版本发布,都会给大家带来一些实用的新特性,8.14 ...
- Neural Networks投稿要求总结
自用,NN投稿要求,相关的部分的中文版翻译,原文链接:https://www.sciencedirect.com/journal/neural-networks/publish/guide-for-a ...
- js朗读实现
js 利用window实现朗读功能 ` 发音
- Educational Codeforces Round 101 (Rated for Div. 2) E - A Bit Similar
题目传送门 很巧妙的一道题.对于一个 \(n\)位的 \(01\)字符串,一共有 \(2^n\)种不同字符排列,对于任意一个固定排列,在 \(2^n\)种排列中只有一种排列与该固定排列处处不等,而题干 ...
- windows 电脑 连接蓝牙耳机没有麦克风
前言 windows 电脑 连接蓝牙耳机没有麦克风,明明已经显示麦克风图标,为什么录制不到声音 原因 电脑连蓝牙耳机有两个模式:hand free和stereo.handfree是可以语音通话的,但是 ...
- 解决Tensorflow2.0出现:AttributeError: module 'tensorflow' has no attribute 'get_default_graph'的问题
问题描述 在使用tensorflow2.0时,遇到了这个问题: AttributeError: module 'tensorflow' has no attribute 'get_default_gr ...
- PTA数组及排序查找题解与解题思路
PTA数组及排序查找题解与解题思路 函数题目 函数题目为平台提供的裁判程序调用所完成的函数进行判题,题目规定语言为C语言 6-1 求出二维数组的最大元素及其所在的坐标 本题较为简单,考察的是如何遍历一 ...
- 流媒体服务器ZLMediaKit与FFmpeg
流媒体服务器ZLMediaKit与FFmpeg overview 关键字:ZLMediaKit.FFmpeg.srt.vlc 如果想快速拥有自己的流媒体服务器,那么可以使用开源项目自己搭建.开源的流媒 ...