[转帖]kafka搭建kraft集群模式
kafka2.8之后不适用zookeeper进行leader选举,使用自己的controller进行选举
1.准备工作
准备三台服务器 192.168.3.110 192.168.3.111 192.168.3.112,三台服务器都要先安装好jdk1.8,配置好环境变量, 下载好kafka3.0.0二进制压缩包
解压后进入conf/kraft目录下,修改server.properties文件

2.修改配置文件
先修改110节点,主要修改下面的几个参数 node.id要唯一,跟leader选举有关系
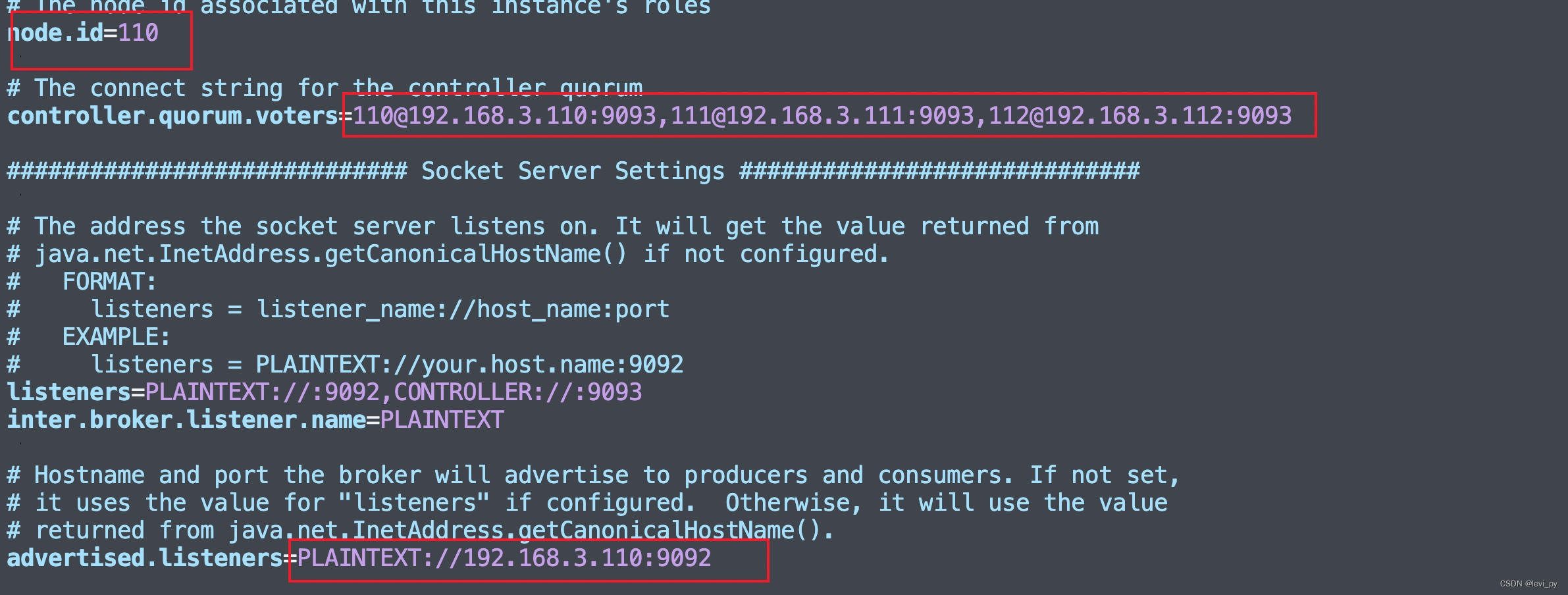
数据存储位置也要改一下
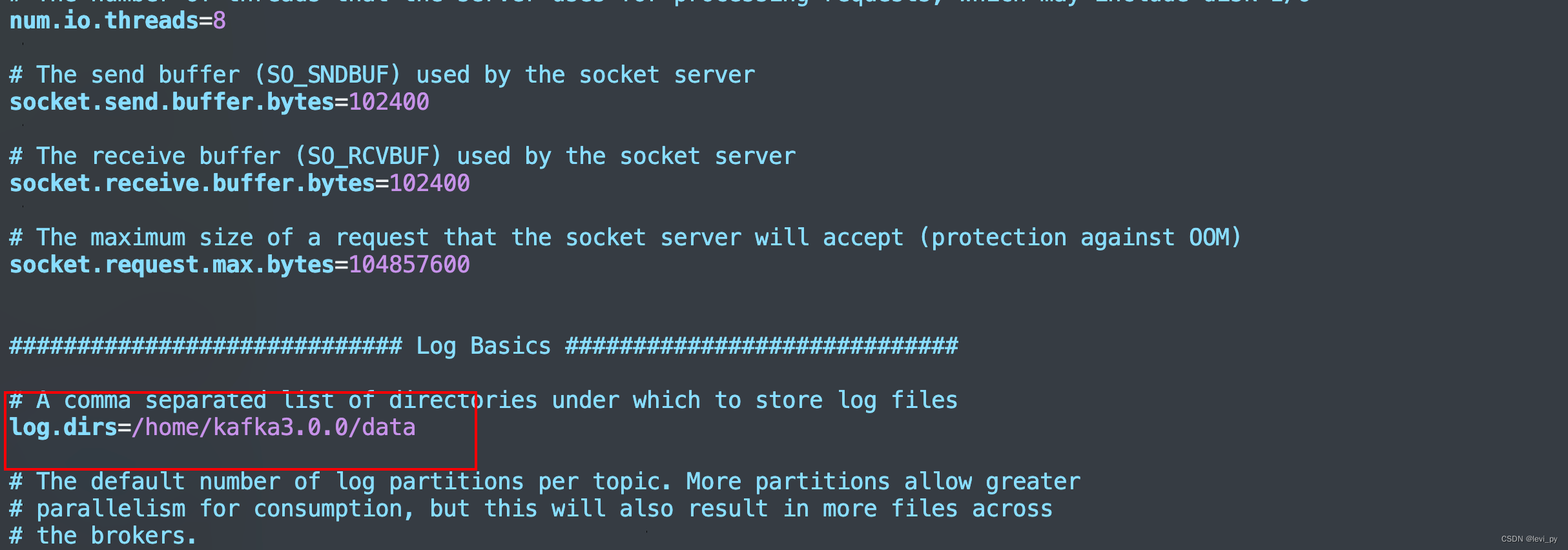
其他111和112服务器也按照改一下,把node.id改一下,ip也要改成对应的ip
3.初始化集群
在其中一台服务器上执行下面命令生成一个uuid
sh kafka3.0.0/bin/kafka-storage.sh random-uuid
- 1

用该uuid格式化kafka存储目录,三台服务器都要执行以下命令
sh kafka3.0.0/bin/kafka-storage.sh format -t 5Wr3UWh9SPGFUfX1WQlzAA -c kafka3.0.0/config/kraft/server.properties
- 1

三台服务器都启动kafka
sh kafka3.0.0/bin/kafka-server-start.sh -daemon kafka3.0.0/config/kraft/server.properties
- 1

集群启动之后,创还能一个tipic测试,在哪一台服务器上创建都行
sh kafka3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic kafka --partitions 3 --replication-factor 3
- 1

查看tipoc分区情况
sh kafka3.0.0/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe kafka
- 1

这时候把111节点kafka关掉,会重新选举,从ar里面第一个,并且在isr中存活的副本成为leader,112成为分区2的leader

[转帖]kafka搭建kraft集群模式的更多相关文章
- 10. ZooKeeper之搭建伪集群模式。
转自:https://blog.csdn.net/en_joker/article/details/78673456 在集群和单机两种模式下,我们基本完成了分别针对生产环境和开发环境ZooKeeper ...
- 5分钟实现用docker搭建Redis集群模式和哨兵模式
如果让你为开发.测试环境分别搭一套哨兵和集群模式的redis,你最快需要多久,或许你需要一天?2小时?事实是可以更短. 是的,你已经猜到了,用docker部署,真的只需要十几分钟. 一.准备工作 拉取 ...
- [转帖] kubeadm搭建kubernetes集群
http://www.bladewan.com/2018/01/02/kubernetes_install/ 学习中 kubernetes V1.9安装(附离线安装包和离线镜像) 2018-01-0 ...
- Spark3.0.1各种集群模式搭建
对于spark前来围观的小伙伴应该都有所了解,也是现在比较流行的计算框架,基本上是有点规模的公司标配,所以如果有时间也可以补一下短板. 简单来说Spark作为准实时大数据计算引擎,Spark的运行需要 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(三)安装spark2.2.1
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
随机推荐
- 技术解读丨目标检测之RepPoints系列算法
摘要:本文对anchor-free的目标检测RepPoints系列算法进行梳理,具体包含RepPoints, RepPoints V2, Dense RepPoints. 背景介绍 近两年来,anch ...
- 想做DBA,多租户管理你一定要知道这些
摘要:多租户为满足客户混合负载处理需求而生,通过提供两层用户机制,分层资源隔离,满足客户对计算和存储资源的自主控制需求. 本文分享自华为云社区<关于GaussDB(DWS)多租户管理,这些你一定 ...
- 在Spark Scala/Java应用中调用Python脚本,会么?
摘要:本文将介绍如何在 Spark scala 程序中调用 Python 脚本,Spark java程序调用的过程也大体相同. 本文分享自华为云社区<[Spark]如何在Spark Scala/ ...
- vue-grid-layout数据可视化图表面板优化过程所遇问题汇总
对于drag事件不熟悉的,请先阅读:<drag事件详解:html5鼠标拖动排序及resize实现方案分析及实践> 之前老项目grafana面板,如下图所示(GEM添加图表是直接到图表编辑, ...
- iOS App Store上架流程详解
很多开发者在开发完iOS APP.进行内测后,下一步就面临上架App Store,不过也有很多同学对APP上架App Store的流程不太了解,下面我们来说一下iOS APP上架App Store ...
- 注册中心 —— SpringCloud Netflix Eureka
Eureka 简介 Eureka 是一个基于 REST 的服务发现组件,SpringCloud 将它集成在其子项目 spring-cloud-netflix 中,以实现 SpringCloud 的服务 ...
- 数据存入已有Excel
import openpyxl filepath = r'.\UCB2Create_course\SuccsessCourse.xlsx' wb = openpyxl.load_workbook(fi ...
- 【django-vue】 项目上线 uuid重复问题 内网穿透 支付宝验签 nginx集群 远程连接redis 使用uwsgi启动django
目录 上节回顾 uuid重复问题 内网穿透 支付宝验签 今日内容 1 上线架构图 2 阿里云购买 3 安装git和其他依赖 4 云服务器安装mysql 5 云服务器安装redis(源码安装) 远程连接 ...
- awk 文本编辑器
1.简介 文本编辑器 非交互式的编辑器 编程语言 功能:对文本数据进行汇总和处理 是一个报告生成器 能够对数据进行排版 工作模式:行工作模式 读入一行 将整行内容存在$0里,一行等于一个记录 记录分隔 ...
- 阿里云Imagine Computing创新技术大赛正式开启!
阿里云 Imagine Computing 创新技术大赛,是由阿里云与英特尔主办,阿里云天池平台.边缘云.视频云共同承办的顶级赛事,面向个人开发者和企业的边缘云领域算法及实时音视频应用类挑战. 本次创 ...