全面升级,票据识别新纪元:合合信息TextIn多票识别2.0
- 难以试用
- 传统OCR服务中,支持私有化服务的产品往往无法在线试用,而能在线试用的产品又难以原样部署到本地。这导致在项目或业务中的不同阶段,验证OCR服务的性能和能力边界变得困难。
- 合合信息TextIn产品系列采用多端同步引擎架构,确保在线SaaS服务版本与私有化版本的引擎一致性,保障两者提供几乎一致的识别率和性能表现,让在线验证、线下部署成为可能。同时,SaaS版本和私有化版本还可以简单构成混合云架构,提供灵活的补位选择,满足复杂应用需求。
- 分类困难
- 票据识别OCR多用于报销或审核场景,但具体票据类别难以预测。传统逐票据分类方法通常针对某一票面提供单一的API接口,在高吞吐量、多票面场景下难以应对。
- 多票识别2.0经过深度优化,提供单接口调用服务,自动分类票种并返回识别结果,大幅简化用户的集成难度。用户不必过度考量业务场景,只需交给多票识别2.0,即可便捷享受高效服务。
- 显存膨胀
- 传统票据识别引擎通常采用单一票据结合单一模型的结构,基于此框架的票据识别产品开发、维护相对简单,但当用户需要一次性识别多个票据类型时,同时启动多个模型所需的显存资源将会线性叠加
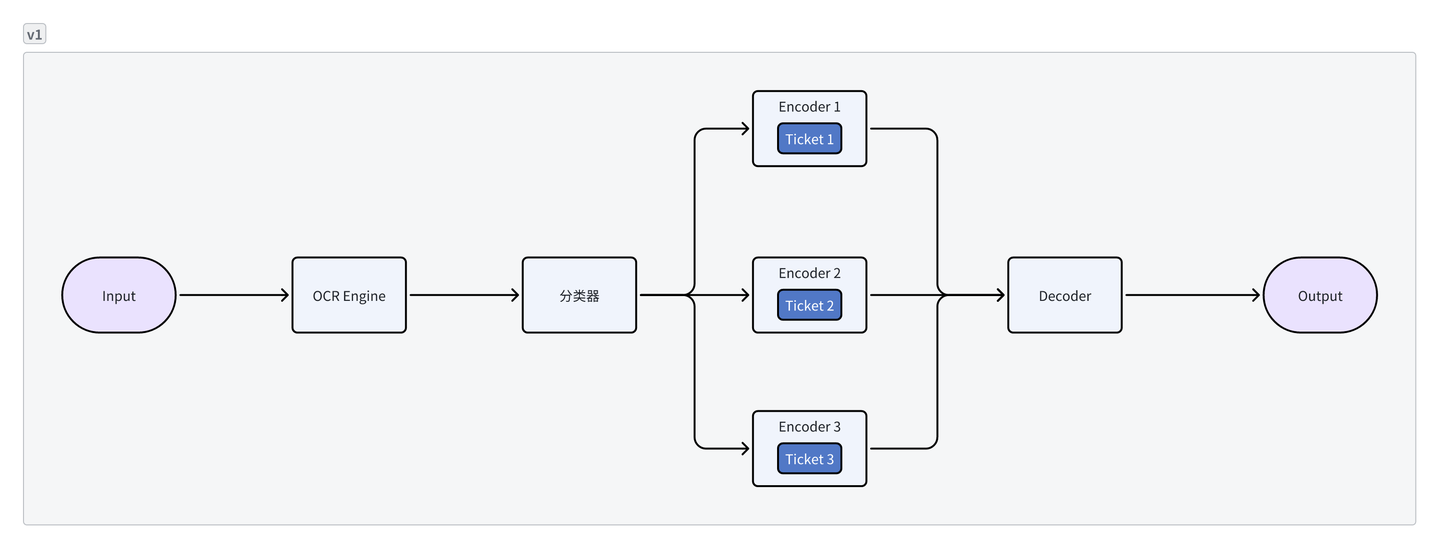
- 2.0版本使用统一主干网络结构,将多种不同票据场景统一编码并提取信息,送入票据专属的轻量级解码模块。此外,面向票据中常见的表格抽取需求,2.0版本使用统一的关系模块处理不同票据场景。相比于1.0版本,票据场景的扩增对于显存资源的需求下降两个数量级。
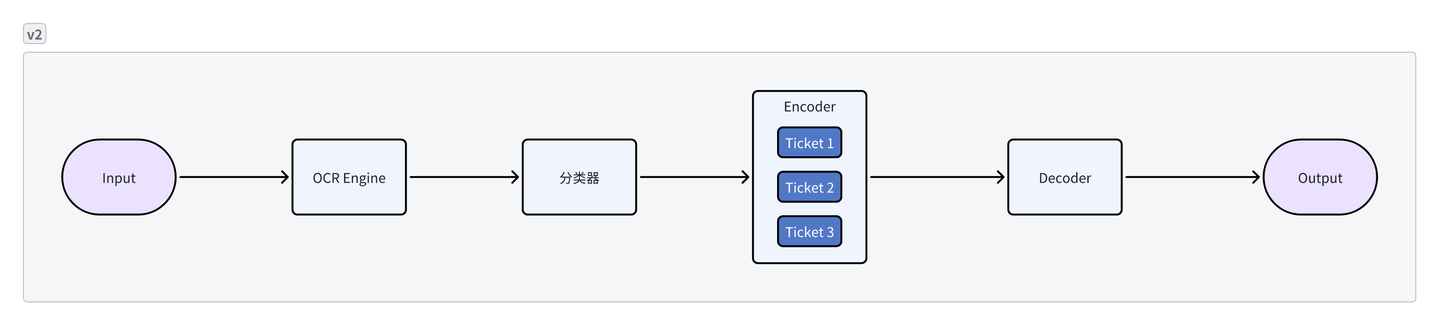
- 识别率受限
- 传统OCR票据识别一般采用规则抽取方案,先对所有字符进行识别,然后基于特定规则,匹配字符串内容,映射Key和Value。规则抽取方案在研发初期需要投入的算法工作量较低,但高度依赖预设的规则来识别和解析票据上的信息。这意味着系统必须事先知道所有可能的票据格式和内容布局,这在实际应用中往往难以实现,因为票据的格式可能会有细微的变化或定制化设计。每当票据格式发生变化时,都需要人工重新设计和调整识别规则,这不仅耗时而且成本高昂。对于一些频繁更新格式的票据,这种依赖性会导致系统维护困难。并且,由于规则是针对特定情况设计的,当遇到新的或未预见的票据格式时,系统可能无法正确识别,导致识别率下降。
- 更新后的票据识别2.0采用模型抽取方案,规避了人工设计规则对于一些排版变化的样例适配性差的问题。由于模型是通过大量数据训练得到的,它能够更好地泛化到未见过的票据样本上,提高识别的准确性和鲁棒性。模型抽取方案可以集成自动化的分类、回流和再训练流程。这意味着系统可以自动从错误中学习并优化自身,不断提高识别性能。并且,相比于传统OCR,模型抽取方案减少了对人工设计规则的依赖,从而降低了系统更新和维护的工作量。
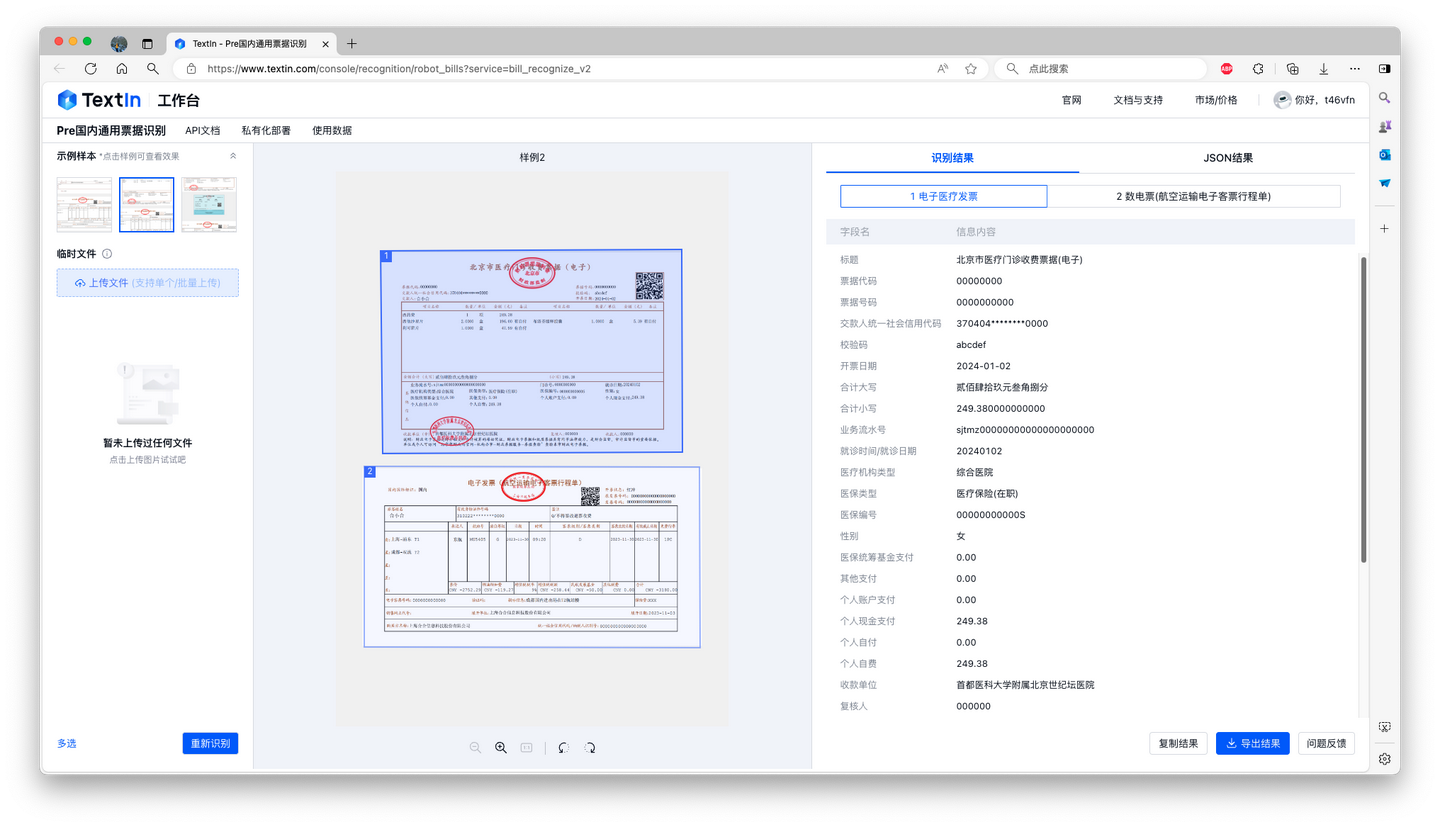
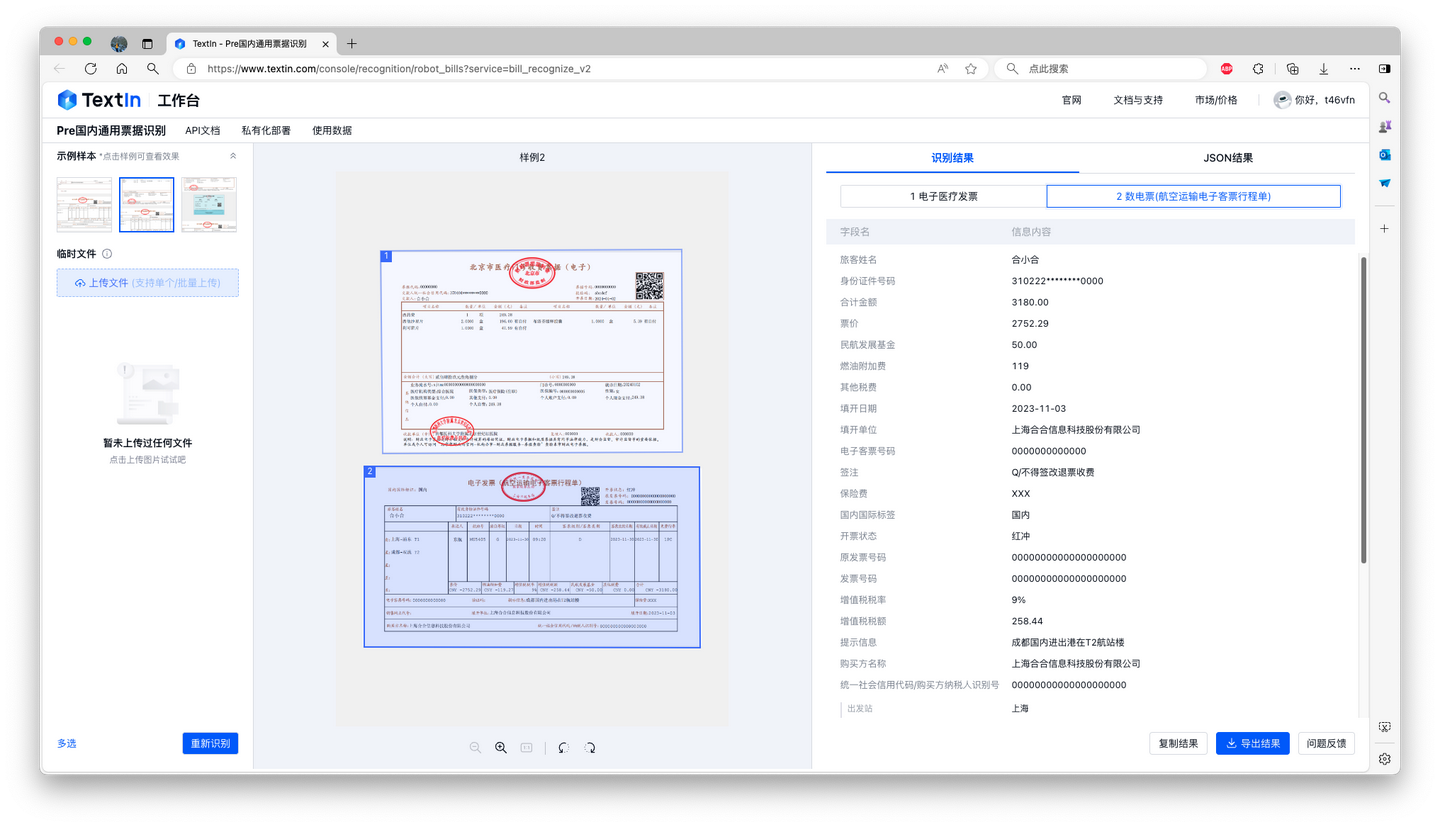
- 提高效率:快速准确地从医疗发票中提取信息,减少人工输入工作量,显著提高处理速度。
- 减少错误:减少因人工输入错误导致的审核错误,提高审核准确性。
- 自动化流程:可与现有财务和保险系统整合,实现从发票识别到报销流程的自动化,减少人工干预。
- 节约成本:通过自动化处理,减少对人力资源的依赖,降低运营成本。
- 改善客户体验:通过顺畅的报销流程提升客户满意度,增强客户对保险机构或公司的信任。
- 对于异地就医,多票识别2.0使发票实现线上流转,无需物理传输,加快报销速度。
- 环境友好:减少纸质发票使用,有助于实现绿色办公,符合可持续发展理念。
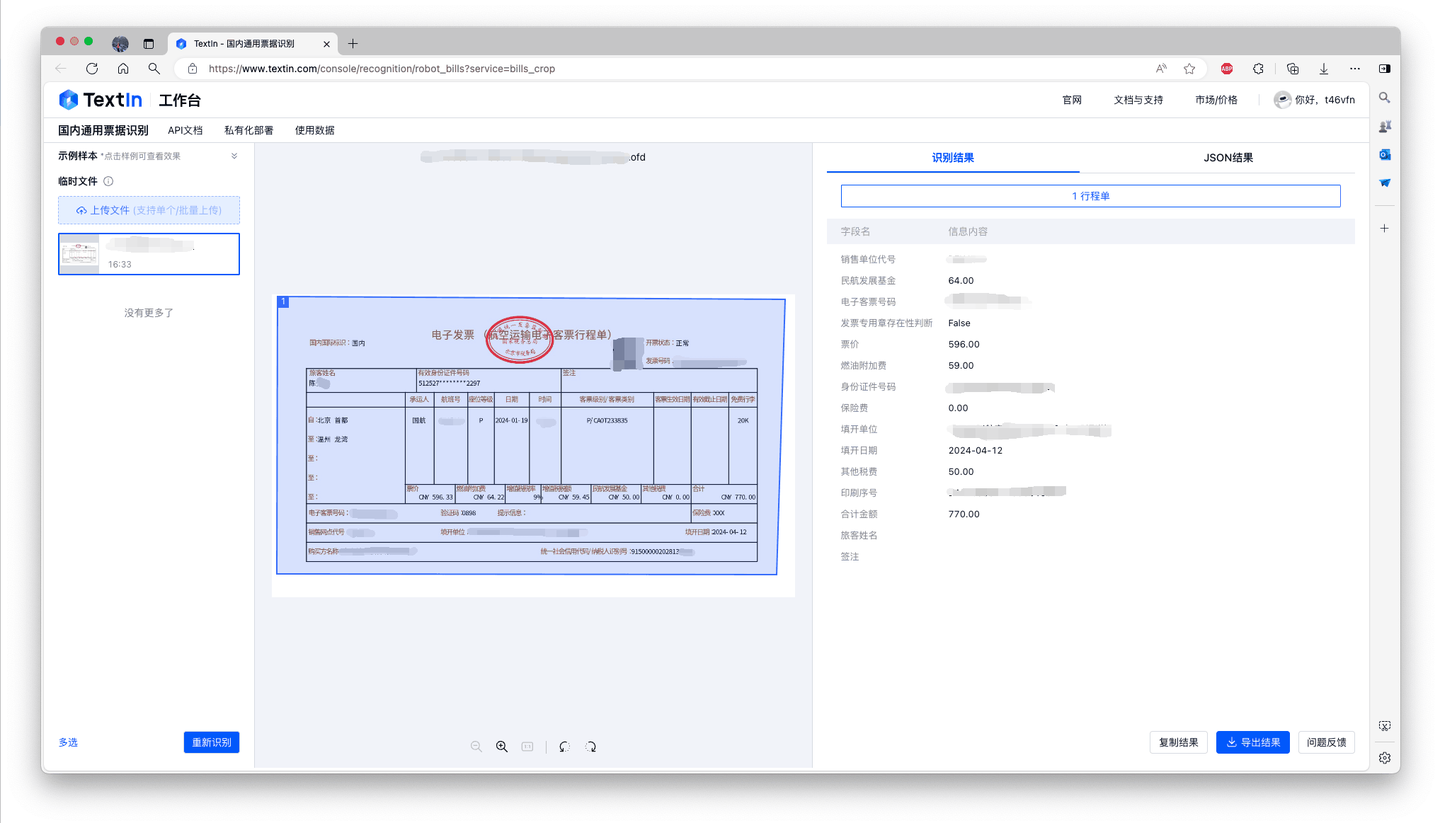
- 低成本:SaaS服务单次调用低至0.05元,新用户享受100次免费调用,支持Web前端使用,降低试用门槛。
- 高精度:基于合合信息自研OCR引擎,清晰有效样本识别准确率超95%。
- 高效率:单次识别速度<2秒,私有化版本采用全新模型架构,资源占用稳定。
- 强兼容:支持多种图像格式、多页PDF和OFD输入,集成智能切边技术,支持单页多票据识别。
- 简易集成:标准化API接口,支持智能分类,无需手动指定。
- 灵活部署:支持私有化、公有云部署,提供前端识别预览和标准化JSON结果。
- Web前端直接调用,便于试用、体验
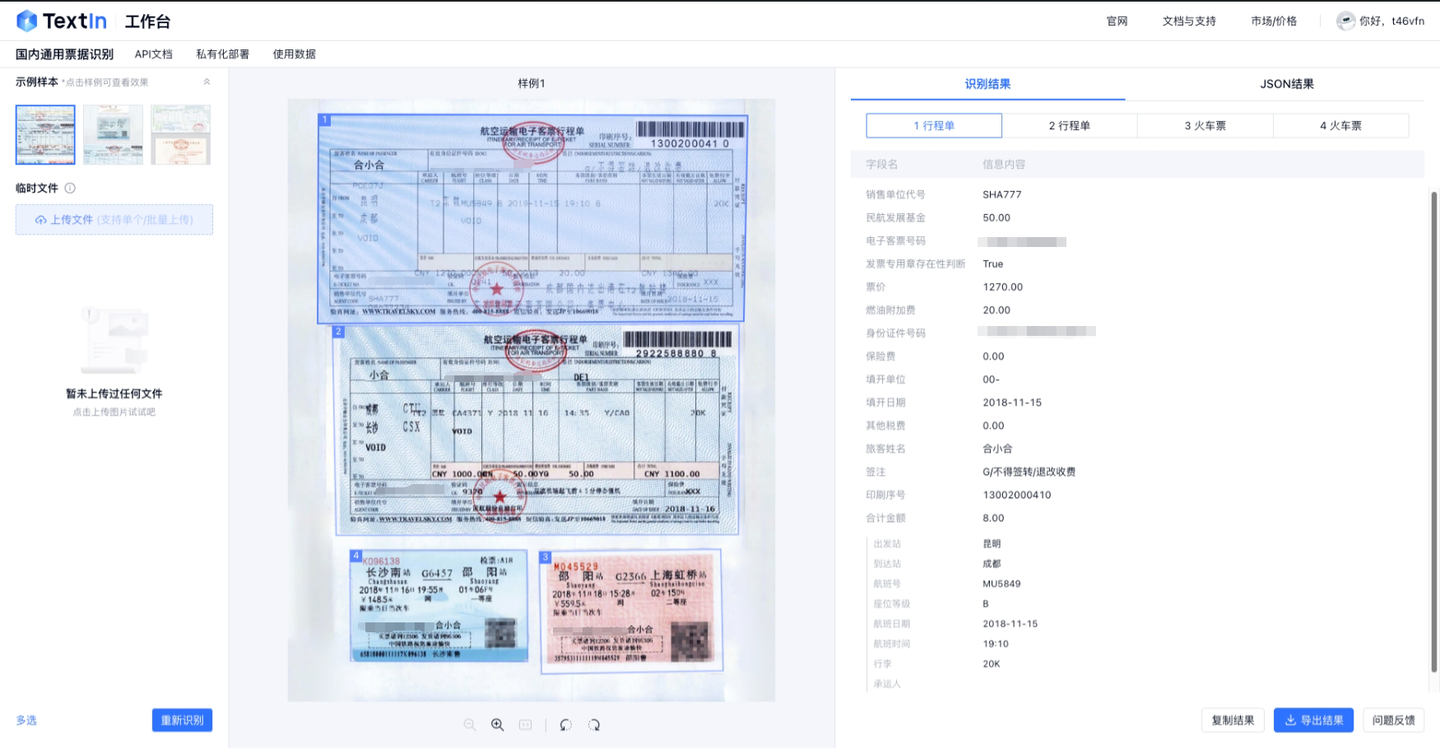
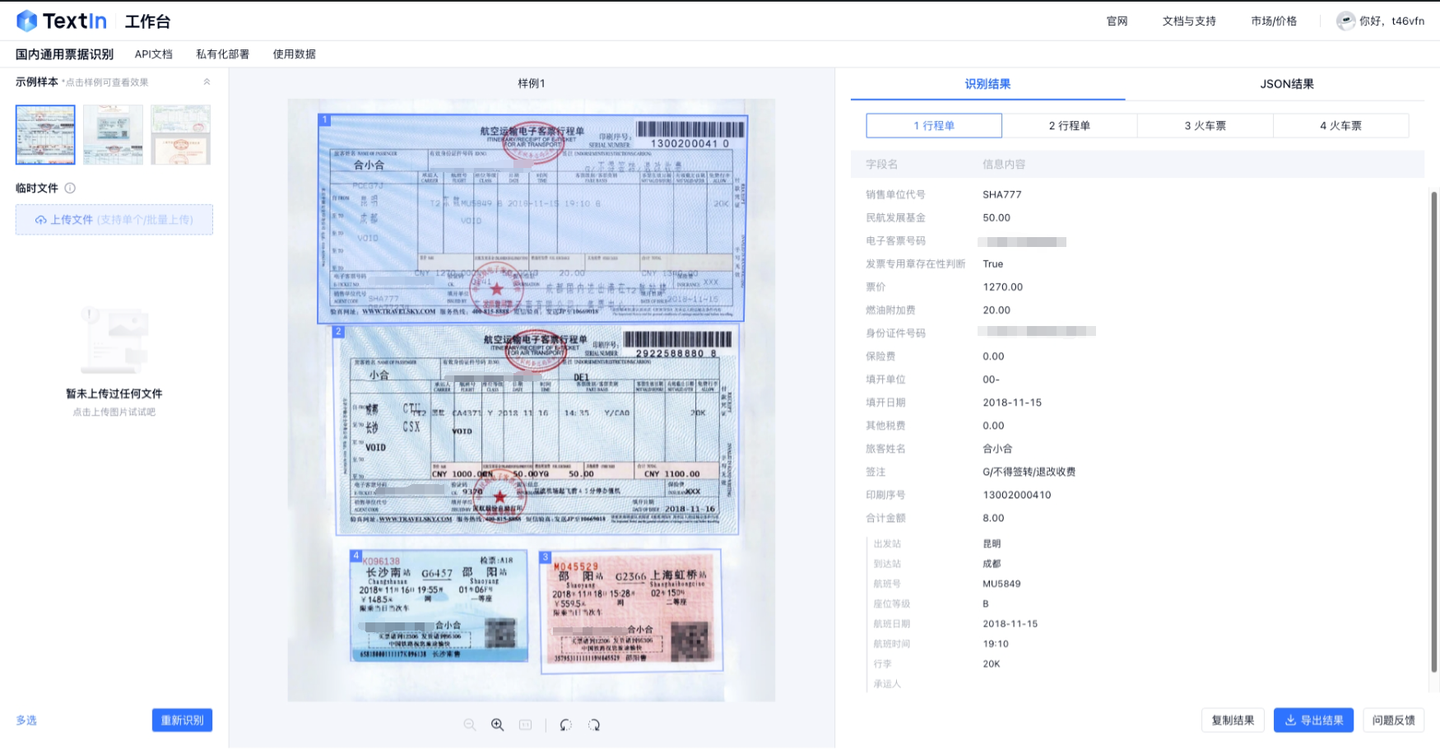
- 多票混贴能够清晰区分,精准识别、定位到票面,也可以便捷地切换识别结果展示
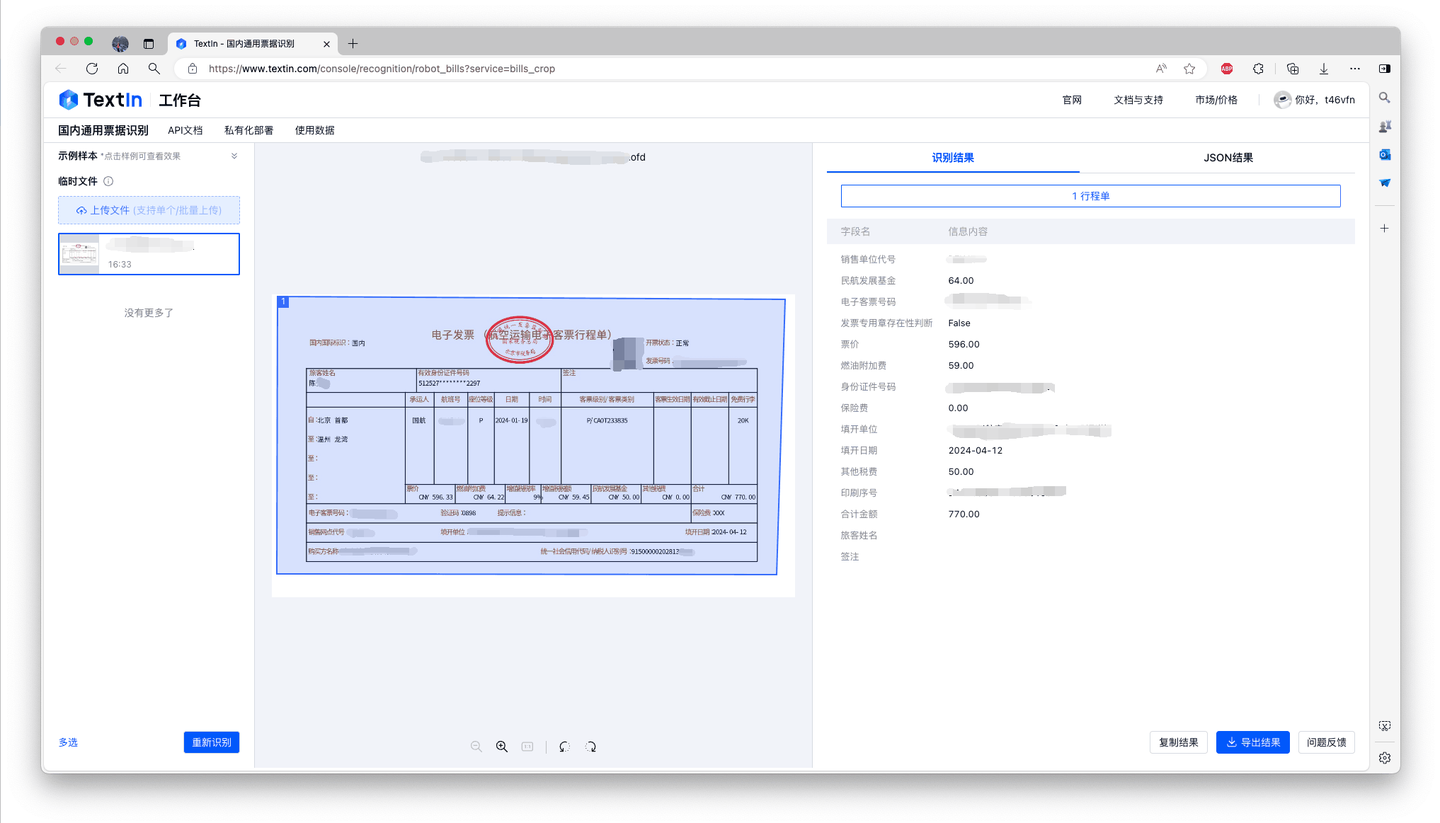
- OFD格式同样支持识别
- 保险理赔快人一步:
- 在保险行业中,OCR技术广泛应用于保单信息提取、理赔资料审核等领域。通过OCR技术,可以快速识别保单上的文字信息,提取关键信息,如投保人姓名、保险类型、保险金额等。
- 传统保险理赔流程中,由于对原始单据人工录入的依赖,周期通常需要几周到一个月不等,涉及多家保险公司混合理赔耗时更长。
- 通过多票识别2.0,无论业务流程是由用户端还是理赔公司发起,信息录入和校对的耗时都将大幅降低,提高业务吞吐量的同时显著优化用户体验,提高用户粘性。此外,更精准的大量票据数据也为保险机构提供了更全面的数据分析和挖掘基础,从而更好地了解客户需求,制定更精准的市场策略。
- 财务报销效率提升:
- 无论对于大型企业还是中小微企业,企业内报销业务对于财务部门都是一大重要任务。
- 传统的人工录入报销单据信息存在低效、易出错等问题,不仅降低员工工作积极性,还会导致一系列管理成本的上升。
- OCR识别技术可以自动高精度识别单据信息,减少人工干预,降低人力成本,提高了企业财务工作的整体运营效率,为更有附加价值的企业财务工作腾出时间和精力,进一步赋能企业效率升级。
全面升级,票据识别新纪元:合合信息TextIn多票识别2.0的更多相关文章
- 【前端优化之拆分CSS】前端三剑客的分分合合
几年前,我们这样写前端代码: <div id="el" style="......" onclick="......">测试&l ...
- 刚破了潘金莲的身份信息(图片文字识别),win7、win10实测可用(免费下载)
刚破了潘金莲的身份信息(图片文字识别),win7.win10实测可用 效果如下: 证照,车牌.身份证.名片.营业执照 等图片文字均可识别 电脑版 本人出品 大小1.3MB 下载地址:https://p ...
- ChipGenius 识别U盘主控信息
ChipGenius 识别U盘主控信息 ================== End
- Tidyverse|数据列的分分合合,爱恨情仇
Tidyverse|数据列的分分合合,爱恨情仇 本文首发于“生信补给站”Tidyverse|数据列的分分合合,一分多,多合一 TCGA数据挖掘可做很多分析,前期数据“清洗”费时费力但很需要. 比如基因 ...
- 【Python自动化Excel】pandas处理Excel的“分分合合”
话说Excel数据表,分久必合.合久必分.Excel数据表的"分"与"合"是日常办公中常见的操作.手动操作并不困难,但数据量大了之后,重复性操作往往会令人崩溃. ...
- 【Python自动化Excel】pandas操作Excel的“分分合合”
话说Excel数据表,分久必合.合久必分.Excel数据表的"分"与"合"是日常办公中常见的操作.手动操作并不困难,但数据量大了之后,重复性操作往往会令人崩溃. ...
- h5移动端识别二维码信息
jsqr插件 图片跨域时不允许绘制到canvas,所以先转blob在画到canvas上面就可以,如果不跨域直接画就行 function getImageBlob (url) { ...
- Python识别验证码,基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[li ...
- 行人重识别(ReID) ——基于深度学习的行人重识别研究综述
转自:https://zhuanlan.zhihu.com/p/31921944 前言:行人重识别(Person Re-identification)也称行人再识别,本文简称为ReID,是利用计算机视 ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
随机推荐
- 关于mybatisplus与mybatis的自动填充混用问题
public class MybatisPlusAutoFillHandler implements MetaObjectHandler { //插入时的填充策略 @Override public v ...
- 解决004--Loading local data is disabled; this must be enabled on both the client and server sides问题及解决
因为下载了SQLyog的ultimate版本,现在就可以导入外部的数据了.有着之前使用insert into插入语句来添加近50条有着大概10个字段的记录的经历之后,本着能够导入现成的数据就导入的想法 ...
- 对比python学julia(第一章)--(第四节)冰雹猜想
4.1 依葫芦画瓢 冰雹猜想是一种非常有趣的数字黑洞,曾让无数的数学爱好者为之痴迷.它有一个非常简单的变换规则,具体来说就是:任意取一个正整数n,如果n是偶数,就把n变成n/2;如果n是奇数,就把n变 ...
- 第四范式开源强化学习框架——OpenRL
维护者信息: 知乎地址: https://www.zhihu.com/people/huangshiyu.me 个人主页: http://tartrl.cn/people/huangshiyu/ Gi ...
- Ubuntu18.04 系统环境下 vscode中忽略pylint某些错误或警告
相关: ubuntu18.04系统环境下使用vs code安装pylint检查python的代码错误 ====================================== 假设已经在前文(ht ...
- X86架构CPU下Ubuntu系统环境源码编译pytorch-gpu-2.0.1版本
本文操作步骤与 aarch64架构CPU下Ubuntu系统环境源码编译pytorch-gpu-2.0.1版本大致相同,只是CPU架构不同而已,因此这里只记录不同的地方. 重点: 一个个人心得,那就是要 ...
- 从baselines库的common/vec_env/vec_normalize.py模块看方差的近似计算方法
在baselines库的common/vec_env/vec_normalize.py中计算方差的调用方法为: RunningMeanStd 同时该计算函数的解释也一并给出了: https://en. ...
- 利用sql查出的结果集重新生成一张虚拟表
"select * from ( SELECT mc.id,mc.sn,mc.updated,mc.client_name,mc.brand,mc.mileage,mc.displace,m ...
- 零基础学习人工智能—Python—Pytorch学习(三)
前言 这篇文章主要两个内容. 一,把上一篇关于requires_grad的内容补充一下. 二,介绍一下线性回归. 关闭张量计算 关闭张量计算.这个相对简单,阅读下面代码即可. print(" ...
- 2023上海理工大学校内选拔赛A-D题
前言 不要在意标题,既然是随记,就随性点() 今天参加了2023年中国高校计算机大赛-团队程序设计天梯赛(GPLT)上海理工大学校内选拔赛(同步赛)_ACM/NOI/CSP/CCPC/ICPC算法编程 ...