spark(1.1) mllib 源代码分析
在spark mllib 1.1加入版本stat包,其中包括一些统计数据有关的功能。本文分析中卡方检验和实施的主要原则:
一个、根本
在stat包实现Pierxunka方检验,它包括以下类别
(1)适配度检验(Goodness of Fit test):验证一组观察值的次数分配是否异于理论上的分配。
(2)独立性检验(independence test) :验证从两个变量抽出的配对观察值组是否互相独立(比如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)
计算公式:
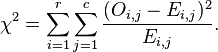
当中O表示观測值,E表示期望值
具体原理能够參考:http://zh.wikipedia.org/wiki/%E7%9A%AE%E7%88%BE%E6%A3%AE%E5%8D%A1%E6%96%B9%E6%AA%A2%E5%AE%9A
二、java api调用example
三、源代码分析
1、外部api
通过Statistics类提供了4个外部接口

// Goodness of Fit test
def chiSqTest(observed: Vector, expected: Vector): ChiSqTestResult = {
ChiSqTest.chiSquared(observed, expected)
}
//Goodness of Fit test
def chiSqTest(observed: Vector): ChiSqTestResult = ChiSqTest.chiSquared(observed) //independence test
def chiSqTest(observed: Matrix): ChiSqTestResult = ChiSqTest.chiSquaredMatrix(observed)
//independence test
def chiSqTest(data: RDD[LabeledPoint]): Array[ChiSqTestResult] = {
ChiSqTest.chiSquaredFeatures(data)
}
2、Goodness of Fit test实现
这个比較简单。关键是依据(observed-expected)2/expected计算卡方值
/*
* Pearon's goodness of fit test on the input observed and expected counts/relative frequencies.
* Uniform distribution is assumed when `expected` is not passed in.
*/
def chiSquared(observed: Vector,
expected: Vector = Vectors.dense(Array[Double]()),
methodName: String = PEARSON.name): ChiSqTestResult = { // Validate input arguments
val method = methodFromString(methodName)
if (expected.size != 0 && observed.size != expected.size) {
throw new IllegalArgumentException("observed and expected must be of the same size.")
}
val size = observed.size
if (size > 1000) {
logWarning("Chi-squared approximation may not be accurate due to low expected frequencies "
+ s" as a result of a large number of categories: $size.")
}
val obsArr = observed.toArray
// 假设expected值没有设置,默认取1.0 / size
val expArr = if (expected.size == 0) Array.tabulate(size)(_ => 1.0 / size) else expected.toArray / 假设expected、observed值都必需要大于1
if (!obsArr.forall(_ >= 0.0)) {
throw new IllegalArgumentException("Negative entries disallowed in the observed vector.")
}
if (expected.size != 0 && ! expArr.forall(_ >= 0.0)) {
throw new IllegalArgumentException("Negative entries disallowed in the expected vector.")
} // Determine the scaling factor for expected
val obsSum = obsArr.sum
val expSum = if (expected.size == 0.0) 1.0 else expArr.sum
val scale = if (math.abs(obsSum - expSum) < 1e-7) 1.0 else obsSum / expSum // compute chi-squared statistic
val statistic = obsArr.zip(expArr).foldLeft(0.0) { case (stat, (obs, exp)) =>
if (exp == 0.0) {
if (obs == 0.0) {
throw new IllegalArgumentException("Chi-squared statistic undefined for input vectors due"
+ " to 0.0 values in both observed and expected.")
} else {
return new ChiSqTestResult(0.0, size - 1, Double.PositiveInfinity, PEARSON.name,
NullHypothesis.goodnessOfFit.toString)
}
}
// 计算(observed-expected)2/expected
if (scale == 1.0) {
stat + method.chiSqFunc(obs, exp)
} else {
stat + method.chiSqFunc(obs, exp * scale)
}
}
val df = size - 1
val pValue = chiSquareComplemented(df, statistic)
new ChiSqTestResult(pValue, df, statistic, PEARSON.name, NullHypothesis.goodnessOfFit.toString)
}
3、independence test实现
先通过以下的公式计算expected值,矩阵共同拥有 r 行 c 列
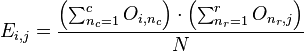
然后依据(observed-expected)2/expected计算卡方值
/*
* Pearon's independence test on the input contingency matrix.
* TODO: optimize for SparseMatrix when it becomes supported.
*/
def chiSquaredMatrix(counts: Matrix, methodName:String = PEARSON.name): ChiSqTestResult = {
val method = methodFromString(methodName)
val numRows = counts.numRows
val numCols = counts.numCols // get row and column sums
val colSums = new Array[Double](numCols)
val rowSums = new Array[Double](numRows)
val colMajorArr = counts.toArray
var i = 0
while (i < colMajorArr.size) {
val elem = colMajorArr(i)
if (elem < 0.0) {
throw new IllegalArgumentException("Contingency table cannot contain negative entries.")
}
colSums(i / numRows) += elem
rowSums(i % numRows) += elem
i += 1
}
val total = colSums.sum // second pass to collect statistic
var statistic = 0.0
var j = 0
while (j < colMajorArr.size) {
val col = j / numRows
val colSum = colSums(col)
if (colSum == 0.0) {
throw new IllegalArgumentException("Chi-squared statistic undefined for input matrix due to"
+ s"0 sum in column [$col].")
}
val row = j % numRows
val rowSum = rowSums(row)
if (rowSum == 0.0) {
throw new IllegalArgumentException("Chi-squared statistic undefined for input matrix due to"
+ s"0 sum in row [$row].")
}
val expected = colSum * rowSum / total
statistic += method.chiSqFunc(colMajorArr(j), expected)
j += 1
}
val df = (numCols - 1) * (numRows - 1)
val pValue = chiSquareComplemented(df, statistic)
new ChiSqTestResult(pValue, df, statistic, methodName, NullHypothesis.independence.toString)
}
版权声明:本文博客原创文章,博客,未经同意,不得转载。
spark(1.1) mllib 源代码分析的更多相关文章
- Spark机器学习之MLlib整理分析
友情提示: 本文档根据林大贵的<Python+Spark 2.0 + Hadoop机器学习与大数据实战>整理得到,代码均为书中提供的源码(python 2.X版本). 本文的可以利用pan ...
- Spark里边:Worker源代码分析和架构
首先由Spark图表理解Worker于Spark中的作用和地位: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvYW56aHNvZnQ=/font/5a6L ...
- Spark SQL 源代码分析系列
从决定写Spark SQL文章的源代码分析,到现在一个月的时间,一个又一个几乎相同的结束很快,在这里也做了一个综合指数,方便阅读,下面是读取顺序 :) 第一章 Spark SQL源代码分析之核心流程 ...
- Spark MLlib之线性回归源代码分析
1.理论基础 线性回归(Linear Regression)问题属于监督学习(Supervised Learning)范畴,又称分类(Classification)或归纳学习(Inductive Le ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
/** Spark SQL源代码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache ...
- Spark SQL Catalyst源代码分析之TreeNode Library
/** Spark SQL源代码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心执行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,可是发 ...
- Spark SQL Catalyst源代码分析Optimizer
/** Spark SQL源代码分析系列*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer 以及核心类库TreeNode,本文将具体解说S ...
- Spark SQL源代码分析之核心流程
/** Spark SQL源代码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几 ...
随机推荐
- nginx+lua+redis构建高并发应用(转)
nginx+lua+redis构建高并发应用 ngx_lua将lua嵌入到nginx,让nginx执行lua脚本,高并发,非阻塞的处理各种请求. url请求nginx服务器,然后lua查询redis, ...
- android_定义多个Activity及跳转
说明:在Android应用程序其中创建多个activity,而且启动一个activity的方法,以及activity之间的跳转. 样例:在MainActivity里面加入一个button,触动butt ...
- CF(427D-Match & Catch)后缀数组应用
题意:给两个字符串,求一个最短的子串.使得这个子串在两个字符串中出现的次数都等于1.出现的定义为:能够重叠的出现. 解法:后缀数组的应用.从小枚举长度.假设一个长度len合法的话:则一定存在这个样的s ...
- Uncaught TypeError: Cannot read property 'call' of undefined jquery.validate.min.js:28
最近在做表单验证时,,自己写的addMethod 方法总是不起作用.折腾了将近一天. 报告的错误,如下面的 Uncaught TypeError: Cannot read property 'call ...
- mac平台adb、tcpdump捕手android移动网络数据包
在移动电话的发展app当我们希望自己的下才能看到app网络发出请求,这个时候我们需要tcpdump工具包捕获.实现tcpdump空灵,以下步骤需要: 在这里,在android 华为手机 P6对于样本 ...
- 创建Material Design风格的Android应用--使用Drawable
下面Drawables的功能帮助你在应用中实现Material Design: 图片资源着色 在android 5.0(api 21)和更高版本号,能够着色bitmap和.9 png 通过定义透明度遮 ...
- redis内存管理代码的目光
zmalloc.h /* zmalloc - total amount of allocated memory aware version of malloc() * * Copyright (c) ...
- C# - Dictionary join keys or join Values
using System; using System.Collections.Generic; using System.Linq; using System.Text; public class P ...
- hdu 3572 Task Schedule (dinic算法)
pid=3572">Task Schedule Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 ...
- MEMO:UIButton 中的图片和标题 左对齐
UIButton setImage 和 setTitle之后.默认 image和title 对齐居中, 因为 title 长度不固定. 所以假设要几个这样有image有title的button纵向排列 ...