从RNN到BERT
一、文本特征编码
1. 标量编码
美国:1 中国:2 印度:3 … 朝鲜:197
标量编码问题:美国 + 中国 = 3 = 印度
2. One-hot编码
美国:[1,0,0,0,…,0]
中国:[0,1,0,0,…,0]
印度:[0,0,1,0,…,0]
美国 + 中国 = [1,1,0,0,…,0],代表拥有美国和中国双重国籍
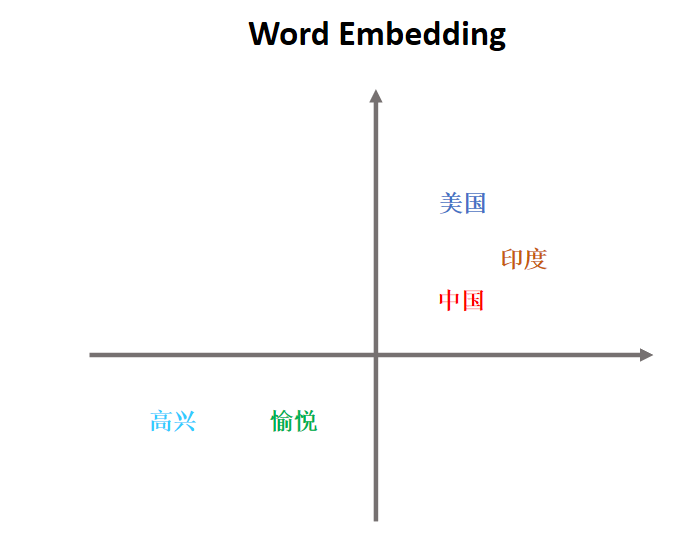
3. Embedding编码
二、文本序列化表示
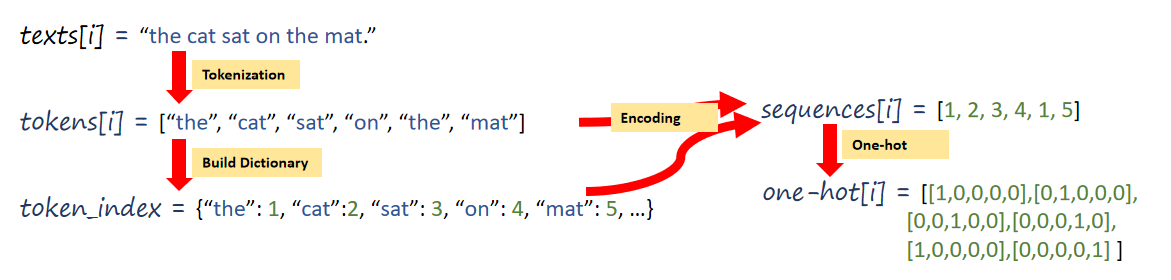
1、Tokenization

2、Build Dictionary


3、One-hot encoding
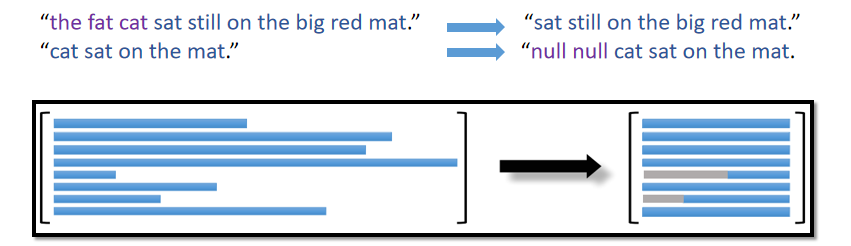
4、Align Sequences
三、RNN模型
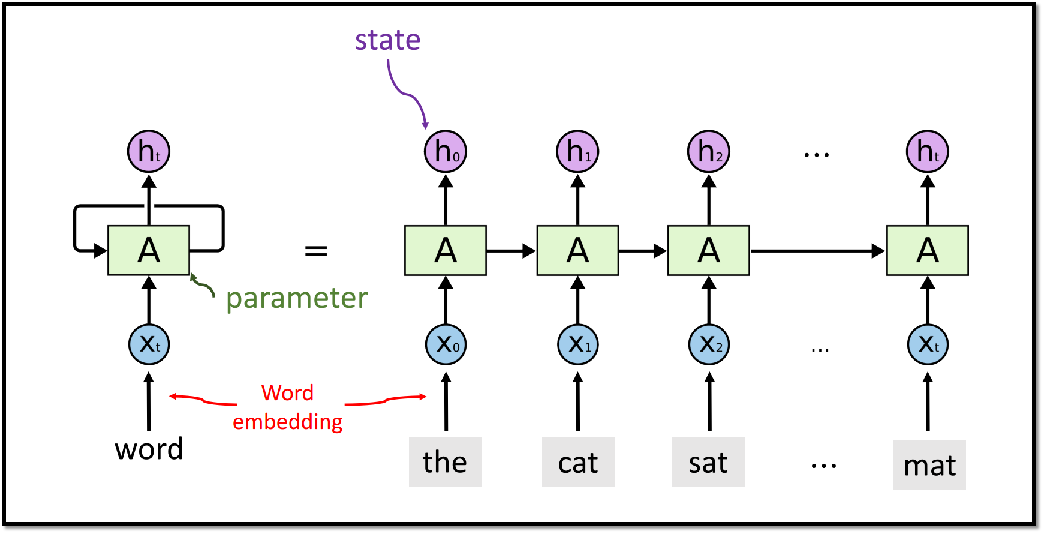
整个RNN只有一个参数矩阵A。RNN 在大规模的数据集上已经过时,不如Transformer模型,但在小规模数据集上,RNN还是很有用的。
3.1 RNN模型结构
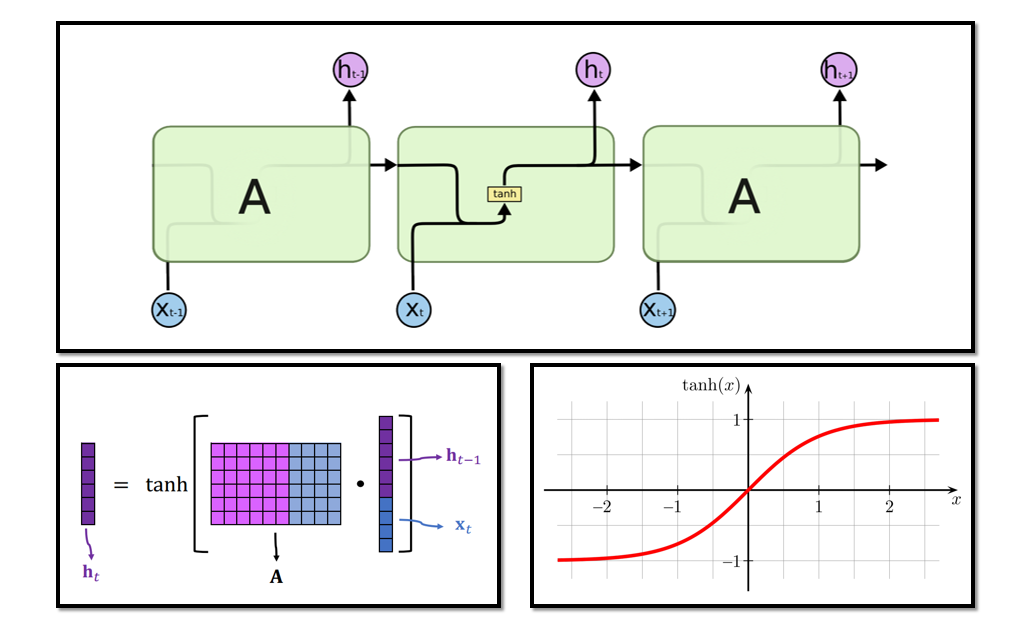
3.2 为什么用双曲正切?是否可去掉?

3.3 RNN的模型参数
参数矩阵A的行: shape(h)
参数矩阵A的列: shape(h)+shape(x)
总参数数量: shape(h)× [shape(h)+shape(x)] (未考虑偏移量bias)
输入x 的维度(词嵌入向量)应该通过交叉验证的方式选择 输出状态向量h的维度也应该通过交叉验证的方式选择。
3.4 基于RNN的分类任务
可以使用多个状态向量进行下游任务:
3.4.1 只使用最后一个状态向量

- Training Accuracy: 89.2%
- Validation Accuracy: 84.3%
- Test Accuracy: 84.4%
3.4.2 使用所有状态向量
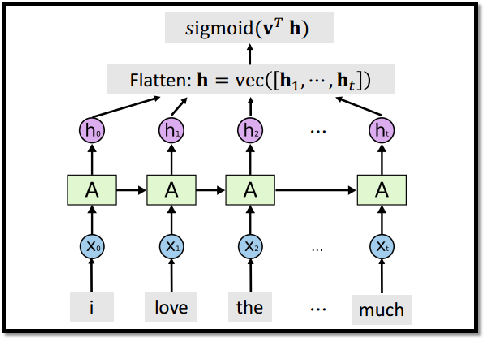
- Training Accuracy: 96.3%
- Validation Accuracy: 85.4%
- Test Accuracy: 84.7%
3.5 RNN的局限
RNN 在状态向量ht中积累xt及之前的所有信息,ht可以看作整个输入序列中抽取的特征向量
RNN 记忆比较短,会遗忘很久之前的输入x 。
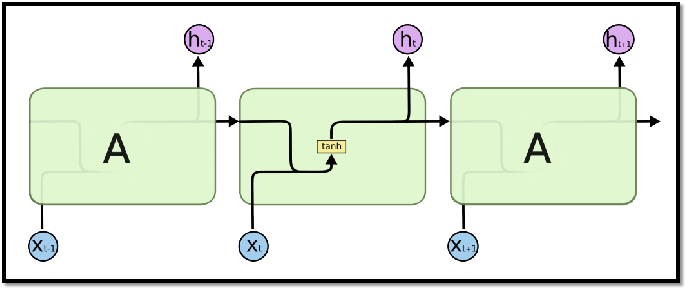
四、LSTM模型
4.1 RNN与LSTM网络结构比较
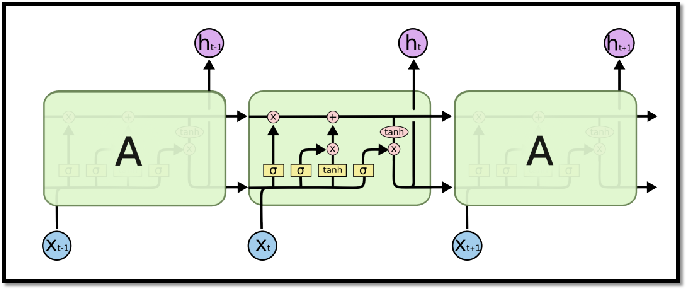
4.2 LSTM传送带
过去的信息直接流向未来。 LSTM使用“传送带”C 来获得比RNN更长的记忆。

4.3 LSTM 门
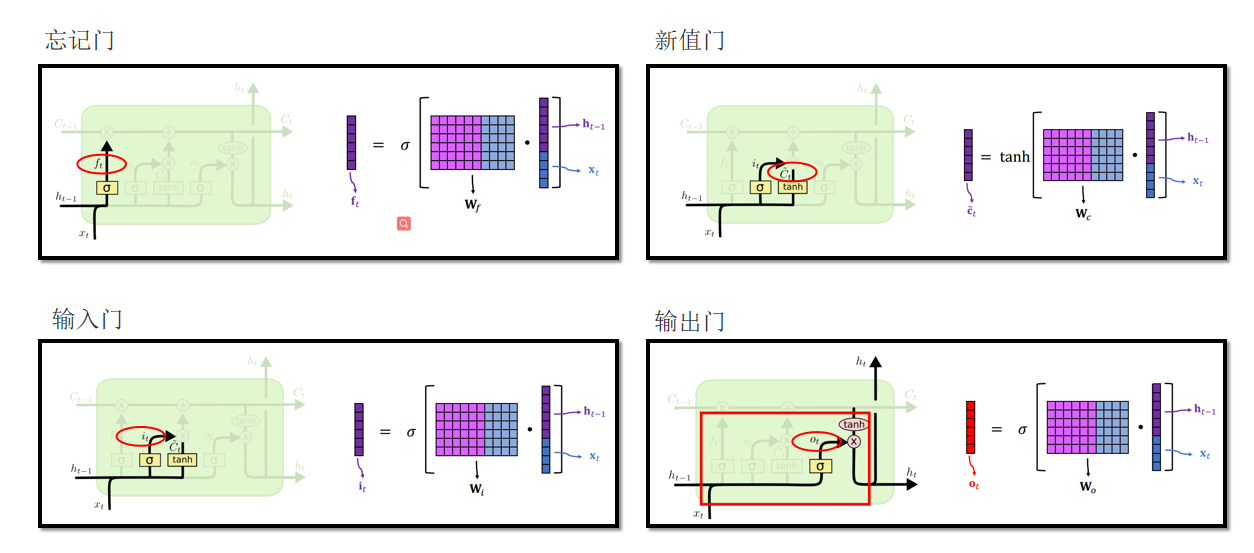
4.4 Bi-LSTM
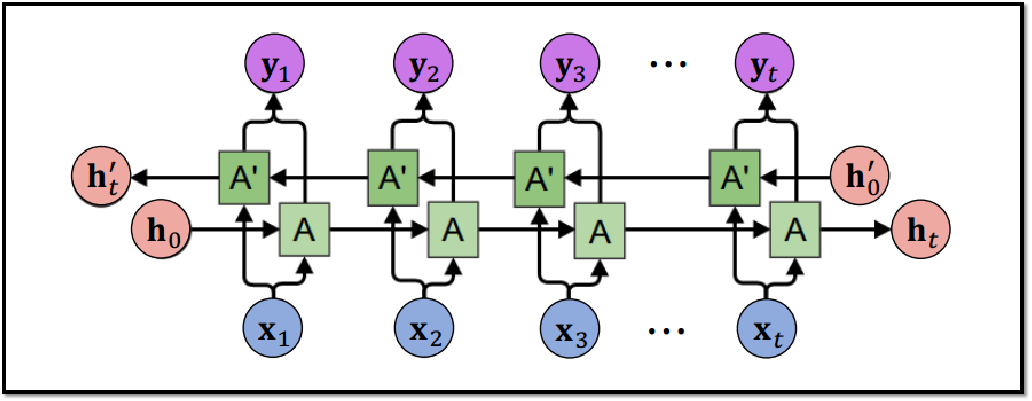
可以使用RNN或LSTM进行更为复杂的任务,例如机器翻译,下面会介绍机器翻译模型Seq2Seq。
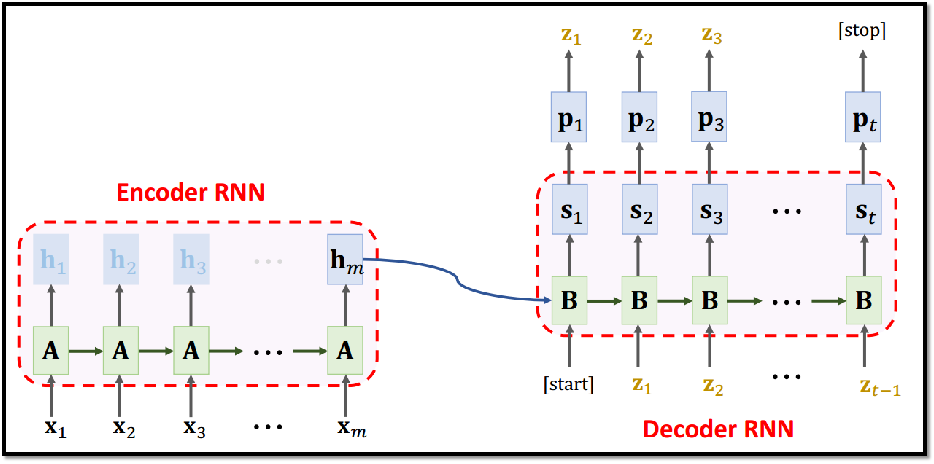
五、Seq2Seq模型
Seq2Seq模型用来进行句子翻译,Seq2Seq包括Encoder编码器以及Decoder 解码器 两部分,最早的Seq2Seq模型由两个RNN模型组成,如下图所示。
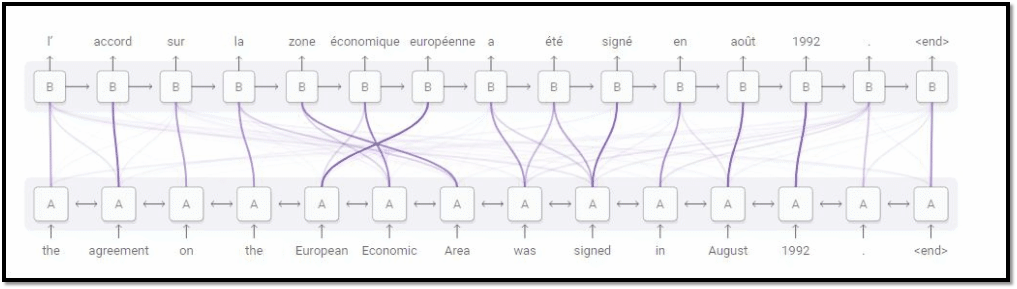
Attention对Seq2Seq网络的提升十分明显,如下图所示(BLEU:机器翻译评价指标,“双语评估替补”)

5.1 基于Attention的Seq2Seq模型
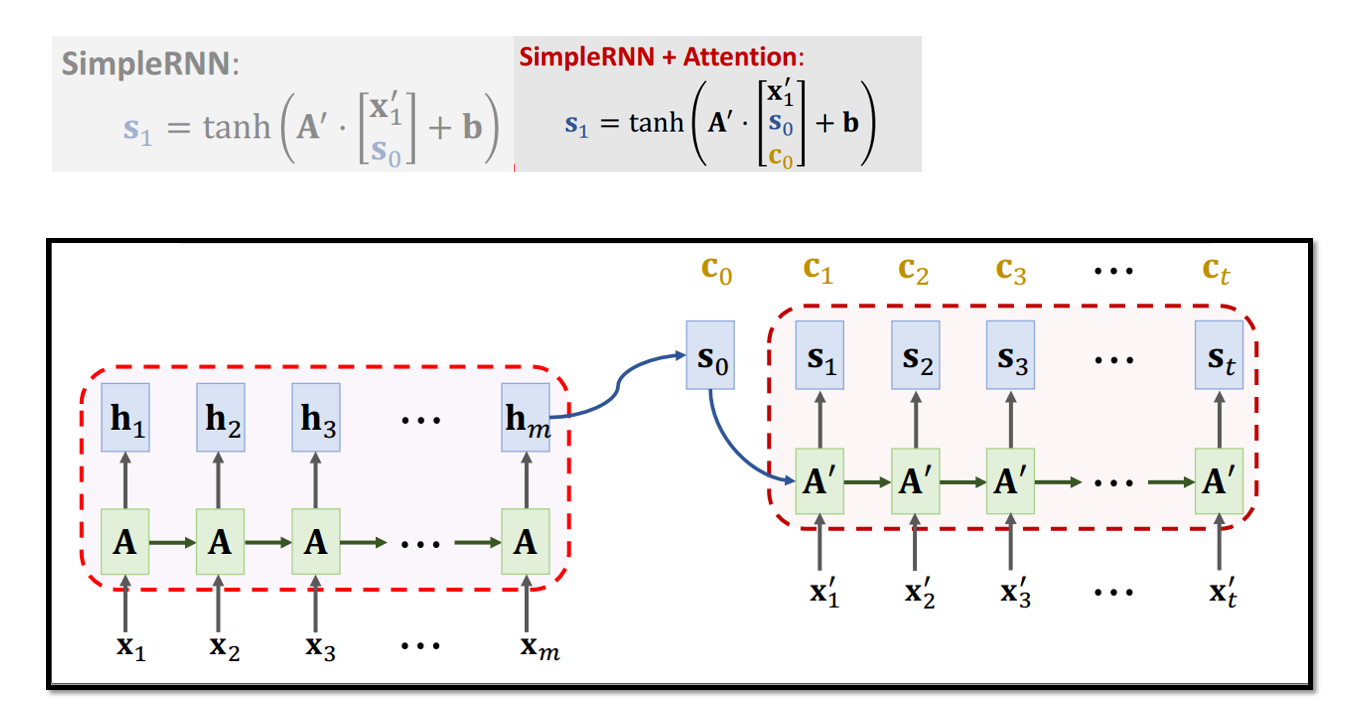
5.2 基于Attention的Seq2Seq模型参数计算
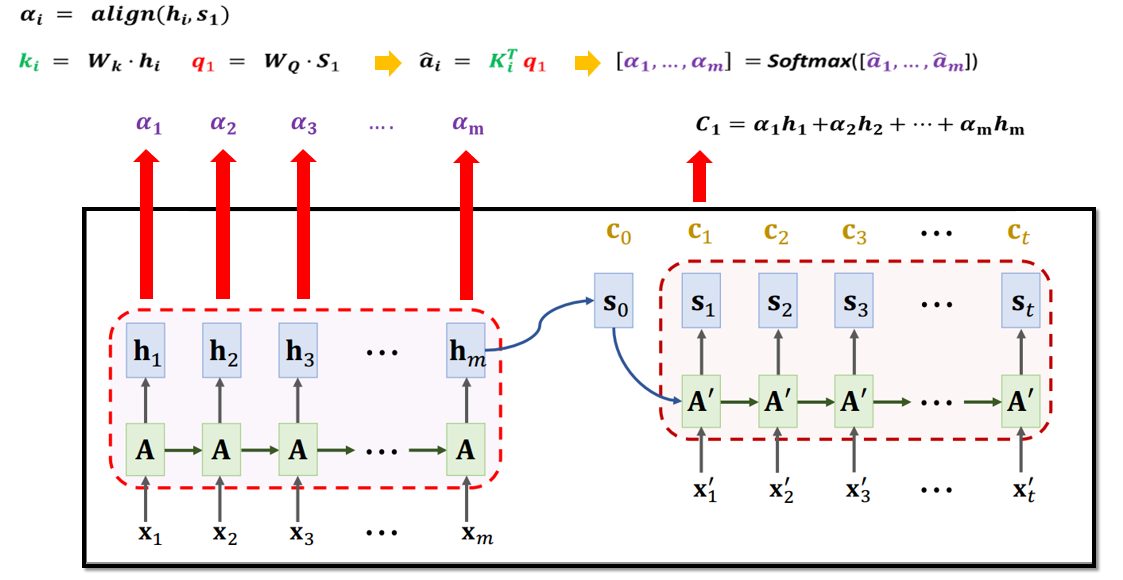
5.3 Attention的可解释性
无论输入多长,Attention都可以获得所有输入信息,且由于计算每个输出与所有输入的状态向量的相关性,所以会对相关的输入产生较高相关性,也就具备了一定的可解释性
六、Attention模型
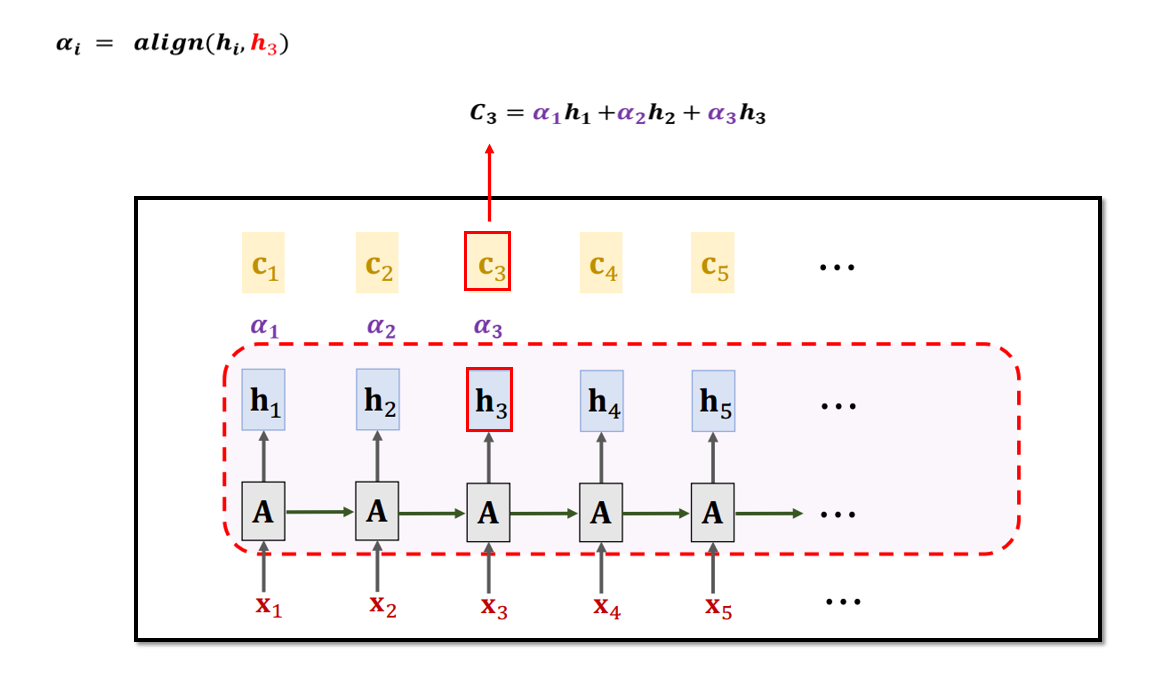
6.1 基于RNN的Self-Attention
Attention可以用来做句子翻译。 而Self-Attention可以用来代替RNN。 Self-Attention是Attention的特殊形式。Self-Attention模型其实就是在序列内部做Attention,寻找序列内部的联系。
例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
Self-Attention和RNN最大的区别是不使用状态向量h,而是采用状态向量c 去更新下一个状态h。

6.2 基于RNN的Self-Attention参数计算
七、Transformer模型
- Transformer完全基于Self- Attention 和Attention Transformer 是一个 Seq2Seq 模型
- 不是 RNN
- 仅包含Self-Attention层 、Attention层 和全连接层
- Transformer完爆最好的RNN+Attention模型
7.1 Transformer中的Attention
Transformer中的Attention剔除了RNN,即没有循环部分。
Attention层接收两个输入序列,分别为输入序列:
从RNN到BERT的更多相关文章
- ASE: CODEnn Reproduce
Background 第二次结对编程的任务是挑选一个用自然语言搜索相关代码片段的模型实现,并且可以提出自己的想法改进.这个任务很cool,前期做了不少调研.使用自然语言搜索相关代码片段现在是个很受关注 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- 深入理解BERT Transformer ,不仅仅是注意力机制
来源商业新知网,原标题:深入理解BERT Transformer ,不仅仅是注意力机制 BERT是google最近提出的一个自然语言处理模型,它在许多任务 检测上表现非常好. 如:问答.自然语言推断和 ...
- google tensorflow bert代码分析
参考网上博客阅读了bert的代码,记个笔记.代码是 bert_modeling.py 参考的博客地址: https://blog.csdn.net/weixin_39470744/article/de ...
- 【NLP】彻底搞懂BERT
# 好久没更新博客了,有时候随手在本上写写,或者Evernote上记记,零零散散的笔记带来零零散散的记忆o(╥﹏╥)o..还是整理到博客上比较有整体性,也方便查阅~ 自google在2018年10月底 ...
- 最强NLP模型-BERT
简介: BERT,全称Bidirectional Encoder Representations from Transformers,是一个预训练的语言模型,可以通过它得到文本表示,然后用于下游任务, ...
- Attention is all you need及其在TTS中的应用Close to Human Quality TTS with Transformer和BERT
论文地址:Attention is you need 序列编码 深度学习做NLP的方法,基本都是先将句子分词,然后每个词转化为对应的的词向量序列,每个句子都对应的是一个矩阵\(X=(x_1,x_2,. ...
- 基于Bert的文本情感分类
详细代码已上传到github: click me Abstract: Sentiment classification is the process of analyzing and reaso ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
随机推荐
- Demo_2:Qt实现猜字小游戏
1 环境 系统:windows 10 代码编写运行环境:Qt Creator 4.4.1 (community) Github: 2 简介 参考视频:https://www.bilibili.co ...
- List集合-03.Vector
3.Vector 3.1 UML图 3.2 Vector的特点 Object的数组存储元素 默认初始大小为10 public Vector() { this(10); } 线程安全,可以看到所有的数据 ...
- CF833A The Meaningless Game 题解
题目 Slastyona and her loyal dog Pushok are playing a meaningless game that is indeed very interesting ...
- Docker数据卷的介绍和使用
最近在学习docker,这篇主要讲了数据卷的作用以及使用,我用的是mac系统去操作的 1.数据卷的简介 2.数据卷的配置 (1).查看你的镜像docker images (2)运行的命令 ~$ doc ...
- TKCTF-学校内部的校赛
*Reverse easy_C easy_re1.exe 在网络百度到解决逆向需要用到软件IDA 然后用IDA打开一条条的找我找到了一条很怪的ZmxhZ3s1ZWU1ZjYyOC1mMzVhLTQxN ...
- 让windows原生CMD使用ls命令
1.新建ls.bat. 2.编辑内容: @echo off dir 3.将ls.bat文件放到C:\Windows目录下. 效果:
- CSS(二)- 选择器 - 一定要搞懂的选择器优先级和权重问题
css的优先级之前一直没怎么注意没当回事,总以为对同一元素靠后的渲染会覆盖前面的渲染,要是覆盖不了那就来个!important嘛.直到我那在学前端基础的后端伙伴拿一个问题问住了我,我才意识到这是重点中 ...
- linux专题(一):小白的开始以及相关的学习链接
转载自:https://www.cnblogs.com/ggjucheng/archive/2011/12/16/2290158.html 学习Linux也有一阵子了,这过程中磕磕撞撞的,遇到了问题, ...
- celery 基础教程(五):守护进程
一 守护进程方式启动 https://blog.csdn.net/p571912102/article/details/82735052 文件目录如下 . ├── config.py ├── main ...
- SpringMVC中@RequestBody接收前端传来的多个参数
在使用ajax发送请求时,如果发送的JSON数据是一个类中的不同属性,在Controller方法中使用@RequestBody会直接封装进该类中 例如: 前端部分代码 JavaScript <s ...