基于sinc的音频重采样(一):原理
我在前面的文章《音频开源代码中重采样算法的评估与选择》中说过sinc方法是较好的音频重采样方法,缺点是运算量大。https://ccrma.stanford.edu/~jos/resample/ 给出了sinc方法的原理文档和软件实现。以前是使用这个算法,没太关注原理和实现细节。去年(2020年)由于项目的需要和组内同学把这个算法的原理和软件实现细节搞清楚了。本文先讲讲sinc方法的原理,后面文章会讲讲软件实现的细节。
1,sinc函数和信号的采样与重建
在数字信号处理中,sinc函数定义为:
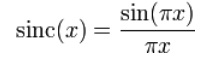
当x = 0时,sinc函数值为1,当x为整数时sinc函数值为0(这些整数点x称为过零点)。可以画出sinc函数的波形图如下:
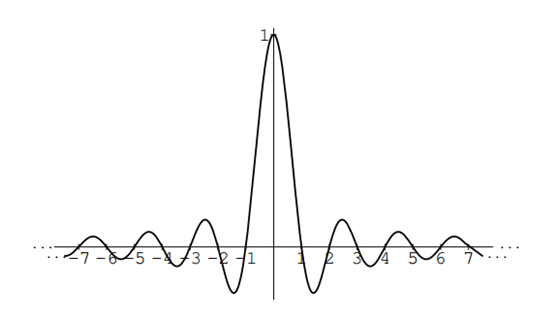
可以看出sinc函数是连续无限且关于Y轴对称的(即sinc函数是偶函数)。
采样定理说如果模拟信号x(t)包含的最大频率是Fmax且以Fs> 2Fmax的频率被采样,那么x(t)可以用插值函数:

从它的样本重建。这里的插值函数就是sinc函数。重建后的x(t)可表达为:
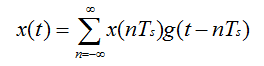
这里x(n/Fs) = x(nTs) = x(n)是x(t)的采样点值。Fs是采样频率,Ts是采样间隔,Fs = 1/Ts。
2,重采样
把数字信号的采样率从一个频率转换为一个另不同频率的过程称为重采样(sampling rate conversion,SRC)。上面采样定理说过如果信号的带宽小于采样率的一半,就可以用插值从样本重建信号。用新的采样率采样这个重建的信号,就可以实现重采样。
假设以Fx=1/Tx采样一个连续信号x(t),生成离散信号x(nTx)。使用插值公式:
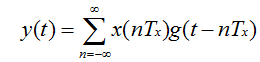
可以从样本x(nTx)生成连续信号y(t)。如果x(t)的带宽小于Fx/2且
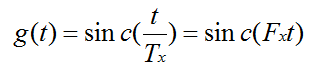
那么y(t) = x(t)。为了实现重采样,只需要以时间间隔t=mTy对y(t)进行求值即可,Fy=1/Ty是新的采样率。
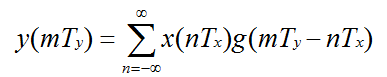
重新组织g(t)的参数:
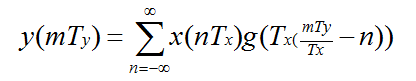
mTy/Tx可以分解成整数部分km和分数部分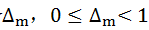
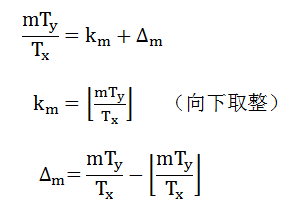
所以
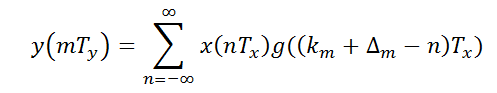
令k=km-n,所以 n =km – k, 从而
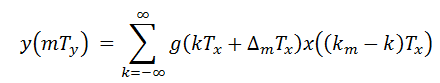
考虑到有上下采样,文档(https://ccrma.stanford.edu/~jos/resample/)给出插值函数为:
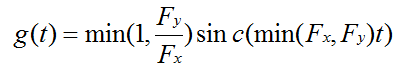
其中Fx为原采样率,Fy为新采样率。
令 A= min(1, Fy / Fx), B = min(Fx, Fy), ρ = Fy / Fx = Tx / Ty, 则g(t)可表示为
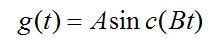
所以 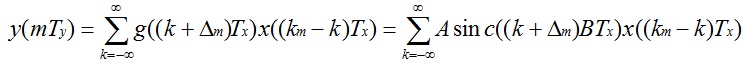
在上式中,x和y信号离散化后,在x信号和y信号中的Tx,Ty可以去掉了。式子就变成了如下:
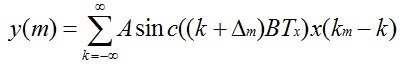
上式中BTx在Fx,Fy已知的情况下是个常数。
令D=BTx,上式就变成了:
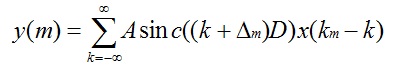
当上采样时B=Fx,则D=FxTx=1,A=1,所以式子重写为:
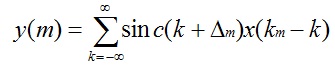
当下采样时B=Fy, 则D= FyTx = ρ A= ρ,所以式子重写为:
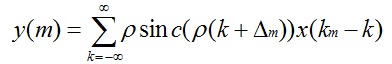
从上面的式子可以看出,新的采样率下的值是原采样率下的值和相对应的sinc函数的值的乘累加。由于sinc函数是连续且无限的,真正实现时是无法做到的,所以这儿通过截断sinc函数并离散化,来获得近似信号。在文档(https://ccrma.stanford.edu/~jos/resample/)中,使用Kaiser window加窗截断,通过线性插值采样后的样本来模拟脉冲响应的连续性,获得很好的效果。
至此基于sinc方法的重采样原理就讲完了,即新的采样率下的值是原采样率下的值和相对应的sinc函数的乘累加。如果此时去看相关的代码实现,很大可能是一头雾水,下篇将讲怎么基于原理去做软件实现以及实现中的一些细节。
基于sinc的音频重采样(一):原理的更多相关文章
- 基于sinc的音频重采样(二):实现
上篇(基于sinc的音频重采样(一):原理)讲了基于sinc方法的重采样原理,并给出了数学表达式,如下: (1) 本文讲如何基于这个数学表达式来做软件实现.软件实现的 ...
- 基于傅里叶变换的音频重采样算法 (附完整c代码)
前面有提到音频采样算法: WebRTC 音频采样算法 附完整C++示例代码 简洁明了的插值音频重采样算法例子 (附完整C代码) 近段时间有不少朋友给我写过邮件,说了一些他们使用的情况和问题. 坦白讲, ...
- FFmpeg(11)-基于FFmpeg进行音频重采样(swr_init(), swr_convert())
一.包含头文件和库文件 修改CMakeLists # swresample add_library(swresample SHARED IMPORTED) set_target_properties( ...
- 简洁明了的插值音频重采样算法例子 (附完整C代码)
近一段时间在图像算法以及音频算法之间来回游走. 经常有一些需求,需要将音频进行采样转码处理. 现有的知名开源库,诸如: webrtc , sox等, 代码阅读起来实在闹心. 而音频重采样其实也就是插值 ...
- 基于RNN的音频降噪算法 (附完整C代码)
前几天无意间看到一个项目rnnoise. 项目地址: https://github.com/xiph/rnnoise 基于RNN的音频降噪算法. 采用的是 GRU/LSTM 模型. 阅读下训练代码,可 ...
- 最简单的基于FFMPEG的音频编码器(PCM编码为AAC)
http://blog.csdn.net/leixiaohua1020/article/details/25430449 本文介绍一个最简单的基于FFMPEG的音频编码器.该编码器实现了PCM音频采样 ...
- 【转】基于RSA算法实现软件注册码原理初讨
1 前言 目前,商用软件和共享软件绝大部份都是采用注册码授权的方式来保证软件本身不被盗用,以保证自身的利益.尽管很多常用的许多软件系统的某些版本已经被别人破解,但对于软件特殊行业而言,注册码授权的方式 ...
- FFmpeg进行视频帧提取&音频重采样-Process.waitFor()引发的阻塞超时
由于产品需要对视频做一系列的解析操作,利用FFmpeg命令来完成视频的音频提取.第一帧提取作为封面图片.音频重采样.字幕压缩等功能: 前一篇文章已经记录了FFmpeg在JAVA中的使用-音频提取&am ...
- FFMpeg音频重采样和视频格式转
一.视频像素和尺寸转换函数 1.sws_getContext : 像素格式上下文 --------------->多副图像(多路视频)进行转换同时显示 2.struct SwsContext ...
随机推荐
- oranges-给mini os 添加内存管理,进程多级反馈队列,进程内存完整性度量
参考: 内存管理: https://www.jianshu.com/p/49cbaccd38c5 crc校验 https://www.cnblogs.com/zzdbullet/p/9580502.h ...
- Hacker101 CTF-Micro-CMS v2
一.打开网站是这个样子 找到一个登录框,存在注入漏洞 3.我们可以这样更改用户名中的输入: admin' or 1=1 -- 4.错误消息显示Invalid Password,因此我们也应该尝试构造一 ...
- volatile的内存屏障的坑
请看下面的代码并尝试猜测输出: 可能一看下面的代码你可能会放弃继续看了,但如果你想要彻底弄明白volatile,你需要耐心,下面的代码很简单! 在下面的代码中,我们定义了4个字段x,y,a和b,它们被 ...
- 第一个SpringMVC项目——HelloMVC
第一步:启动IDEA新建一个无模板的Maven项目,注意这还不是一个web项目,想成为web项目,需要添加web框架,这就是第二步需要做的事情 第二步:添加web框架支持 单击之后会弹出这个界面 第三 ...
- CSS3实现 垂直居中 水平居中 的技巧
1 1 1 How To Center Anything With CSS Front End posted by Code My Views 1 Recently, we took a dive i ...
- js Array.from & Array.of All In One
js Array.from & Array.of All In One 数组生成器 Array.from The Array.from() static method creates a ne ...
- import script module
import script module .mjs <script type="module"> import {addTextToBody} from './util ...
- Nestjs mongodb
nestjs 文档 mongoose 文档 使用"@meanie/mongoose-to-json"转换查询后返回的json数据 将"_id"转为"i ...
- css-next & grid layout
css-next & grid layout css3 demo https://alligator.io/ @media only screen and (max-width: 30em) ...
- asm 查看字节码
a.asm global Start section .text inc dword [esi] push edi mov edi,[esp+0x14] λ nasm -f win32 a.asm - ...