(数据科学学习手札94)QGIS+Conda+jupyter玩转Python GIS
本文完整代码及数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
QGIS随着近些年的发展,得益于其开源免费的特点,功能不断被世界各地的贡献者们开发完善,运算速度也非常出色,使得越来越多的Giser们从臃肿缓慢的Arcgis等传统平台转向QGIS。
 图1
图1
最重要的是,QGIS面向Python的接口PyQgis不仅可以用来开发QGIS插件,还可以配合Conda完美地避开路径配置的过程,直接与Conda虚拟环境集成在一起,从而随心所欲地在jupyter notebook之类的编辑器中书写Python代码调用各种QGIS中的地理计算功能,进而弥补geopandas在某些功能上的尚未完善之处。
 图2
图2
本文就将为大家展示如何集成QGIS到Conda环境里,并基于建好的环境在jupyter lab中调用QGIS从而解决实际计算问题。
2 配置QGIS+Conda+jupyter lab
接下来我们从0开始,完整地展示如何构建QGIS+Conda+jupyter lab的集成。
在已经正确安装和配置anaconda或miniconda的机器上,在终端执行conda create -n QGIS python=3.7 -y来建立一个Python虚拟环境,这里选择3.7版本的Python。
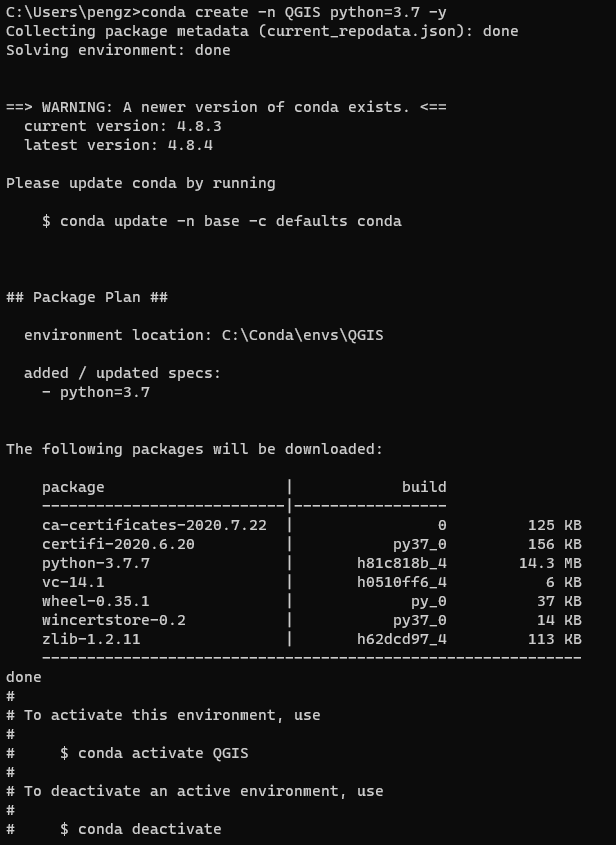 图3
图3
接下来我们执行conda activate QGIS激活刚刚创建好的环境之后,接着执行conda install -c conda-forge qgis -y来直接安装QGIS相关组件。
如果你的下载过程非常缓慢且你没有“特殊”的上网技巧,可以将-c参数后的源更换为国内的清华大学对应镜像(https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge),因为QGIS本身有着一定的体积且依赖包众多,这一步耐心等待完成即可。
安装成功后,直接执行qgis命令就可以打开传统的带界面的QGIS应用:
 图4
图4
但这并不是本文的重点,我们关注的是如何实现在jupyter lab里写代码调用QGIS功能,接下来我们来安装jupyter lab:
conda install nodejs jupyterlab -y
安装完成后我们执行jupyter lab来启动它:
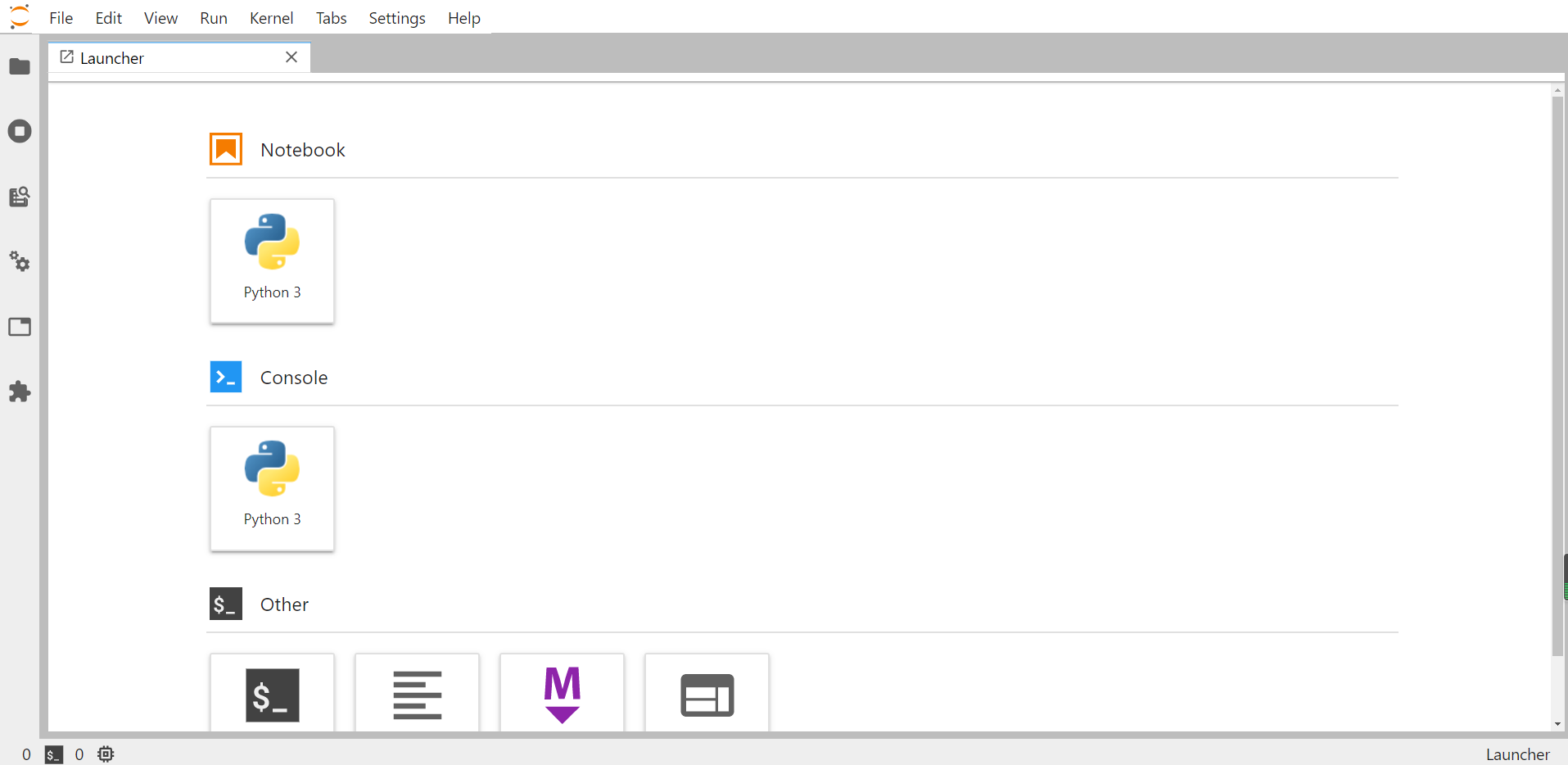 图5
图5
接着我们创建新的notebook,测试一下QGIS是否可以正确导入:
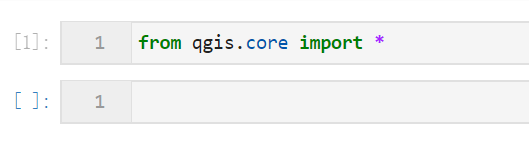 图6
图6
如果你可以成功执行上述代码,那么恭喜你已经完成了所有环境配置工作,因为是集成在conda虚拟环境中的,所以我们免去了所有配置QGIS相关路径的工作(爽翻了是不是~)。
为了方便下面的功能演示我们顺便把geopandas也安装了:
conda install -c conda-forge geopandas -y
接下来我们先来查看所有可用的QGIS中的算法功能:
# 查看可用的所有QGIS功能
from processing.core.Processing import Processing
from qgis.analysis import QgsNativeAlgorithms
Processing.initialize()
QgsApplication.processingRegistry().addProvider(QgsNativeAlgorithms())
for alg in QgsApplication.processingRegistry().algorithms():
print(alg.id(), "中的", alg.displayName(), '可用!')
输出的结果内容非常之多,可以说囊括了我们常用的所有QGIS功能,譬如渔网创建工具:
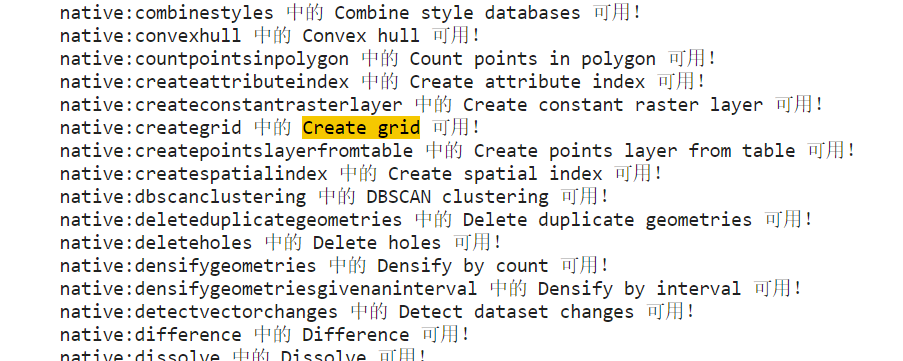 图7
图7
正好geopandas中没有现成的创建渔网功能,下面我们就以为重庆市创建渔网为例。
首先我们导入对应的重庆市域矢量文件,这里的可视化需要matplotlib和descartes两个库的支持,请确保已经安装好它们:
import geopandas as gpd
# 从矢量文件创建QGIS图层
chongqing = QgsVectorLayer('重庆市.geojson')
gpd.read_file('重庆市.geojson').plot();
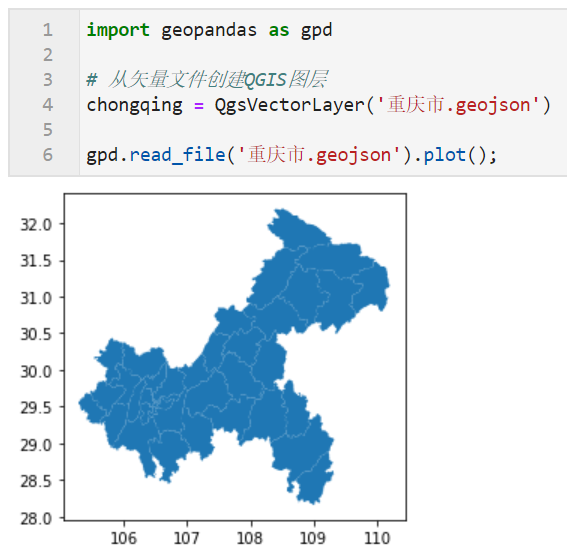 图8
图8
接着我们就需要使用到前面打印功能列表时看到的Create grid功能,通过下面的方式可以查看所有在功能列表中出现的算法:
from processing import algorithmHelp
# 查看渔网创建工具的说明文档
algorithmHelp("native:creategrid")
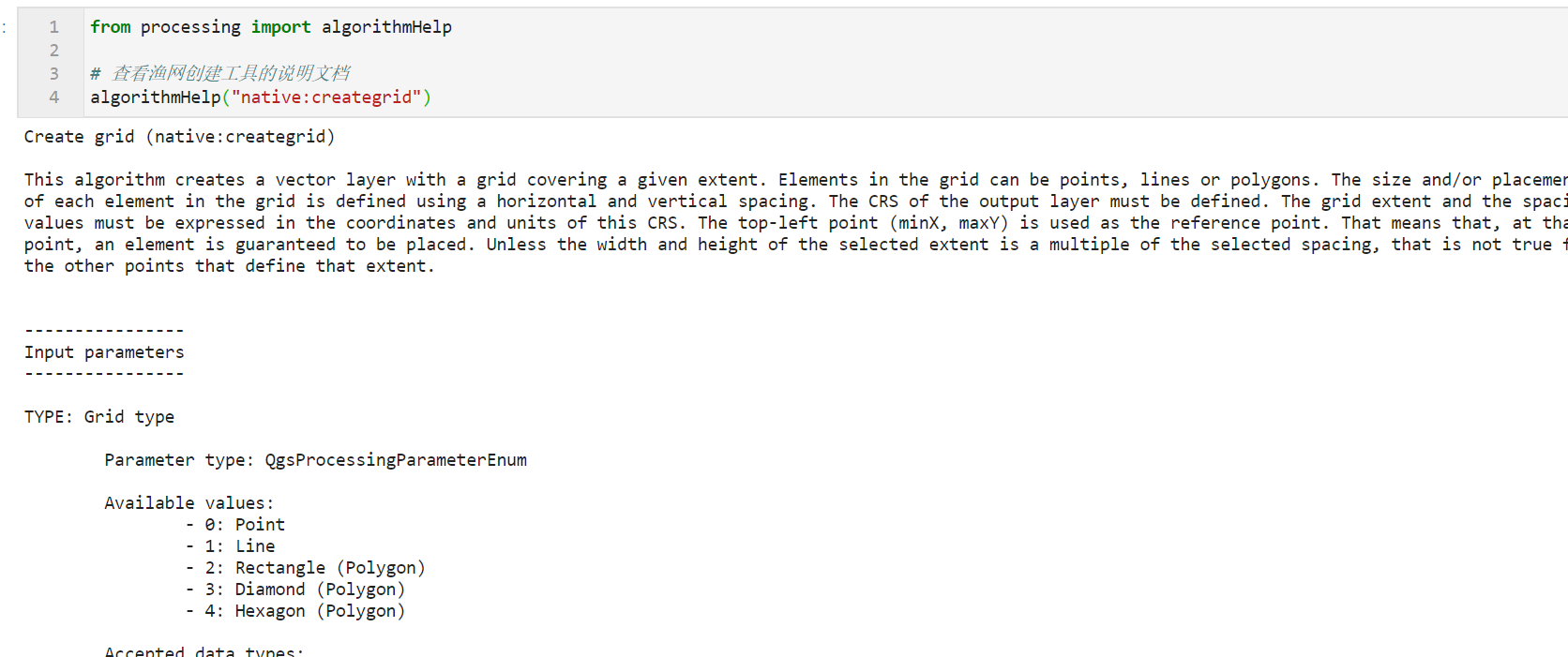 图9
图9
如果你使用过QGIS中的渔网创建工具,通过阅读上述的参数说明一定很快就能明白各个参数的意义,下面我们根据自己的需求创建10000x10000米的正方形渔网:
from processing import run
chongqing = gpd.read_file('重庆市.geojson')
# 获取投影坐标系下的bbox信息
total_bounds = chongqing.to_crs('EPSG:2381').total_bounds
params = {
'INPUT': chongqing,
'TYPE': 2,
'EXTENT': f'{total_bounds[0]},{total_bounds[2]},{total_bounds[1]},{total_bounds[3]}',
'HSPACING': 10000,
'VSPACING': 10000,
'HOVERLAY': 0,
'VOVERLAY': 0,
'CRS': 'EPSG:2381',
'OUTPUT': '重庆10000x10000渔网测试.geojson' # 导出到外部GeoJSON文件
}
feedback = QgsProcessingFeedback()
run("native:creategrid", params, feedback=feedback)
在QGIS中查看渔网结果:
 图10
图10
通过geopandas查看坐标参考系信息:
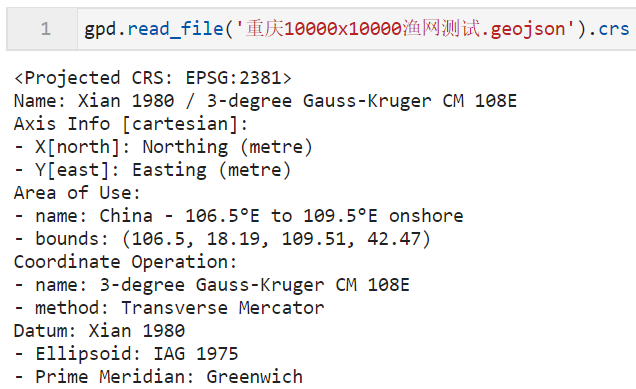 图11
图11
通过这样的方式,我们就可以实现在外部编辑器中灵活调用QGIS工具的目的。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札94)QGIS+Conda+jupyter玩转Python GIS的更多相关文章
- (数据科学学习手札81)conda+jupyter玩转数据科学环境搭建
本文示例yaml文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在使用Python进行数据分析时,很 ...
- (数据科学学习手札64)在jupyter notebook中利用kepler.gl进行空间数据可视化
一.简介 kepler.gl是由Uber开发的进行空间数据可视化的开源工具,是Uber内部进行空间数据可视化的默认工具,通过其面向Python开放的接口包keplergl,我们可以在jupyter n ...
- (数据科学学习手札95)elyra——jupyter lab最强插件
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 jupyter lab是我最喜欢的编辑器,在过往 ...
- (数据科学学习手札95)elyra——jupyter lab平台最强插件集
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 jupyter lab是我最喜欢的编辑器,在过往 ...
- (数据科学学习手札08)系统聚类法的Python源码实现(与Python,R自带方法进行比较)
聚类分析是数据挖掘方法中应用非常广泛的一项,而聚类分析根据其大体方法的不同又分为系统聚类和快速聚类,其中系统聚类的优点是可以很直观的得到聚类数不同时具体类中包括了哪些样本,而Python和R中都有直接 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
随机推荐
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
- jieba尝鲜
import jieba strings = '我工作在安徽的安徽师范大学,这个大学很美丽,在芜湖' # print(dir(jieba)) dic_strings = {} lst_strings ...
- PDOStatement::execute
PDOStatement::execute — 执行一条预处理语句(PHP 5 >= 5.1.0, PECL pdo >= 0.1.0) 说明 语法 bool PDOStatement:: ...
- 通过缓存Cache记录命中率
import org.apache.juli.logging.Log; /** * 通过此Cache记录命中率 * @author Administrator * */ public class Lo ...
- js的栈内存和堆内存
栈内存和堆内存在了解一门语言底层数据结构上,挺重要的,做了个总结 JS中的栈内存堆内存 JS的内存空间分为栈(stack).堆(heap).池(一般也会归类为栈中). 其中栈存放变量,堆存放复杂对象, ...
- Linux服务器配置SSH免密登录
SSH为Secure Shell的缩写,由IETF的网络小组(Network Working Group)所制定:SSH为建立在应用层基础上的安全协议.SSH是目前较可靠,专为远程登录会话和其他网络服 ...
- [转]17个常用的JVM参数
作者:SimpleSmile_5177 来源:https://www.cnblogs.com/Simple-Object/p/10272326.html 前言 大家都知道,jvm在启动的时候,会执行默 ...
- Android VideoView未解决,动态读取权限、BottomNavigationView的用法
昨天想写的,但是因为Video的毛病,是真找不出为啥了.百度也没用,学长也不清楚. 百度了那么久,大概得出结论,电脑的视频是不能用它来播放的... ..经过两天的奋斗,我居然搞定了,我的视频终于出来了 ...
- Python高性能HTTP客户端库requests的使用
Python中有许多HTTP客户端.使用最广泛且最容易的是requests. 持续连接 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很 ...
- (转载+新增)Win7下安装配置gVim
转载自 http://www.cnblogs.com/zhcncn/p/4151701.html.而后安装过程中加入自己遇到的问题解决方案. 本文根据vim官网的<Simple Steps to ...