requests 库和beautifulsoup库
python 爬虫和解析
库的安装:pip install requests; pip install beautifulsoup4
requests 的几个常用方法:
requests.request() #以下各方法的基础
requests.get(url,params=None,**kwargs) #获取html内容
requests.head() #获取网页头部内容
requests.post()
requests.put()
requests.patch()
requests.delete()
重点为:get()其有12个控制关键字参数 返回为response对象
r.status_code #200为正常
r.text #html内容
r.encoding 编码
r.apparent_encoding 备选编码
r.content 二进制形式返回,爬取 图片,视频,音频等的关键
常使用try,except框架
import requests
import os
url = 'http://image.ngchina.com.cn/2018/1010/20181010031434134.jpg'
root = 'd://pics//'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except:
print('失败')
import requests
import os
url = 'http://mov.bn.netease.com/open-movie/nos/mp4/2016/05/16/SBM8NN8G6_shd.mp4'
root = 'd://vidio//'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(url)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except:
print('失败')
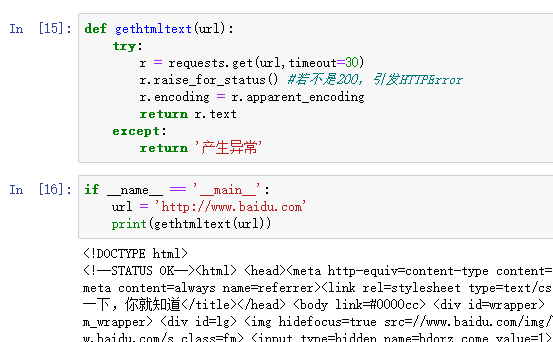
1 import requests
2 from bs4 import BeautifulSoup
3 import bs4
4 def gethtmltext(url):
5 try:
6 r = requests.get(url,timeout=30)
7 r.raise_for_status()
8 r.encoding=r.apparent_encoding
9 return r.text
10 except:
11 return ''
12
13
14 def fillunivlist(ulist,html):
15 soup = BeautifulSoup(html,'html.parser')
16 for tr in soup.find('tbody').children:
17 if isinstance(tr,bs4.element.Tag):
18 tds = tr('td')
19 ulist.append([tds[0].string,tds[1].string,tds[2].string])
20
21 def printunivlist(ulist,num):
22 print('{:^10}\t{:^6}\t{:^10}'.format('排名','学校名称','总分'))
23 for i in range(num):
24 u=ulist[i]
25 print('{:^10}\t{:^6}\t{:^10}'.format(u[0],u[1],u[2]))
26
27
28 def main():
29 uinfo = []
30 url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
31 html = gethtmltext(url)
32 fillunivlist(uinfo,html)
33 printunivlist(uinfo,20)
34
35 main()
查看爬虫协议在最后加上robots.txt 如:www.jd.com/robots.txt
Beautiful Soup库 #解析网页用
BeautifulSoup(text,'html.parser')
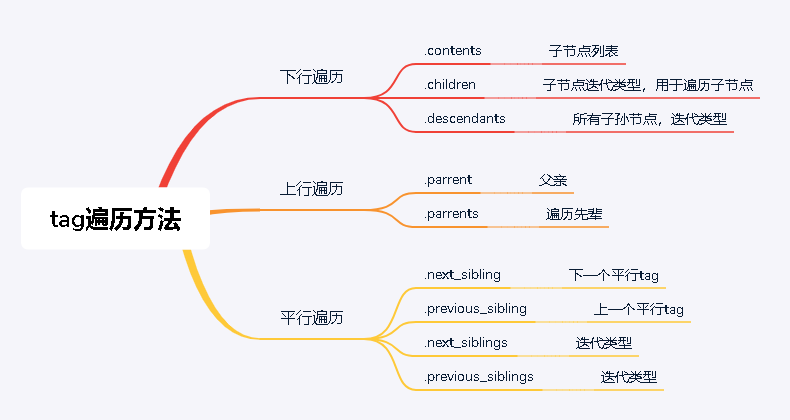
SOUP库的基本元素:
Tag 标签,最基本的信息单元,对应<>....</>
Name 标签名
attributes 标签属性:Tag.attrs
Navigablestring 标签内非属性字符串<>....</>中的字符串 格式:Tag.string
Comment 标签的注释部分
如:<p class='title'>.....</p> p标签
p.name p.attrs p.string
requests 库和beautifulsoup库的更多相关文章
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
Python:requests库.BeautifulSoup4库的基本使用(实现简单的网络爬虫) 一.requests库的基本使用 requests是python语言编写的简单易用的HTTP库,使用起 ...
- BeautifulSoup库整理
BeautifulSoup库 一.BeautifulSoup库的下载以及使用 1.下载 pip3 install beautifulsoup4 2.使用 improt bs4 二.BeautifulS ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
- 利用python的requests和BeautifulSoup库爬取小说网站内容
1. 什么是Requests? Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库. 它比urllib更加方便,可以节约 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- 网络爬虫BeautifulSoup库的使用
使用BeautifulSoup库提取HTML页面信息 #!/usr/bin/python3 import requests from bs4 import BeautifulSoup url='htt ...
- 基于BeautifulSoup库的HTML内容的查找
一.BeautifulSoup库提供了一个检索的参数: <>.find_all(name,attrs,recursive,string,**kwargs),它返回一个列表类型,存储查找的结 ...
随机推荐
- nginx特性
nginx特点: 更快,高扩展性,高可靠性,低能耗性,单机支持10w以上的并发连接,热部署,自由的BSD, Apache.Lighttpd.Tomcat.Jetty.IIS,它们都是Web服务器 SN ...
- 转载:pycharm IDE 导入自定义模块
http://www.mamicode.com/info-detail-2241193.html
- ElasticSearch 简单的crud查询
//数据库和es的对应关系(学习文档可以参考https://es.xiaoleilu.com/010_Intro/35_Tutorial_Aggregations.html) //如下接口调用都是使用 ...
- Python-开发规范-遵循PEP8规范
Python中空白 1. 4个空格表示缩进,用4个空格代替一个TAB 2. 不再逗号.分号.冒号前加空格,应该在其后加空格 3. 关系运行符.数学运算符.逻辑运算符.赋值运算符 前后都加一个空格 4. ...
- 国产化之路-安装达梦DM8数据库
专题目录 国产化之路-统信UOS操作系统安装 国产化之路-国产操作系统安装.net core 3.1 sdk 国产化之路-安装WEB服务器 国产化之路-安装达梦DM8数据库 国产化之路-统信UOS + ...
- JavaScript innerTHML和createElement效率对比
前言: 在DOM节点操作中,innerTHML和createElement都可以实现创建元素.它们实现的功能类似,但是效率却相差很大.本文分别统计用innerTHML字符串拼接方式.innerTHML ...
- springcloud学习入门
Springcloud入门学习笔记 1. 项目初始化配置 1. 1. 新建maven工程 使用idea创建maven项目 1. 2. 在parent项目pom中导入以下依赖 <parent> ...
- kubernetes-介绍与特性
1. kubernetes概述 1) kubernetes是什么 2) kubernetes能做什么 3) kubernetes特性 4) kubernetes集群架构与组件 5) kubernete ...
- Jenkins从节点上构建自动化测试项目时报错:java.io.IOException: Unexpected termination of the channel
在mac电脑上配置了Jenkins从节点,在该从节点上构建app UI 自动化测试项目,运行一些用例后报如下错误: java.io.EOFException at java.io.ObjectInpu ...
- OpenCV计算机视觉学习(4)——图像平滑处理(均值滤波,高斯滤波,中值滤波,双边滤波)
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice &q ...