【Scrapy笔记】使用方法
安装:
1、pip install wheel 安装wheel
2、安装Twisted
a.访问 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载Twisted-17.9.0-cp36-cp36m-win_amd64.whl
b.进入文件所在目录 pip install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
3、pip3 install scrapy 安装scrapy
使用:
1、scrapy startprojec 项目名称 创建项目
2、 cd 项目名称 进入项目目录
3、scrapy genspider xxx xxx.com 创建爬虫文件 例如,要创建oppo爬虫文件,则scrapy genspider oppo www.oppo.cn
4、scrapy crawl xxx 运行爬虫文件 在当前目录下,运行oppo爬虫 scrapy crawl oppo
5、scrapy crawl xxx -o file.json 运行爬虫,并把文件存放到指定文件中,多用来调试!
注意事项:去settings .py 中注释掉 ROBOTSTXT_OBEY = True (如项目无其他侵权功能,则可以注释“鉴别是否允许爬取”)
域名有www 则需要加上www, 如果当前页面添加ssl加密传输,则需要去oppo.py中修改http为https
重点:yield下 ,callback如果不指定回调函数,则默认结束时,会回调一次parse
调试方法:
scrapy shell 域名
scrapy shell -s USER_AGENT="Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" 域名 注意: 调试中增加请求头,USER_AGENT=后面必须是英文状态下的双引号,单引号会报错
scrapy shell https://www.oppo.cn
scrapy shell https://www.oppo.cn/topic/index/thread.json?page=1&limit=20&type=3&id=856
域名后面&换行后无法连接成整个域名,则可: scrapy shell "www.oppo.cn/topic/index/thread.json?page=1&limit=20&type=3&id=856" 去掉"https://"
CSS选择器使用
response.css("#ID dt::text") 提取文本信息
response.css('.class p::attr(href)').extract() 提取属性信息 显示所有
response.css('.class p::attr(href)').extract_first() 提取属性信息 显示第一条
html对象转换:
import parsel
data=parsel.Selector(html_str)
Spider 注意事项:
allowed_domains = ['qiushibaike.com'] 这是正确匹配规则,
错误示范:
1 、allowed_domains = ['www.qiushibaike.com'] 主域名前面添加 www
2 、allowed_domains = ['qiushibaike.com/text'] 主域名后面添加多余页码
创建crawl_spider
1、scrapy startproject 项目名称
2、cd 项目名称
3、scrapy genspider xxx -t crawl xxx '域名'
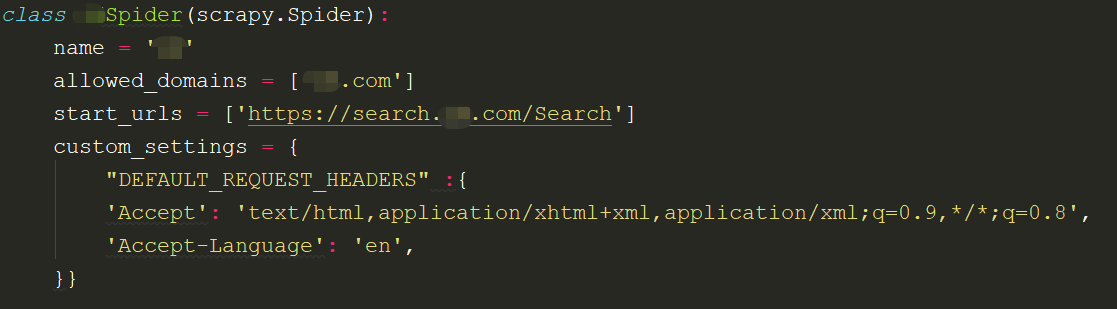
Spider
关于Spider的使用方法:
name='xx'
name必须是唯一的
allowed_domains=['xxxx.com']
设置爬虫的规则,url不在规则范围之内的,不予爬取
start_urls=['xxxxx.com']
初始url链接
custom_srttings
它是一个字典,是专属于spider的配置,此方法会覆盖全局的配置,此设置必须在初始化前更新,必须定义类变量
GET

POST

crawl_Spider
创建crawl_spider 的方法:
scrapy startproject xxx
cd xxx
scrapy genspider -t crawl xxx xxx.xom
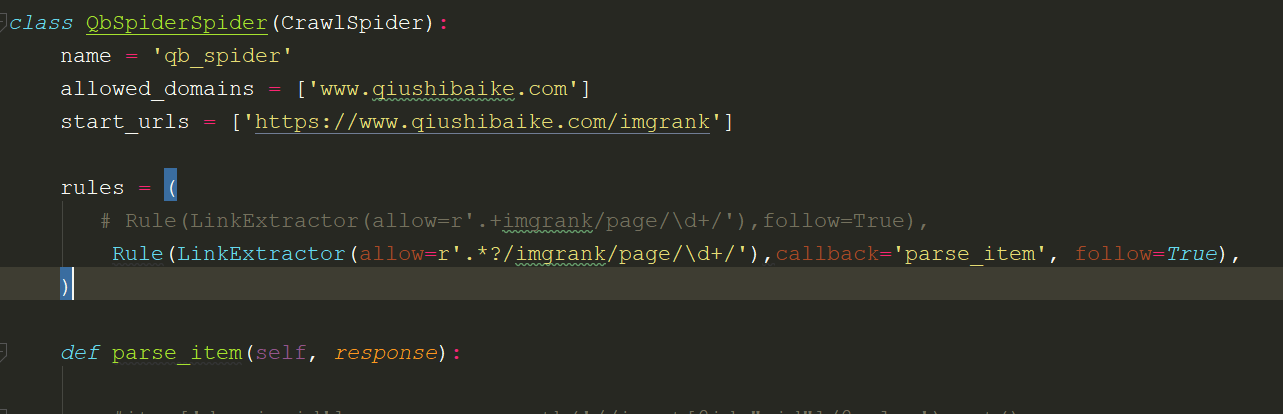
LinkExtractors链接提取器:


Settings
关于settings调用到方法:
1.在spider.py文件中,可以直接使用 self.settings.get('XXX') 获取
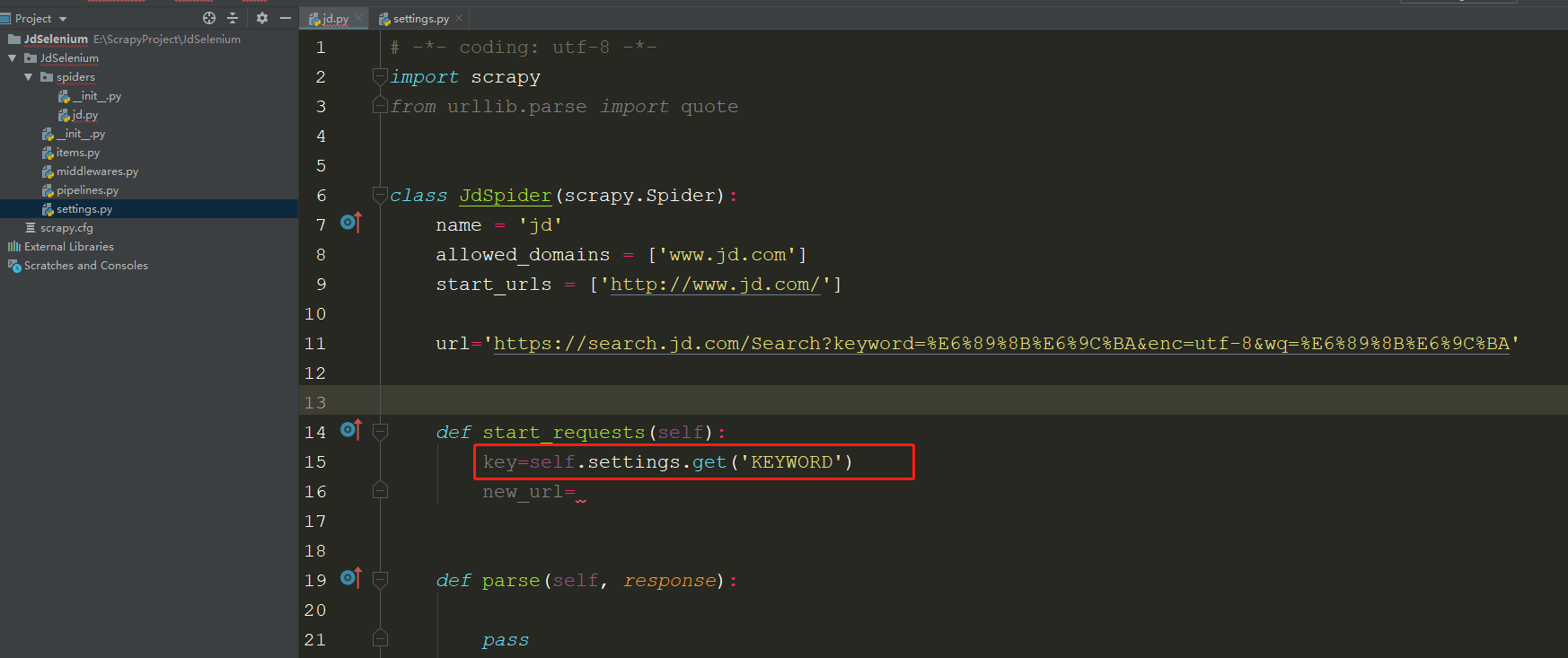
2.在Middleware中使用settings的方法:

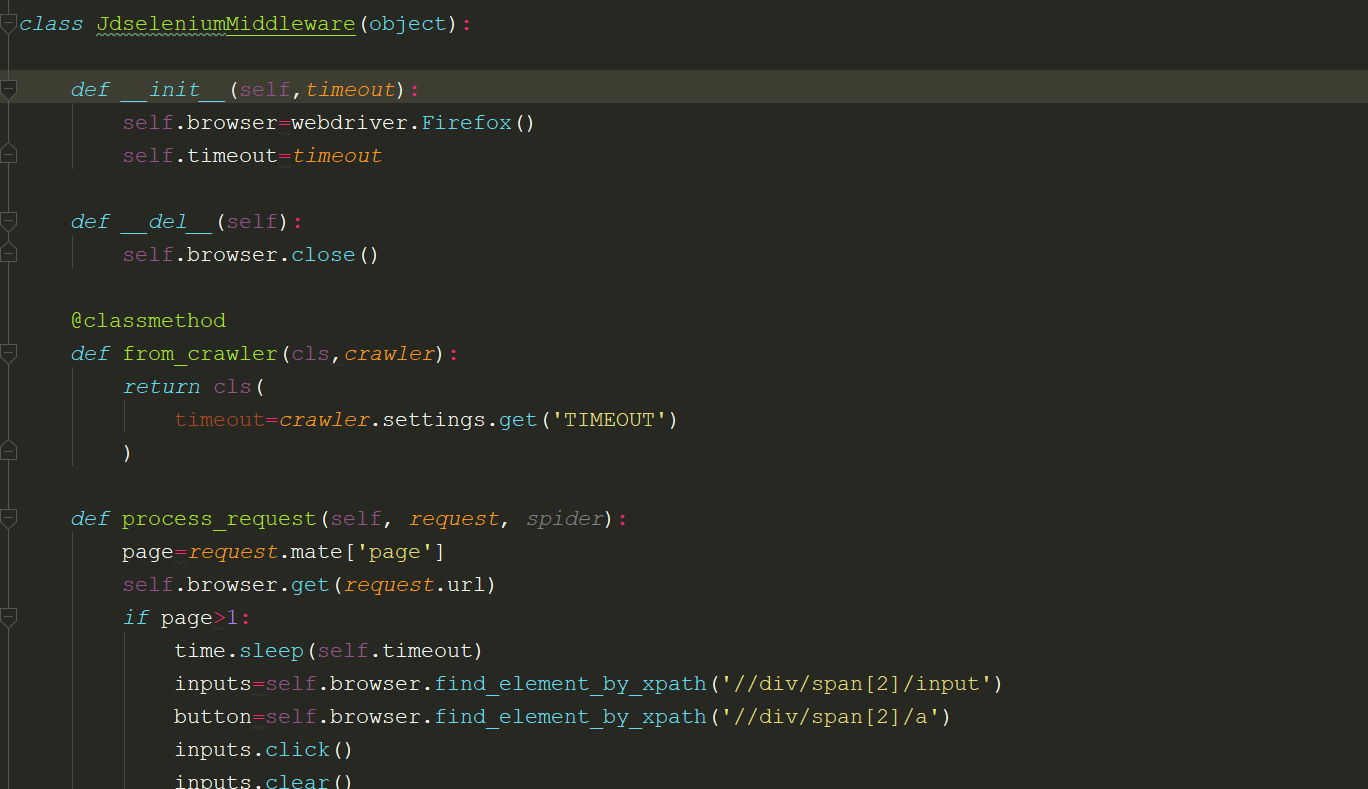
MiddleWares
在middlewares中修改response下载器为selenium的方法:
注意事项:需要在settings中将downloader_middlewares反注释,并将红色文字部分修改成你的middlewares类名:
DOWNLOADER_MIDDLEWARES = {
'JdSelenium.middlewares.JdseleniumMiddleware': 543,
}
如果要修改下载中间件,则需要使用start_requests方法

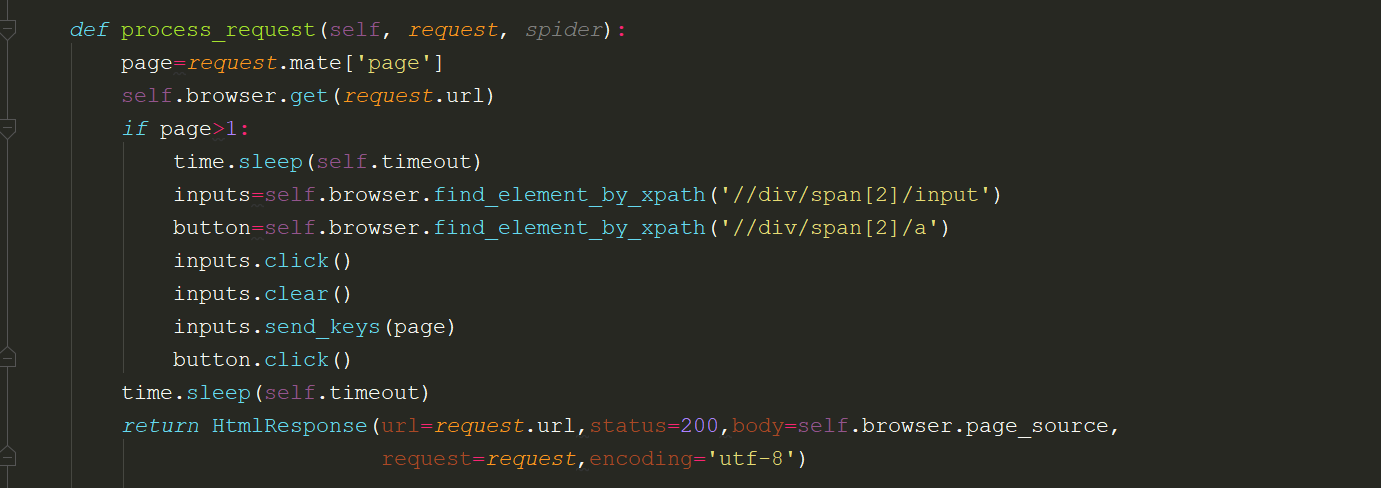
添加IP代理池
Httpbin.org相关测试接口
https://blog.csdn.net/chang995196962/article/details/91362364
ip代理:https://www.xicidaili.com/wt/
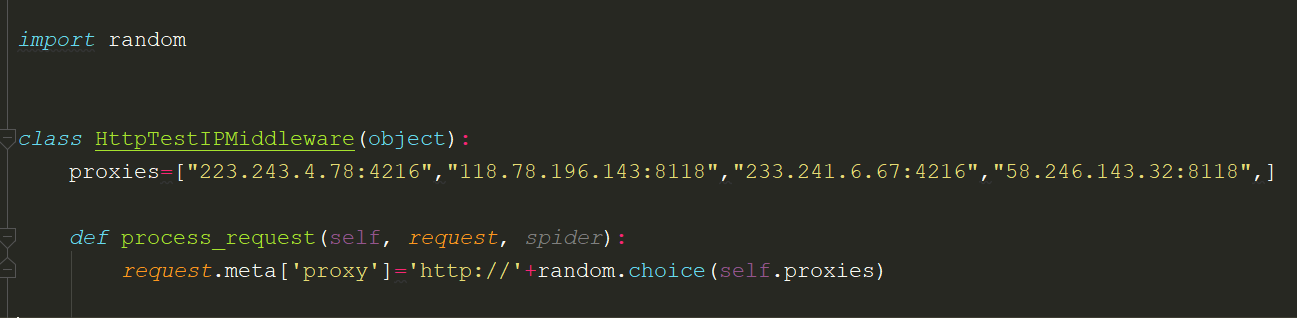
校验IP不可用后,更换IP代理
requests中添加ip代理,一定要使用字典格式,否则就会报错
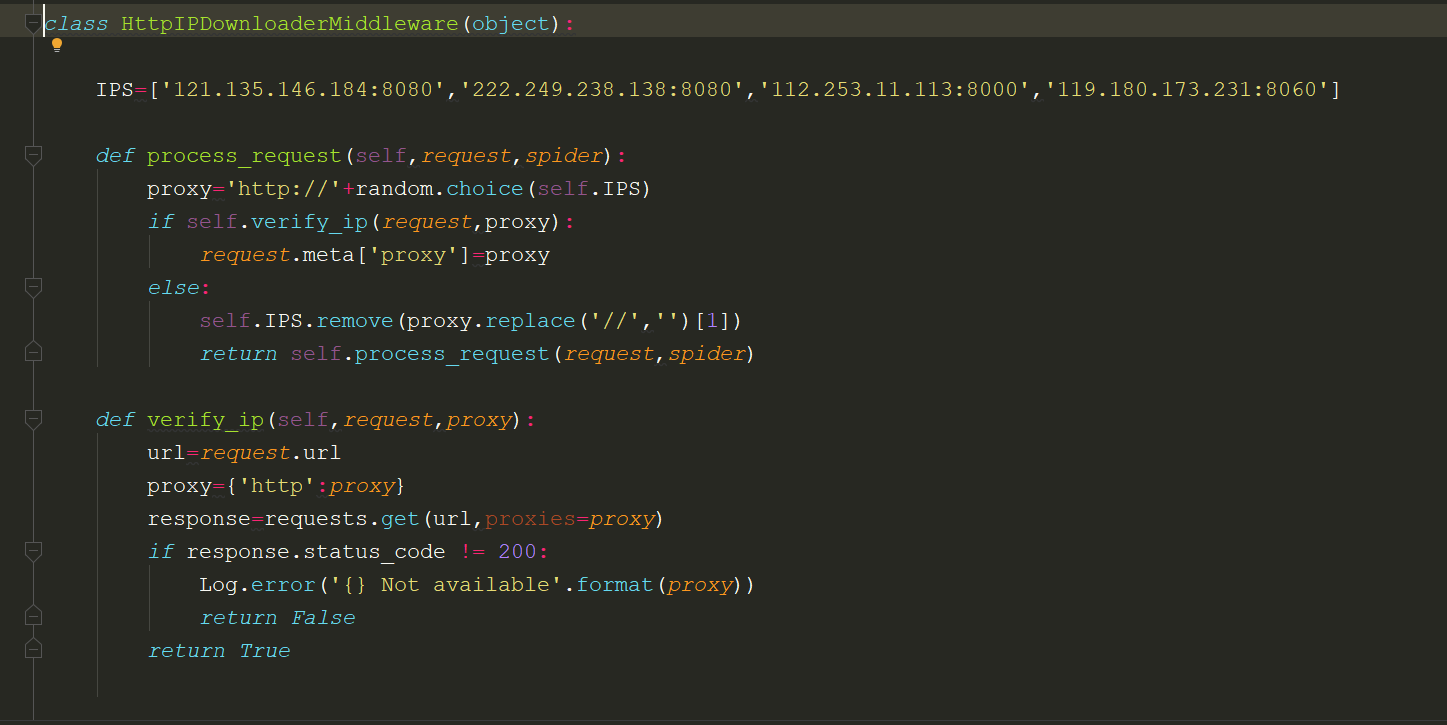
添加随机请求头
User_Agent 集合:http://useragentstring.com/pages/useragentstring.php
Pipeline
Scrapy.imagesPipeline:
不论是FILES_STORE 还是IMAGE_STORE,路径一定要懂'\' 来表示: IMAGES_STORE='D:\IM'
下载文件的 Files Pipeline :
当时用 Files Pipeline 下载文件的时候,按照以下步骤完成:
1.定义好一个Item,然后在这个item中定义两个属性,分别为 file_urls以及files。file_urls 用来存储需要下载的文件的url链接,需要给一个列表
file_urls=scrapy.Field()
files=scrapy.Field()
2.当文件下载完成后,会把文件下载的相关信息存储到item 的files属性中,比如下载路径,下载的url和文件的校验码等。
3.在配置文件 settings.py 中配置 FILES_STORE,这个配置是用来设置下载下来的路径
4.启动pipeline: 在settings.py中的ITEM_PIPELINES中设置 scrapy.pipelines.files.FilesPipeline:1
下载图片的 Images Pipelins:
当时用 Files Pipeline 下载文件的时候,按照以下步骤完成:
1.定义好一个Item,然后在这个item中定义两个属性,分别为 file_urls以及files。file_urls 用来存储需要下载的文件的url链接,需要给一个列表
image_urls=scrapy.Field()
images=scrapy.Field()
2.当文件下载完成后,会把文件下载的相关信息存储到item 的images属性中,比如下载路径,下载的url和文件的校验码等。
3.在配置文件 settings.py 中配置 IMAGES_STORE,这个配置是用来设置下载下来的路径
4.启动pipeline: 在settings.py中的ITEM_PIPELINES中设置 scrapy.pipelines.images.ImagesPipeline:1
在settings中设置plpelines,


当要修改下载路径或者文件加名称从被爬取的网页中获取时,当重写父类方法:
from scrapy.pipelines.images import ImagesPipeline
from QB import settings
import os
class QbImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 这个方法是在发送下载请求之前调用
# 其实这个方法本身就是去发送下载请求的
request_objs = super(QbImagesPipeline, self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None):
path = super(QbImagesPipeline, self).file_path(request, response, info)
# 文件路径分类,从item中拿到的文件夹名称,一般是从网上获取的名称
category = request.item.get('category')
images_store = settings.IMAGES_STORE
# 将settings中设置的路径与item中的路径拼接
category_path = os.path.join(images_store, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
# 将父类中的路径分割,得到图片名称
image_name = path.replace('full/', '')
image_path = os.path.join(category_path, image_name)
return image_path
Plpeline Mysql数据存储
同步IO存储
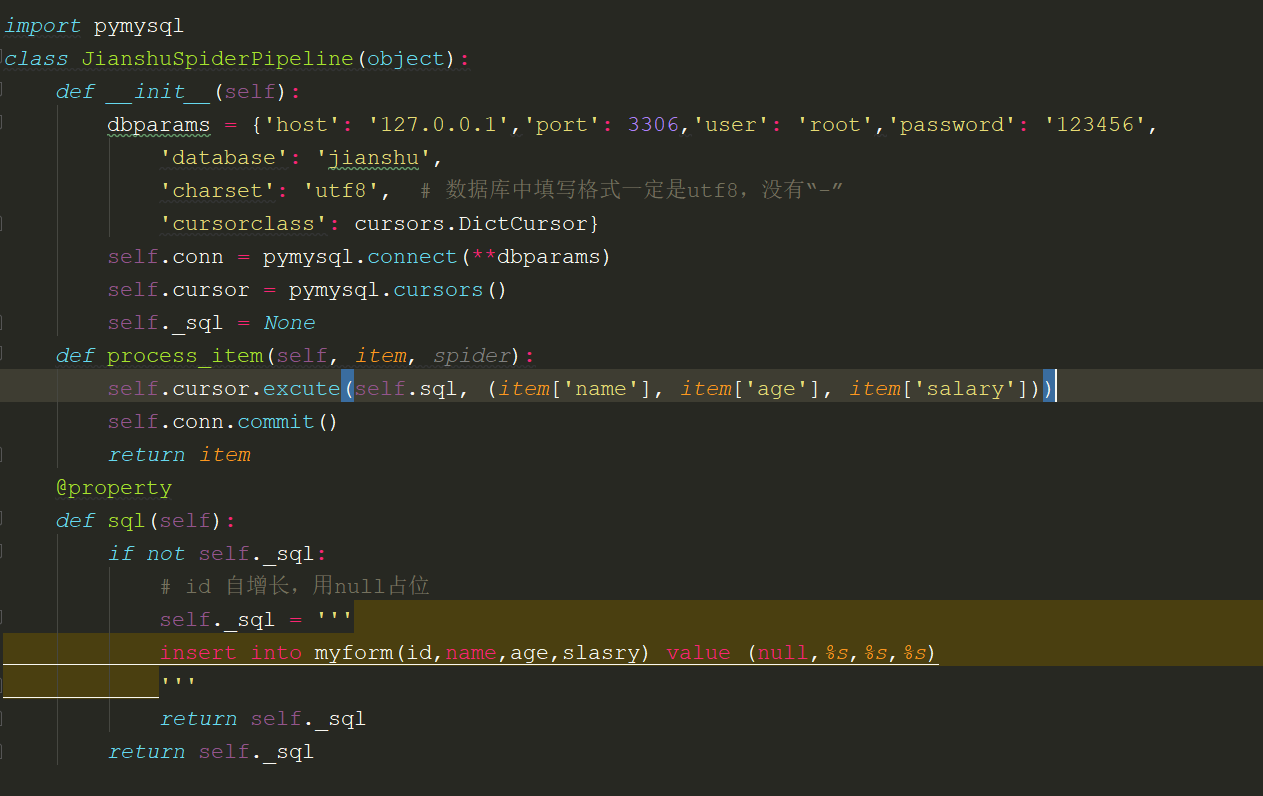
异步IO存储

【Scrapy笔记】使用方法的更多相关文章
- Learning Scrapy笔记(六)- Scrapy处理JSON API和AJAX页面
摘要:介绍了使用Scrapy处理JSON API和AJAX页面的方法 有时候,你会发现你要爬取的页面并不存在HTML源码,譬如,在浏览器打开http://localhost:9312/static/, ...
- 转 Scrapy笔记(5)- Item详解
Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API,并且可以很方便的声明字段,很多Scra ...
- Scrapy笔记(1)- 入门篇
Scrapy笔记01- 入门篇 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说, ...
- Scrapy笔记02- 完整示例
Scrapy笔记02- 完整示例 这篇文章我们通过一个比较完整的例子来教你使用Scrapy,我选择爬取虎嗅网首页的新闻列表. 这里我们将完成如下几个步骤: 创建一个新的Scrapy工程 定义你所需要要 ...
- Scrapy笔记03- Spider详解
Scrapy笔记03- Spider详解 Spider是爬虫框架的核心,爬取流程如下: 先初始化请求URL列表,并指定下载后处理response的回调函数.初次请求URL通过start_urls指定, ...
- Scrapy笔记04- Selector详解
Scrapy笔记04- Selector详解 在你爬取网页的时候,最普遍的事情就是在页面源码中提取需要的数据,我们有几个库可以帮你完成这个任务: BeautifulSoup是python中一个非常流行 ...
- Scrapy笔记05- Item详解
Scrapy笔记05- Item详解 Item是保存结构数据的地方,Scrapy可以将解析结果以字典形式返回,但是Python中字典缺少结构,在大型爬虫系统中很不方便. Item提供了类字典的API, ...
- Scrapy笔记06- Item Pipeline
Scrapy笔记06- Item Pipeline 当一个item被蜘蛛爬取到之后会被发送给Item Pipeline,然后多个组件按照顺序处理这个item. 每个Item Pipeline组件其实就 ...
- Scrapy笔记07- 内置服务
Scrapy笔记07- 内置服务 Scrapy使用Python内置的的日志系统来记录事件日志. 日志配置 LOG_ENABLED = true LOG_ENCODING = "utf-8&q ...
- Scrapy笔记08- 文件与图片
Scrapy笔记08- 文件与图片 Scrapy为我们提供了可重用的item pipelines为某个特定的Item去下载文件. 通常来说你会选择使用Files Pipeline或Images Pip ...
随机推荐
- flink1.10版本StreamGraph生成过程分析
1.StreamGraph本质 本质就是按照用程序代码的执行顺序构建出来的用于向执行环境传输的流式图,并且可以支持可视化展示给用户的一种数据结构. 2.StreamGraph.StreamNode和S ...
- 04、MyBatis DynamicSQL(Mybatis动态SQL)
1.动态SQL简介 动态 SQL是MyBatis强大特性之一. 动态 SQL 元素和使用 JSTL 或其他类似基于 XML 的文本处理器相似. MyBatis 采用功能强大的基于 OGNL 的表达式来 ...
- powershell过杀软工具-xencrypt
在红队攻击中,绕杀软是一个比较常见的技术.对于绕过杀软的方法,有基于黑白名单的,有基于shellloader的,也有基于加密与混淆的.最近在发现了这样一款过杀软的工具,推荐给有缘人,嘻嘻 ...
- redhat-DHCP服务的配置与应用
DHCP服务器为客户端提供自动分配IP地址的服务,减轻网管的负担 首先 rpm -q dhcp 查看是否安装dhcp yum -y install dhcp进行安装 安装完成 dhcp服务配置 dhc ...
- 兄弟萌,这份SpringMVC框架学习笔记真的建议反复看,写的太细了
概述 是Spring为展现层提供的基于MVC设计理念的Web框架,通过一套MVC注解,让POJO成为处理请求的控制器,而无需实现任何接口 支持REST风格的URL请求 采用松散耦合的可插拔组件结构,比 ...
- pandas 对时间索引进行分割
截取最近1个月时间,截取最近一段时间,进行统计分析 df.loc["2016-01-05":"2016-02-05",:].tail() 在index为有序数据 ...
- Linux高可用之Keepalived
1: 安装keepalived yum install -y keepalived ipvsadm 安装keepalived和LVS管理软件ipvsadm 主机与备机都需要安装 ######修改配置文 ...
- 机场&代理商-关系图
机场&代理商-关系图 思路 ①首先统计机场活跃度Top10的机场名称,以下是我的表结构,以及查询语句 表结构: 查询语句:SELECT * from 2020csale ORDER BY cn ...
- redis面试问题(二)
1.redis和其他缓存相比有哪些优点呢 见上一篇 2. 你刚刚提到了持久化,能重点介绍一下么 见上一篇 3.Redis中对于IO的控制做过什么优化? pipeline? 4 有没有尝试进行多机red ...
- 在HTML中调用打开摄像头
1 <img src="imgs/qr.png" alt=""> 2 <video src=""></vide ...