Hadoop核心-HDFS
上一篇我们熟悉了hadoop,本篇讲解一下hadoop第一个核心HDFS。
一.概述
HDFS是一个分布式文件存储系统,以流式数据访问模式存储超大文件,将数据分块存储到一个商业硬件集群内的不同机器上,通过目录树来定位文件,由多台服务器联合起来实现其功能,集群中的服务器有各自的角色。HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,不适合做网盘应用。
二.优缺点
1.优点:
*高容错性。数据自动保存多个副本,通过增加副本的形式,来提高容错性。当某一副本丢失后可以自动回复;
*适合处理大数据。能够处理GB、TB、PB级别的数据和百万以上的文件数量;
*可构建在廉价机器上,通过多副本机制,提高可靠性。
2.缺点:
*不适合低延时数据访问。毫秒级的存储数据做不到;
*无法高效的对大量小文件进行存储。它会占用namenode大量的内存来存储文件目录和块信息,但namenode内存是有限的;
*不支持并发写入和文件随机修改,仅支持数据追加。
三.组成
*NameNode(nn):主机器,管理HDFS的命名空间,存储元数据(包括ip,路径等数据的信息);
*DataNode:存储实际的数据块,执行数据块的读写操作;
*Secondary NameNode(2nn):并非namenode的热备,辅助namenode,分担其工作量,定期合并映射信息和日志推送给namenode;
*Client:客户端,文件的切分、与namenode交互等。
四.文件块大小
HDFS中的文件在物理上是分块存储的,块的大小可以通过配置参数来改变,修改hdfs-site.xml文件中的dfs.blocksize对应的值,hadoop2.x版本默认大小为128M,之前为64M。块的大小不能随机设置,太大会导致程序在处理块数据时非常慢,太小会增加寻址时间,一直在找块的开始位置。HDFS块的大小设置主要取决于磁盘传输速率。
五.数据流
1.读数据流:
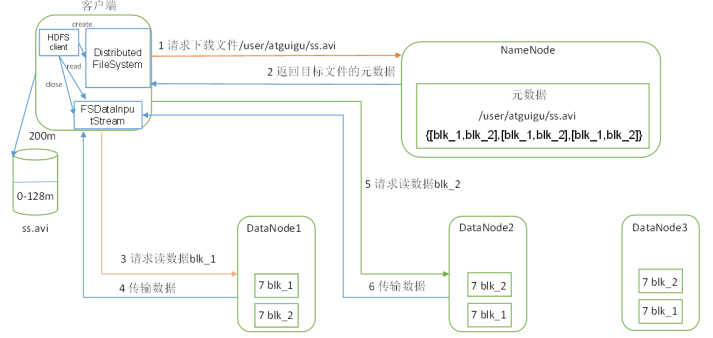
*客户端通过 Distributed FileSyatem 向namenode 请求下载文件,namenoce通过查询元数据,找到文件块所在的datanode地址;
*挑选一台最近的datanode(就近原则)服务器,请求读取数据;
*datanode开始传输数据给客户端(从磁盘读取数据输入流,以packet为单位来做校验);
*客户端以packet为单位来接收,现在本地缓存,然后写入到目标文件中。
2.写数据流:
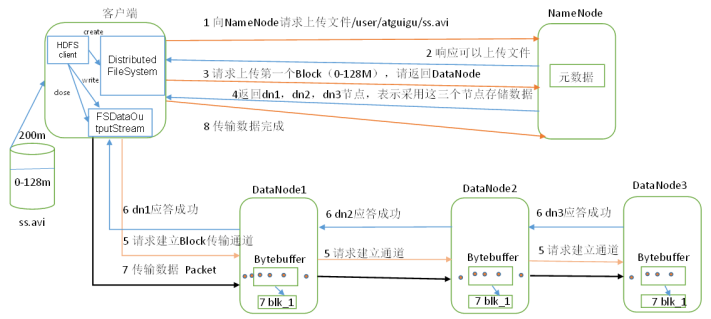
*客户端通过 Distributed FileSyatem对象中的create函数来创建一个文件,向namenode请求上传文件,通过RPC调用在namenode命名空间中创建一个新文件;
*NameNode通过多种校验该目标文件是否存在,并确保客户端拥有创建文件的权限,当通过所有验证后,namenode会创建一个文件来记录此信息,Distributed FileSyatem会返回一个文件输出流FSDataOutputStream来供客户端写入数据,客户端通过此来建立datanode和namenode之间的通信;
*客户端请求第一个Block上传到哪几个datanode服务器上,namenode返回三个datanode节点分别为dn1、dn2、dn3;
*FSDataOutputStream请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将通信管道建立完成;
*各个dn逐级应答客户端;
*客户端开始往dn1上传第一个Block,dn1接收到就会传给dn2,以此类推,知道最后一台datanode服务器;
*在上传时,FSDataOutputStream会保存一个副包,用来等待其他包返回成功写入消息后删除副包。
六.数据副本存放策略与读取策略
1.存放策略:HDFS采用一种称为机架感应的策略来改进数据的可靠性、可用性和网络带宽的利用率,默认的副本系数是3,将第一个副本存放在本地机架的节点上,将第二个副本存放在同一机架的另一个节点上,将第三个副本存放在不同机架的节点上。减少了机架间的数据传输,提高了写操作效率,机架的错误远远比节点的错误少,不会影响数据的可靠性和可用性。
2.读取策略:因为数据块只放在两个(不是三个)不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。为了降低整体的带宽消耗和读取延迟,HDFS尽量会让程序读取离它最近的副本(就近原则),如果读取时同一个机架上有一个副本,那么读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端首先读取本地数据中心的副本。
七.DataNode
1.工作机制:
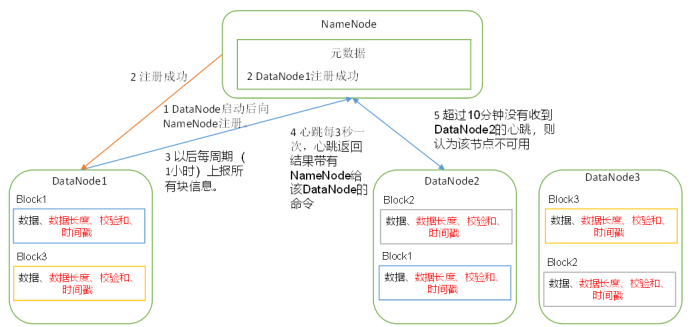
*一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件:一个是数据本身,一个是元数据(数据长度、校验和...);
*datanode启动后向namenode注册,通过后,周期性(1h)的向namenode上报所有块信息;
*每3s发一次心跳(带有namenode给该datanode的命令,如复制块数据到另一台机器上),如果超过10分钟没收到datanode的心跳,则认为该节点不可用;
*集群运行中可以安全加入和退出一些机器。
2.数据完整性:
*当datanode读取Block的时候,它会计算CheckSum校验和;
*如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏;
*Client读取其他datanode上的Block;
*datanode在其创建文件后周期验证CheckSum校验和。
八.NameNode / Secondary NameNode
1.工作机制:

第一阶段:
*第一次启动namenode格式化后,创建Fsimage(镜像文件)和Edits(编辑日志)。如果不是第一次,直接加载镜像文件和编辑日志到内存;
*客户端对元数据进行增删改查的请求;
*namenode记录操作日志,更新滚动日志;
*namenode在内存中对元数据进行增删改查。
第二阶段:
*secondary namenode 询问namenode 是否需要CheckPoint检查站,直接带回namenode是否检查结果;
*secondary namenode请求执行CheckPoint;
*namenode滚动正在写的edits编辑日志;
*将滚动前的编辑日志和镜像文件拷贝到secondary namenode;
*secondary namenode加载编辑日志和镜像文件到内存中并合并;
*生成新的镜像文件fsimage.chkpoint,拷贝到namenode;
*namenode将fsimage.chkpoint重命名为fsimage。
2.Fsimage和Edits
*Fsimage镜像文件:HDFS文件系统元数据的一个永久性检查点,其中包含HDFS文件系统的所有目录和文件inode的序列化信息;
*Edits:存放HDFS文件系统的所有更新操作路径,文件系统客户端执行的所有写操作首先会被记录到Edits文件中。
*每次namenode启动时都会将Fsimage文件读入内存,加载Edits里面的更新操作,保证内存中的元数据信息是最新的、同步的。可以看成namenode启动时就将fsimage和edits文件进行合并。
下一篇我们接着讲关于hadoop第二个核心-MapReduce分布式计算。
Hadoop核心-HDFS的更多相关文章
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- hadoop之HDFS核心类Filesystem的使用
1.导入jar包,要使用hadoop的HDFS就要导入hadoop-2.7.7\share\hadoop\common下的3个jar包和lib下的依赖包.hadoop-2.7.7\share\hado ...
- 【Hadoop】HDFS - 创建文件流程详解
1.本文目的 通过解析客户端创建文件流程,认知hadoop的HDFS系统的一些功能和概念. 2.主要概念 2.1 NameNode(NN): HDFS系统核心组件,负责分布式文件系统的名字空间管理.I ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
- Hadoop的HDFS和MapReduce的安装(三台伪分布式集群)
一.创建虚拟机 1.从网上下载一个Centos6.X的镜像(http://vault.centos.org/) 2.安装一台虚拟机配置如下:cpu1个.内存1G.磁盘分配20G(看个人配置和需求,本人 ...
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
- hadoop之HDFS与MapReduce
Hadoop历史 雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. 随后在2003 ...
随机推荐
- 修改pycharm中的flask项目名遇到的坑
曾修改过自己的项目名,并在settings中的解释器也更正过来了.然后执行pip list 报错: failed to create process. 解决方法如下: 到你的项目的venv目录下的Sc ...
- Edison:FL Studio中的常用音频录制与剪辑插件
Edison是FL Studio中的一个完全集成的音频编辑和录制工具.Edison加载到效果插槽(在任何调音台音轨中),然后录制或播放该位置的音频.您可以在任意数量的混音器轨道或效果插槽中根据需要加载 ...
- Luogu P4306 JSOI2010 连通数
tarjan有向图缩点的基础应用.把原图中某点的连通数转化为反向图中"能够到达某点的个数".缩点后,每个新点的贡献等于 原dcc大小 * f[i] 其中f[i]表示(包括该点自身) ...
- J2EE基本概念
XO POJO:Plain Ordinary Java Object,简单java对象 PO:Persistant Object,持久层对象(对应数据库中一条记录) BO:Business Objec ...
- 牛客编程巅峰赛S2第4场
牛客编程巅峰赛S2第4场 牛牛摆玩偶 题目描述 牛牛有\(n(2 \leq n \leq 10^5)(2≤n≤105)\)个玩偶,牛牛打算把这n个玩偶摆在桌子上,桌子的形状的长条形的,可以看做一维数轴 ...
- WireShark抓包分析以及对TCP/IP三次握手与四次挥手的分析
WireShark抓包分析TCP/IP三次握手与四次挥手 Wireshark介绍: Wireshark(前称Ethereal)是一个网络封包分析软件.功能十分强大,是一个可以在多个操作系统平台上的开源 ...
- JZOJ8月4日提高组反思
JZOJ8月4日提高组反思 被一堆2018&2019&2020的巨佬暴打 又是愉快的爆0的一天呢 T1 看了看题 没想法 暴力走起 求个质因数呀,二分呀-- 然后就炸了 正解预处理加二 ...
- day7(vue发送短信)
1.vue发送短信逻辑 前端函数如下,js方法代码无需更改,前端代码逻辑在components\common\lab_header.vue 只需要修改components\axios_api\http ...
- 第15.19节 PyQt(Python+Qt)入门学习:自定义信号与槽连接
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.引言 本文利用中介绍了PyQt中的信号和槽机制,除了使用PyQt组件的已有信号外,PyQt和Qt ...
- 对flask的学习
任务需求:一个登录,注册页面 任务环境:pycharm 2018 专业版,python3.7,win 10专业版 ------------------------------------------- ...