常用RDD
只作为我个人笔记,没有过多解释
Transfor
map
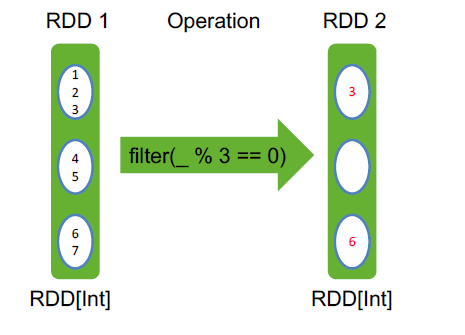
filter filter之后,依然有三个分区,第二个分区为空,但不会消失
flatMap
reduceByKey
groupByKey()
sortByKey()
val pets = sc.parallelize(
List((“cat”, 1), (“dog”, 1), (“cat”, 2))
)
pets.reduceByKey(_ + _) // => {(cat, 3), (dog, 1)}
pets.groupByKey() // => {(cat, Seq(1, 2)), (dog, Seq(1)}
pets.sortByKey() // => {(cat, 1), (cat, 2), (dog, 1)}
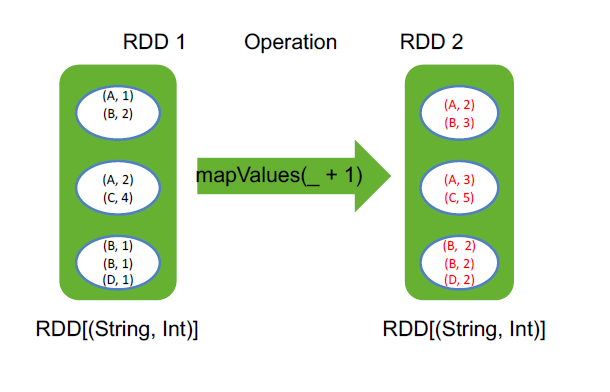
mapValues(_ + 1) mapvalues是忽略掉key,只把value进行操作
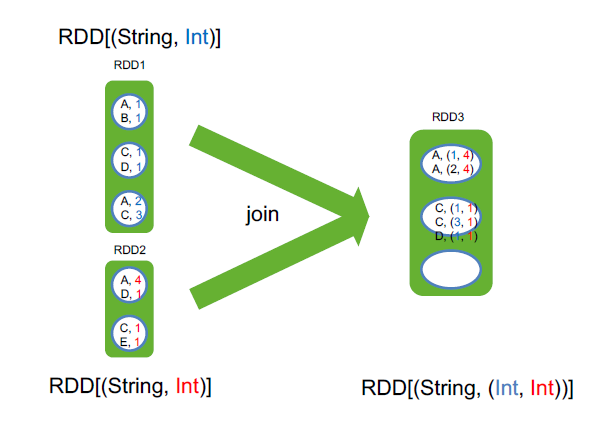
join RDD[(String, Int)].join(RDD[(String, Long)]) => RDD[(String, (Int, Long))]
join这两个rdd的value类型可以不一样,至于分区是根据hash来指定的
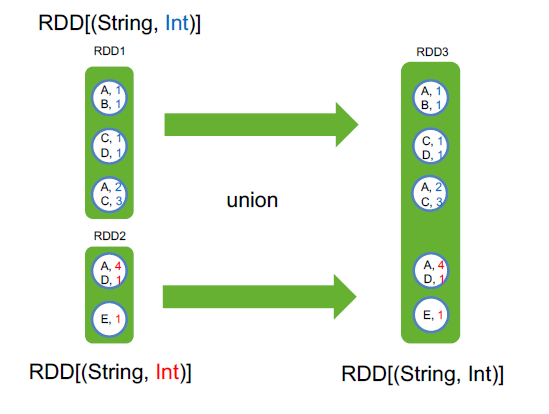
union
cogroup

用 cogroup 实现 join


sample() 从数据集中采样
cartesian() 求笛卡尔积
pipe() 传入一个外部程序
coalesce(口莱斯) 合并一个RDD的分区
rdd4 = rdd1 ++ rdd2 ++ rdd3
rdd4.coalesce(3)
rdd4.coalesce(3,true)
repartition 合并分区 rdd3.repartition(10)
并不是真的将分区合并,而是让一个task处理多个分区,如1k、10k、100k、1m、10m这五种文件,一共10w个,在hdfs上会有10w个block,取数据的时候会有10w个分区,同样有10w个task,这并不合适,如果能将这些分区合并,比如有10个task,每个task读1w个文件,速度会快很多,这个时候,有两种合并方式,coalesce和repartition
coalesce优点是简单粗暴,合并分区速度很快,缺点是很可能每个task所处理的数据不均匀。如果文件天生是比较均匀的,那coalesce合适
repartition优点是合并很均匀,用的是归并排序,缺点是计算开销比较大
举例,repartition合并的方法,10w个文件如何均匀的分成3个分区?
将每个文件均匀分成3分份,然后每一个分区从每个文件中拿一份
zip 将两个RDD的元素一一映射,合在一起
Action
collect()
take(2)
count()
reduce
foreach(println)
常用RDD的更多相关文章
- 08、Spark常用RDD变换
08.Spark常用RDD变换 8.1 概述 Spark RDD内部提供了很多变换操作,可以使用对数据的各种处理.同时,针对KV类型的操作,对应的方法封装在PairRDDFunctions trait ...
- 04、常用RDD操作整理
常用Transformation 注:某些函数只有PairRDD只有,而普通的RDD则没有,比如gropuByKey.reduceByKey.sortByKey.join.cogroup等函数要根据K ...
- Spark常用RDD操作总结
aggregate 函数原型:aggregate(zeroValue, seqOp, combOp) seqOp相当于Map combOp相当于Reduce zeroValue是seqOp每一个par ...
- 033 Java Spark的编程
1.Java SparkCore编程 入口是:JavaSparkContext 基本的RDD是:JavaRDD 其他常用RDD: JavaPairRDD JavaRDD和JavaPairRDD转换: ...
- Spark常用函数讲解之键值RDD转换
摘要: RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集RDD有两种操作算子: Trans ...
- Spark学习之路(四)—— RDD常用算子详解
一.Transformation spark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 fu ...
- Spark 系列(四)—— RDD常用算子详解
一.Transformation spark 常用的 Transformation 算子如下表: Transformation 算子 Meaning(含义) map(func) 对原 RDD 中每个元 ...
- spark学习(10)-RDD的介绍和常用算子
RDD(弹性分布式数据集,里面并不存储真正要计算的数据,你对RDD的操作,他会在Driver端转换成Task,下发到Executor计算分散在多台集群上的数据) RDD是一个代理,你对代理进行操作,他 ...
- sparkRDD:第3节 RDD常用的算子操作
4. RDD编程API 4.1 RDD的算子分类 Transformation(转换):根据数据集创建一个新的数据集,计算后返回一个新RDD:例如:一个rdd进行map操作后生了一个新的rd ...
随机推荐
- Struts2_day01--课程安排_Struts2概述_入门
Struts2_day01 Struts2课程安排 今天内容 Struts2概述 Struts2框架入门 导入源文件 Struts2执行过程 查看源代码 Struts2的核心配置文件 标签packag ...
- C语言while语句
在C语言中,共有三大常用的程序结构: 顺序结构:代码从前往后执行,没有任何“拐弯抹角”: 选择结构:也叫分支结构,重点要掌握 if else.switch 以及条件运算符: 循环结构:重复执行同一段代 ...
- UIImage 裁剪图片和等比列缩放图片
本文转载至 http://blog.csdn.net/cuiweijie3/article/details/9514293 转自 http://www.tedz.me/ios/uiimage-crop ...
- JSP小例子——实现用户登录小例子(不涉及DB操作)
实现用户登录小例子用户名和密码都为"admin",登陆成功使用服务器内部转发到login_success.jsp页面,并且提示登陆成功的用户名.如果登陆失败则请求重定向到login ...
- gulp 报错'wacth' errord
gulp.wacth(...).watch is not a function 如图: 检查了gulpfile.js文件中的wacth事件:发现这样的写法出错: gulp.task('watch', ...
- 应急分析异常通信的小思路和自己写的小工具(查询CNAME和A记录)
一.背景: 在很多时候,应急会发现.卧槽,异常连接,只有一个域名或者IP. 怎么办?上防火墙看记录,查域名对应的记录累成狗,自己把之前的代码改了改,写了个小工具,一条命令查询DNS相关记录,也可以指定 ...
- ios UITableView中Cell重用机制导致内容重复解决方法
UITableView继承自UIScrollview,是苹果为我们封装好的一个基于scroll的控件.上面主要是一个个的 UITableViewCell,可以让UITableViewCell响应一些点 ...
- CSS文本对齐text-align详解
1.语法 text-align具体参数如下: 语法:text-align : left | right | center | justify 说明:设定元素内文本的水平对齐方式. 参数:left : ...
- 20190401-记录一次bug ConstraintViolationException
org.hibernate.exception.ConstraintViolationException 违反唯一约束条件 导致这个问题的原因有很多种. 在查询数据库时发生了这样的错误,一般这样的问题 ...
- C#-using用法详解
转自:http://blog.csdn.net/wanderocn/article/details/6659811 using 关键字有两个主要用途: (一).作为指令,用于为命名空间创建别名或导入其 ...