Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记
1.环境介绍
(1)操作系统RHEL6.2-64
(2)两个节点:spark1(192.168.232.147),spark2(192.168.232.152)
(3)两个节点上都装好了Hadoop 2.2集群
2.安装Zookeeper
(1)下载Zookeeper:http://apache.claz.org/zookeeper ... keeper-3.4.5.tar.gz
(2)解压到/root/install/目录下
(3)创建两个目录,一个是数据目录,一个日志目录

(4)配置:进到conf目录下,把zoo_sample.cfg修改成zoo.cfg(这一步是必须的,否则zookeeper不认识zoo_sample.cfg),并添加如下内容
- dataDir=/root/install/zookeeper-3.4.5/data
- dataLogDir=/root/install/zookeeper-3.4.5/logs
- server.1=spark1:2888:3888
- server.2=spark2:2888:3888
复制代码
(5)在/root/install/zookeeper-3.4.5/data目录下创建myid文件,并在里面写1
- cd /root/install/zookeeper-3.4.5/data
- echo 1>myid
复制代码
(6)把/root/install/zookeeper-3.4.5整个目录复制到其他节点
- scp -r /root/install/zookeeper-3.4.5 root@spark2:/root/install/
复制代码
(7)登录到spark2节点,修改myid文件里的值,将其修改为2
- cd /root/install/zookeeper-3.4.5/data
- echo 2>myid
复制代码
(8)在spark1,spark2两个节点上分别启动zookeeper
- cd /root/install/zookeeper-3.4.5
- bin/zkServer.sh start
复制代码
(9)查看进程进否成在
- [root@spark2 zookeeper-3.4.5]# bin/zkServer.sh start
- JMX enabled by default
- Using config: /root/install/zookeeper-3.4.5/bin/../conf/zoo.cfg
- Starting zookeeper ... STARTED
- [root@spark2 zookeeper-3.4.5]# jps
- 2490 Jps
- 2479 QuorumPeerMain
复制代码
3.配置Spark的HA
(1)进到spark的配置目录,在spark-env.sh修改如下
- export
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=spark1:2181,spark2:2181
-Dspark.deploy.zookeeper.dir=/spark" - export JAVA_HOME=/root/install/jdk1.7.0_21
- #export SPARK_MASTER_IP=spark1
- #export SPARK_MASTER_PORT=7077
- export SPARK_WORKER_CORES=1
- export SPARK_WORKER_INSTANCES=1
- export SPARK_WORKER_MEMORY=1g
复制代码
(2)把这个配置文件分发到各个节点上去
- scp spark-env.sh root@spark2:/root/install/spark-1.0/conf/
复制代码
(3)启动spark集群
- [root@spark1 spark-1.0]# sbin/start-all.sh
- starting org.apache.spark.deploy.master.Master, logging to
/root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-spark1.out - spark1: starting org.apache.spark.deploy.worker.Worker, logging
to
/root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark1.out - spark2: starting org.apache.spark.deploy.worker.Worker, logging
to
/root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.worker.Worker-1-spark2.out
复制代码
(4)进到spark2(192.168.232.152)节点,把start-master.sh 启动,当spark1(192.168.232.147)挂掉时,spark2顶替当master
- [root@spark2 spark-1.0]# sbin/start-master.sh
- starting org.apache.spark.deploy.master.Master, logging to
/root/install/spark-1.0/sbin/../logs/spark-root-org.apache.spark.deploy.master.Master-1-spark2.out
复制代码
(5)查看spark1和spark2上运行的哪些进程
- [root@spark1 spark-1.0]# jps
- 5797 Worker
- 5676 Master
- 6287 Jps
- 2602 QuorumPeerMain
- [root@spark2 spark-1.0]# jps
- 2479 QuorumPeerMain
- 5750 Jps
- 5534 Worker
- 5635 Master
复制代码
4.测试HA是否生效
(1)先查看一下两个节点的运行情况,现在spark1运行了master,spark2是待命状态
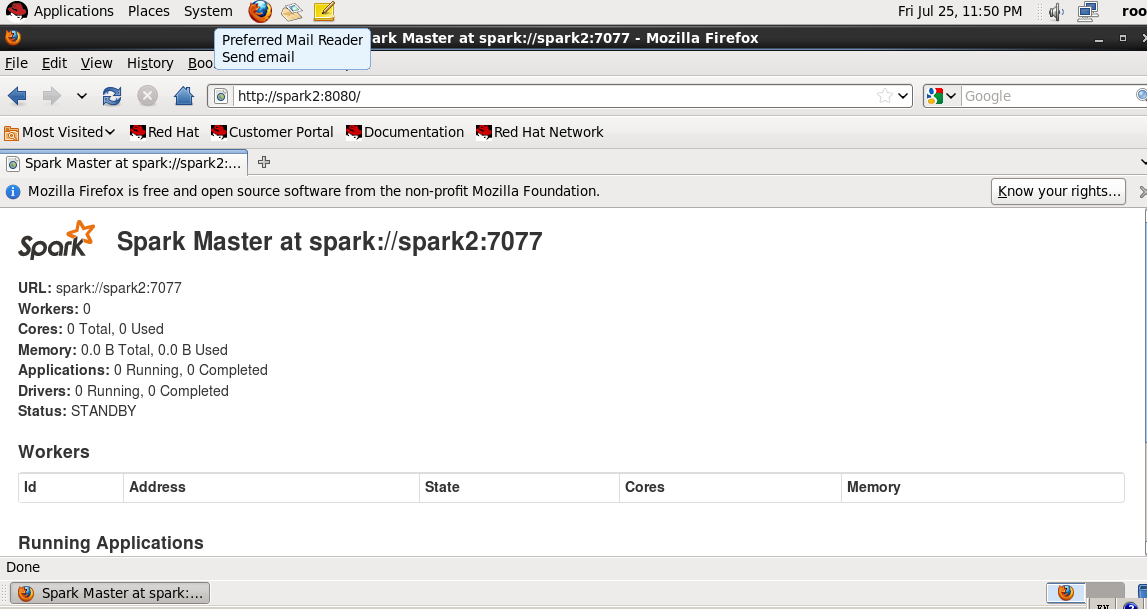
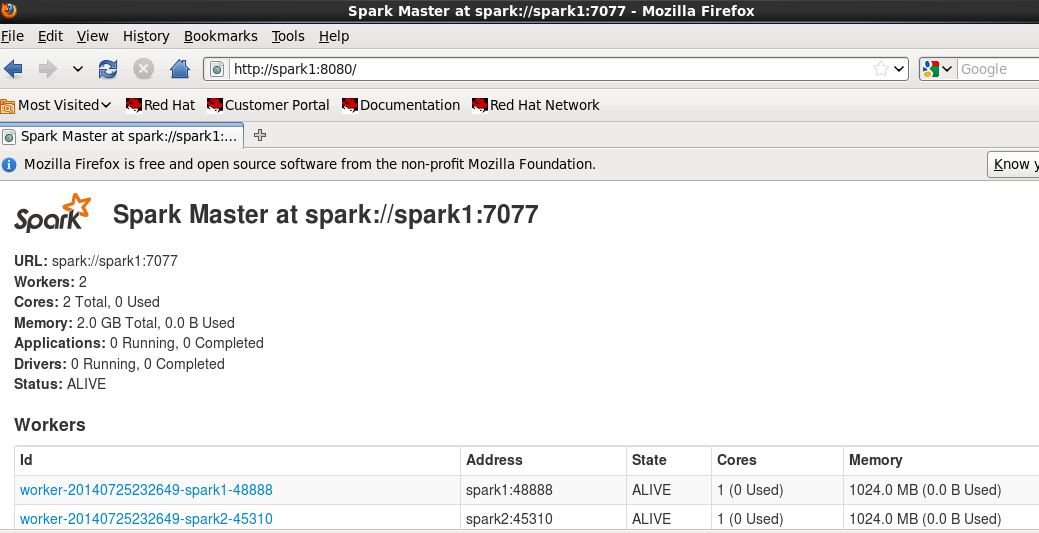
(2)在spark1上把master服务停掉
- [root@spark1 spark-1.0]# sbin/stop-master.sh
- stopping org.apache.spark.deploy.master.Master
- [root@spark1 spark-1.0]# jps
- 5797 Worker
- 6373 Jps
- 2602 QuorumPeerMain
复制代码
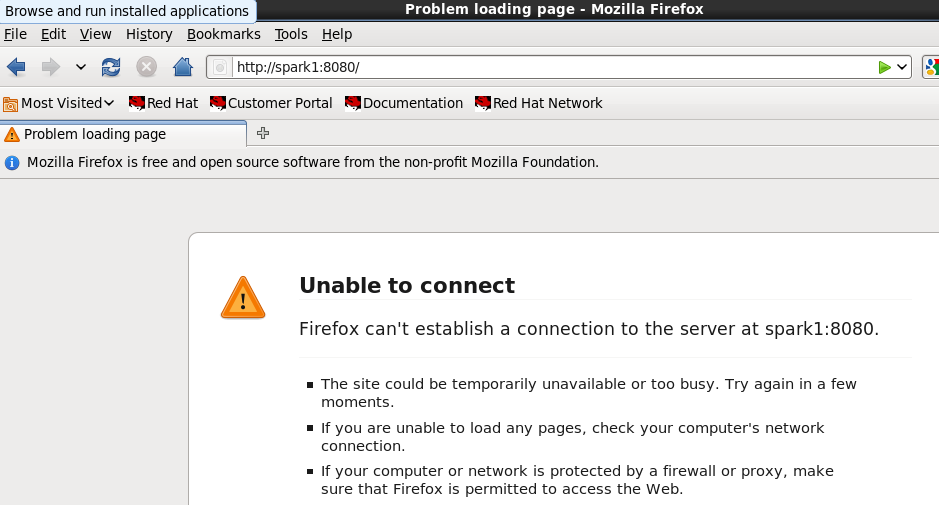
(3)用浏览器访问master的8080端口,看是否还活着。以下可以看出,master已经挂掉
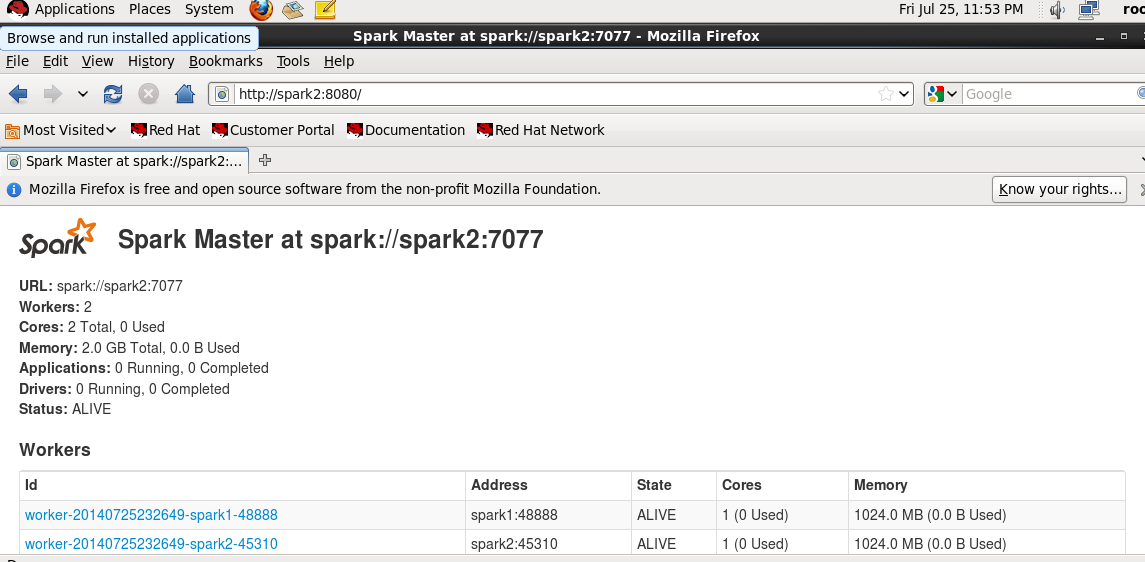
(4)再用浏览器访问查看spark2的状态,从下图看出,spark2已经被切换当master了
Spark集群基于Zookeeper的HA搭建部署笔记(转)的更多相关文章
- Azure上搭建ActiveMQ集群-基于ZooKeeper配置ActiveMQ高可用性集群
ActiveMQ从5.9.0版本开始,集群实现方式取消了传统的Master-Slave方式,增加了基于ZooKeeper+LevelDB的实现方式. 本文主要介绍了在Windows环境下配置基于Zoo ...
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
转自:http://www.2cto.com/os/201605/510489.html hadoop1的核心组成是两部分,即HDFS和MapReduce.在hadoop2中变为HDFS和Yarn.新 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 【Spark-core学习之三】 Spark集群搭建 & spark-shell & Master HA
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- VMWare9下基于Ubuntu12.10搭建Hadoop-1.2.1集群—整合Zookeeper和Hbase
VMWare9下基于Ubuntu12.10搭建Hadoop-1.2.1集群-整合Zookeeper和Hbase 这篇是接着上一篇hadoop集群搭建进行的.在hadoop-1.2.1基础之上安装zoo ...
- spark集群搭建(三台虚拟机)——zookeeper集群搭建(3)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- Spark入门:第2节 Spark集群安装:1 - 3;第3节 Spark HA高可用部署:1 - 2
三. Spark集群安装 3.1 下载spark安装包 下载地址spark官网:http://spark.apache.org/downloads.html 这里我们使用 spark-2.1.3-bi ...
- spark集群搭建整理之解决亿级人群标签问题
最近在做一个人群标签的项目,也就是根据客户的一些交易行为自动给客户打标签,而这些标签更有利于我们做商品推荐,目前打上标签的数据已达5亿+, 用户量大概1亿+,项目需求就是根据各种组合条件寻找标签和人群 ...
随机推荐
- Scrapy 增加随机请求头 user_agent
原文: 为什么要增加随机请求头:更好地伪装浏览器,防止被 Ban. 如何在每次请求时,更换不同的 user_agent,Scrapy 使用 Middleware 即可 Spider 中间件 (Midd ...
- Validating a Model
- 如何使用Inno Setup Compiler制作安装软件包
工具/原料 Inno Setup Compiler汉化版软件 方法/步骤 启动Inno Setup Compiler汉化版软件. 选择创建新的空白脚本文件,按确定. 然后按下一步. ...
- bzoj 1452 二维树状数组
#include<bits/stdc++.h> #define LL long long #define fi first #define se second #define mk mak ...
- Windows 8.1 操作系统常用快捷键
安装了 windows 8.1 有一段时间了,刚使用时有点儿不太习惯,后面知道了一些常用快捷键后,使用起来习惯多了.下面是一些常用的 Windows 8.1 快捷键: Ctrl + Tab: 访问所有 ...
- HDU 6024 Building Shops
$dp$. $dp[i]$表示到$i$位置,且$i$位置建立了的最小花费,那么$dp[i] = min(dp[k]+cost[i+1][k-1])$,$k$是上一个建的位置.最后枚举$dp[i]$,加 ...
- pfring破解DNA限制
最近因工作需要,对pf_ring进行反调试.官方下载的pf_ring转发数据包的过程中,对程序做了五分钟的限制.那么如何突破此限制.此篇博客记录一下过程,已备后用. 下载源码后进行编译,此处我们利用源 ...
- brpc初探
因为最近在看一个内部开源代码,看到了braft.braft又依赖于brpc.于是就看了相关的文档,打算接下来试一把. 这里引用下gejun大佬在知乎上的回答(https://www.zhihu.com ...
- Vue 2.0学习(六)内置指令
基本指令 1.v-cloak v-cloak不需要表达式,它会在Vue实例结束编译时从绑定的HTML元素上移除,经常和CSS的display:none配合使用. <div id="ap ...
- Android消息机制——Handler
/**android的消息处理有三个核心类:Looper,Handler和Message.其实还有一个MessageQueue(消息队列), * 但是MessageQueue被封装到Looper里 ...